1. 希姆计算STC_DDK使用说明
1.1. 版本历史
| 文档版本 | 对应产品版本 | 作者 | 日期 | 描述 |
|---|---|---|---|---|
| V1.2.0 | STCRP V1.5.0 | 希姆计算 | 2023-07-31 | 新增支持动态shape模型和含有自定义算子的模型。extract_sub_graphs接口新增input_shapes参数。文档架构调整和编辑优化。整合希姆计算ScheduleViewer使用说明文档内容至本篇。 |
| V1.1.1 | STCRP V1.4.0 | 希姆计算 | 2023-05-17 | 新增model.json中的inputs项存在空值时的解决方式描述。新增在Centos 7和Debian 9系统下使用DDK时,urllib3版本要低于urllib3 2.0的使用限制。 |
| V1.1.0 | STCRP V1.4.0 | 希姆计算 | 2023-03-30 | 解决在CentOS、麒麟V10和UOS V20中DDK ldconfig默认不包含/usr/local/lib的问题。编辑优化。 |
| V1.0.0 | STCRP V1.3.0 | 希姆计算 | 2023-01-20 | 初始版本。 |
1.2. STC_DDK介绍
STC_DDK是希姆计算提供的模型编译和部署工具。受模型实现框架、计算图结构等因素的影响,将模型部署到硬件上执行推理时,一般需要经过编译前预优化、编译时优化、运行时优化的过程。为规范和简化模型部署操作,希姆计算基于TensorTurbo开发了STC_DDK,覆盖整个部署流程,并通过简洁的命令和接口提供操作能力。
1.2.1. 架构
STC_DDK主要包括以下模块:
stc_aic:转换模型格式、加载模型、拆分子图、编译子图、可视化查看图调度效果。
stc_aie:执行推理、获取推理性能。
1.2.2. 功能
STC_DDK的主要功能包括:
编译模型:将模型编译为希姆计算硬件上的可执行文件,支持命令行形式、Python代码形式。
执行推理:执行编译得到的可执行文件,支持Python代码形式和C代码形式。
获取性能指标:获取latency、throughput指标。
可视化查看:解析编译过程中转储的Relay文件,方便可视化查看计算图结构和节点属性。
STC_DDK支持部署基于TensorFlow、PyTorch、PaddlePaddle等框架训练调优的标准框架模型,并在AI推理计算加速卡产品STCP920上执行推理。
说明:部署标准框架模型时,STC_DDK会将模型格式转换为ONNX,因此在编译阶段需要依赖特定的框架版本,但执行推理时则没有此类限制。编译阶段的框架版本要求,请参见使用STC_DDK编译模型 > 框架版本章节。
其中,在编译模型时会完成以下操作:
自动转换模型格式。
加载转换得到的文件。
拆分并编译计算图。规则如下:
| 模型情况 | 拆分和编译规则 |
|---|---|
| 模型全部适合在NPU上运行 | 拆分为在NPU上执行的子图。转储子图信息,得到model.json文件。编译所有子图,得到stcobj文件。 |
| 模型存在不合适在NPU上运行的部分 | 拆分为在CPU以及NPU上执行的子图。转储子图信息,得到model.json文件。编译所有子图,得到onnx+stcobj文件或者pb+stcobj文件文件。 |
说明:pb或onnx文件供stc_aie在CPU上执行,stcobj文件供stc_aie在NPU上执行。
执行推理时会完成以下操作:
解析编译得到的文件(包括model.json、stcobj等),生成DAG。
申请所需内存资源,并将其与DAG绑定,构建模型执行器。
模型执行器构建完成后,可对模型进行前向推理预测和Benchmark性能测试。
前向推理预测:使用模型执行器对指定输入数据进行前向计算(Forward Propagation),获取模型预测结果。
Benchmark性能测试:根据业务场景指定线程数量和数据量,随机生成输入数据并模拟多线程部署场景,以测试Benchmark数据。
1.2.3. 优势
通用性:适配主流框架。
易用性:覆盖整个部署流程,并提供简洁的操作接口。
高性能:模型转换、编译时、运行时的优化,在希姆计算硬件上获取最优的推理性能。
1.2.4. 限制
在AMD机器中,仅支持在采用Zen4微架构的机器上使用STC_DDK。
说明:STC_DDK依赖AVX512指令集,而AMD Zen4以前的微架构不支持AVX512指令集。
setuptools的版本不低于setuptools 62.6。
在Centos 7和Debian 9系统下使用DDK时,需确保urllib3的版本要低于2.0。
1.3. 安装STC_DDK
1.3.1. 前提条件
联系希姆计算销售人员获取STC_DDK安装包和libstc_runtime-1.2.0.tar.gz。
说明:libstc_runtime-1.2.0.tar.gz包含了头文件stc_c_api.h和使用C方式编译时链接动态库libstc_runtime.so文件,在使用C方式进行推理计算时需用到这些文件。
已安装TensorTurbo,且版本不低于TensorTurbo 1.12。安装TensorTurbo的详细步骤,请参见*希姆计算异构环境安装指南*。
已安装Python 3.7。
已安装Netron。如果本地未安装Netron,请访问Netron完成下载安装。
1.3.2. 安装步骤
复制STC_DDK安装包和libstc_runtime-1.2.0.tar.gz文件到本地。STC_DDK安装包的命名格式示例:
stc_ddk-{stc_ddk version}-py{Python version}-{OS version}.whl。在安装包所在目录,执行以下命令安装STC_DDK。以安装包名称为stc_ddk-1.2.0-cp37-cp37m-linux_x86_64.whl为例:
说明:安装whl文件时会通过requirement安装指定版本的TensorFlow等模块,以满足编译阶段的框架版本要求。如果您的环境中尚未安装这些模块,请确保可以联网安装。编译阶段的框架版本要求,请参见使用STC_DDK编译模型 > 框架版本章节。
$ pip3 install stc_ddk-1.2.0-cp37-cp37m-linux_x86_64.whl
按需选择一种方式安装stc_aie。
解压libstc_runtime-1.2.0.tar.gz至/usr/local目录,并配置链接器。
$ sudo tar -C /usr/local -xzf libstc_runtime-1.2.0.tar.gz #如果在麒麟V10、CentOS和UOS V20中,,需执行此命令解决编译程序时报找不到动态库的问题,在其他操作系统中可跳过此命令。 $ echo "/usr/local/lib" | sudo tee /etc/ld.so.conf.d/libstc_runtime.conf $ sudo ldconfig
解压libstc_runtime-1.2.0.tar.gz至其他目录,以目录/usr/local/ddk/为例,并手动配置环境变量。
$ sudo mkdir -p /usr/local/ddk $ sudo tar -C /usr/local/ddk/ -xzf libstc_runtime-1.2.0.tar.gz $ export LIBRARY_PATH=$LIBRARY_PATH:/usr/local/ddk/lib $ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/ddk/lib
1.4. 使用STC_DDK编译模型
STC_DDK支持通过命令行形式和Python代码形式编译模型。
1.4.1. 框架版本
STC_DDK编译模型时会将模型格式自动转换为ONNX或TF Frozen pb,在编译阶段需要依赖特定的框架版本,请确保环境满足以下要求:
TensorFlow 1.15版本。
PyTorch 1.12.1版本。
1.4.2. 编译规则
STC_DDK编译模型时会自动转换模型格式,转换模型格式的规则如下:
无需转换:原始模型的格式为ONNX、TF 1.0 saved_model、TF Frozen pb。
转为ONNX:原始模型为的格式为PyTorch、TF 2.0 saved_model、TF Check Point、PaddlePaddle、Relay IR。
转为TF Frozen pb或ONNX:原始格式的格式为TF Keras。
1.4.3. 命令行形式
1.4.3.1. 执行步骤
执行stc_ddk.stc_aic命令即可,按需指定参数。命令示例如下:
stc_ddk.stc_aic --model open_resnet50-torch-fp32.onnx
--input_names input_1
--input_shapes [16,3,224,224]
示例中的参数含义如下:
原始模型文件为当前目录下的open_resnet50-torch-fp32.onnx
模型输入的变量名称为input_1
模型输入的shape为[16,3,224,224]
1.4.3.2. 命令说明
stc_ddk.stc_aic命令定义:
stc_ddk.stc_aic
--model model_file
--input_names X:0,Y:0
--input_shapes [256,2],[128,2]
--input_dtypes INT32,FLOAT32
--opset 13
--output_names output:0
--output_shapes [256,2]
--output_dtypes INT32,
--outdir model
--to_onnx True
--debug
--config ./tb_config.json
--signature serving_default
--custom_op MultiplyByOne
--custom_op_lib ./mul.so
stc_ddk.stc_aic命令支持的参数如下表所示:
| 参数 | 说明 | 是否必选 | 示例 |
|---|---|---|---|
| model | 模型文件路径。 | 是 | tmp/bert_torch/bert_fp32.pt |
| input_names | 模型输入项名称。模型为动态shape或进行模型转换时需要传递内容。 | 否 | input_ids.1,attention_mask.1,input.1 |
| input_shapes | 模型输入项shape。默认为None。如果模型的输入shape是动态的,或者需要进行模型转换时需要设置该字段,设置格式为[shape1,shape2......]。 | 否 | 非动态shape: [4,384],[4,384],[4,384]动态shape: [[4,384],[4,256]],[[4,384],[4,256]],[[4,384],[4,256]] |
| input_dtypes | 模型输入项数据类型,进行模型转换时需要设置该字段。 | 否 | INT32,INT32,INT32 |
| opset | opset版本,默认为opset 13,只在输入模型为PyTorch模型时使用。 | 否 | 13 |
| output_names | 模型输出项名称,进行模型转换时需设置该字段。 | 否 | Identity:0 |
| output_shapes | 模型输出项shape,需要进行模型转换时需设置该字段。 | 否 | [256,2] |
| output_dtypes | 模型输出项数据类型。 | 否 | INT32 |
| outdir | 拆图编译结果存放文件夹。 | 否 | model |
| to_onnx | 是否将模型转换为ONNX格式。默认为False,设置为False时,不会进行模型转换。设置为True时,将模型转换为ONNX格式。 | 否 | --to_onnx |
| debug | 指定该选项时,会开启debug模式,保存拆图过程中产生的临时文件。 | 否 | --debug |
| config | config项文件的路径是指存放配置文件的路径。在config项文件中,您可以添加ConvertLayout项和编译config项。ConvertLayout项用于将模型输入的数据格式转换成TensorTurbo可编译的NHWC、HWIO或HWOI格式。如果模型输入的数据格式不满足要求,例如NCHW格式,您可以进行配置该项。模型的数据格式满足要求后,如果您需要调试模型、改善模型的精度或性能,可添加相应的编译config项。 | 否 | ./tb_config.json |
| signature | TF SavedModel类型模型属性,默认为serve,可传入新的signature。 | 否 | serving_default |
| custom_op | 如果模型中含有自定义算子,需要传入自定义算子type。 | 否 | MultiplyByOne |
| custom_op_lib | 如果模型中含有自定义算子,需传入该自定义算子所需的自定义算子依赖库.so文件的路径。 | 否 | ./mul.so |
tb_config.json的内容需自行定义,示例如下:
{
"ConvertLayout": {
#当不指定配置项时,stc_aic会默认使用以下三个ConvertLayout项。
"nn.conv2d": ["NHWC", "HWIO"],
"nn.max_pool2d": ["NHWC", "HWOI"],
"nn.global_avg_pool2d": ["NHWC", "HWOI"],
#添加的ConvertLayout配置项
"nn.conv2d_transpose": ["NHWC", "HWOI"],
},
#模型编译指定的编译config项
"tb.expand_multi_axis_reduce": true
}
1.4.4. Python代码形式
1.4.4.1. 执行步骤
说明:Python接口定义请参见接口说明章节。
编写Python脚本,调用STC_DDK的Python编译接口编译模型。
执行Python脚本。
1.4.4.2. Python脚本示例
非动态shape模型
from stc_ddk import stc_aic config = { "filename": "open_resnet50-torch-fp32.onnx", } model = stc_aic.load_model(config) _, sub_graphs = stc_aic.extract_sub_graphs(model) stc_aic.dump_json(model, sub_graphs, "open_resnet50-torch-fp32") stc_aic.compile_graph(sub_graphs)
动态shape模型
from stc_ddk import stc_aic config = { "filename": "open_resnet50-torch-fp32.onnx", } model = stc_aic.load_model(config) #输入动态shape input_shapes = [{"input.1": [16, 3, 224, 224]}, {"input.1": [16, 3, 216, 216]}] _, sub_graphs = stc_aic.extract_sub_graphs(model, input_shapes ) stc_aic.dump_json(model, sub_graphs, "open_resnet50-torch-fp32") stc_aic.compile_graph(sub_graphs)
示例中的代码逻辑如下:
配置config,指定:
原始模型文件,例如open_resnet50-torch-fp32.onnx。
模型输入的变量名称,例如input.1。
模型输入的shape,例如[16,3,224,224]。
调用
stc_aic.load_model加载模型。调用
stc_aic.extract_sub_graphs拆分子图。调用
stc_aic.dump_json将拆图结果保存为model.json文件。调用
stc_aic.compile_graph启动编译。
1.4.5. 编译结果示例
编译完成后,自动生成以模型文件名命名的文件夹。包含的文件示例如下:
model.json:拆图结果。
torch_jit_export.cc:模型的中间.cc文件。
torch_jit_export.stcobj:模型的可执行文件。
1.4.6. 问题排查
如果model.json文件中的inputs项存在空值,将会导致推理失败。您可以使用onnx-simplifier预优化模型文件从而避免此类情况,步骤如下:
如果原始文件不是ONNX格式,需要将原始文件转换为ONNX格式。
使用onnx-simplifier预优化ONNX格式的模型,详细方法请参见onnx-simplifier项目的说明。
使用STC_DDK编译优化后的模型。
1.5. 使用STC_DDK执行推理
STC_DDK支持通过Python代码形式和C代码形式执行推理。
1.5.1. 框架版本
执行推理时不依赖特定的框架版本,但如果您需要在运行环境中安装AI框架,建议使用已完成兼容性验证的版本。在其他版本上可以运行,但并不能始终得到保障。建议版本如下:
TensorFlow 1.15版本
PyTorch 1.9.1版本
1.5.2. Python代码形式
1.5.2.1. 执行步骤
说明:Python接口定义请参见接口说明章节。
编写Python脚本,调用STC_DDK的Python部署接口部署模型。
执行Python脚本。
1.5.2.2. Python脚本示例
import pdb
import sys
import numpy as np
from stc_ddk import stc_aie
def creat_feeds(inputs):
feeds = []
for key, value in inputs.items():
shape = value[0]
dtype = value[1]
data = np.random.randint(-16, 15, shape).astype(dtype.lower())
print(key, data)
tensor = stc_aie.STCTensor(key, data)
feeds.append(tensor)
return feeds
if __name__ == "__main__":
path = "/home/ubuntu/open_resnet50-torch-fp32"
args = sys.argv
path = args[1]
print(path)
model = stc_aie.STCGraph(path)
model.dump_graph()
inputs = model.get_inputs()
print(inputs)
print("*" * 100)
outputs = model.get_output_names()
print(outputs)
feeds = creat_feeds(inputs)
exec = stc_aie.STCGraphExec(model)
outs = exec.run(feeds)
print("Run Done.....")
for out in outs:
print("shape: ", out.shape, ", dtype: ", out.dtype, ", max: ", out.max(), ", min: ", out.min())
示例中的代码逻辑如下:
导入stc_aie。
传入model.json以及stcobj文件所在的路径。
说明:可直接传入通过STC_AIC得到的模型文件夹路径。
调用
stc_aie.STCGraph创建并初始化计算图实例。调用计算图实例的
dump_graph方法,dump模型结构和节点信息。调用
creat_feeds创建数据实例,并根据需要指定name、dtype、shape等信息。调用
stc_aie.STCGraphExec创建执行器实例,并根据STCGraph初始化。调用执行器实例的
run方法,并传入数据实例,进行前向推理计算,并输出推理结果。
1.5.2.3. 推理结果示例
推理结果部分示例如下:
/home/test/stc_ddk/open_resnet50-torch-fp32
================ STC Graph Dump ================
NAME: graph
Node Idx: 0
Name : torch_jit_export
Source : /home/test/stc_ddk/open_resnet50-torch-fp32/./torch_jit_export.stcobj
SRC_TYPE : STC
INPUTS :
Idx: 0, Name: input_1, Shape: [16, 3, 224, 224], DType: FLOAT32, TType: INPUT, Loc: HOST, batch_pos: 0, max: 128
OUTPUTS:
Idx: 0, Name: softmax_tensor:0, Shape: [16, 1000], DType: FLOAT32, TType: OUTPUT, Loc: HOST, batch_pos: 0, max: 128
==================================================
{'input_1': [[16, 3, 224, 224], 'FLOAT32']}
****************************************************************************************************
['softmax_tensor:0']
input_1 [[[[ 14. -15. 9. ... 5. 6. -14.]
[ -5. 9. -4. ... 5. 8. -8.]
[-11. -8. 4. ... 0. -16. -7.]
......
......
[Fri Dec 30 18:21:36 2022] [/home/test/stc_ddk/stc_aie/src/runtime/backend/node_exec_stc.hpp:34 ] <CheckInfoWithTensor> <INFO> Tensor: input_1 will do cast for diff data_type.
[Fri Dec 30 18:21:36 2022] [/home/test/stc_ddk/stc_aie/src/runtime/backend/node_exec_stc.hpp:34 ] <CheckInfoWithTensor> <INFO> Tensor: softmax_tensor:0 will do cast for diff data_type.
Run Done.....
shape: (16, 1000) , dtype: float32 , max: 38.625 , min: -27.484375
1.5.3. C代码形式
1.5.3.1. 执行步骤
说明:C接口定义请参见接口说明章节。
编写源文件,调用STC_DDK的部署接口部署模型。
使用CMake编译源文件,得到可执行文件。
注意:如果安装STC_DDK时,将libstc_runtime放到了非/usr/local的目录,使用CMake编译时需要手动在CMakeLists.txt中添加语句指定头文件所在路径。以放到了/usr/local/ddk为例,添加
target_include_directories(aie_test PRIVATE /usr/local/ddk/include)。
执行可执行文件。
1.5.3.2. C源文件示例
#include <iostream>
#include <string.h>
#include "stc_c_api.h"
using namespace std;
int main(int argc, char *argv[]) {
std::string json_file = "/home/ubuntu/open_resnet50-torch-fp32/model.json";
STC_GRAPH graph = LoadModel(json_file.c_str());
if (!graph) {
std::cout << "Load Graph Failed...\n";
return -1;
}
auto graph_exec = CreateGraphExec(graph);
if (!graph) {
std::cout << "Create GraphExec Failed...\n";
return -2;
}
int in_num = 1;
STC_TENSOR *inputs = (STC_TENSOR *)malloc(sizeof(STC_TENSOR) * in_num);
std::string in_name = "input_tensor:0";
int64_t dims[4] = {8, 224, 224, 3};
std::string c_type = "FLOAT32";
inputs[0] = CreateTensor(in_name.c_str(), dims, ret, c_type.c_str());
int out_num = 1;
STC_TENSOR *outputs = (STC_TENSOR *)malloc(sizeof(STC_TENSOR) * out_num);
const char *out_names[out_num];
out_names[0] = "softmax_tensor:0";
int res = GraphExecRun(graph_exec, out_names, inputs, in_num,
outputs, out_num);
if (0 != res) {
std::cout << "GraphExecRun Failed...\n";
return -3;
}
std::cout << "================= TEST Done.. ================= \n";
DestoryTensor(inputs[0]);
free(outputs);
free(inputs);
DestoryGraphExec(graph_exec);
ReleaseModel(graph);
return 0;
}
示例中的代码逻辑如下:
#include "stc_c_api.h"引用头文件,编译时链接动态库libstc_runtime.so。调用
LoadModel,加载模型。传入model.json以及stcobj文件所在的路径,初始化计算图实例graph。调用
CreateGraphExec,创建执行器实例graph_exec。创建模型输入数据实例,在实际做推理计算时,要输入测试数据。
指定模型输出信息。
使用模型执行器执行推理服务,返回推理结果。
推理任务完成后,释放执行模型所占用的资源,包括执行器资源以及模型资源。
1.6. 使用STC_DDK获取推理性能
STC_DDK支持通过命令行形式和Python代码形式获取推理性能。
1.6.1. 命令行形式
1.6.1.1. 执行步骤
执行stc_ddk.benchmark命令即可,按需指定参数。命令示例如下:
$ stc_ddk.benchmark -m /home/ubuntu/open_resnet50-torch-fp32 -b 8 -n 1 -t 1
******************************************
Model Path : /home/ubuntu/open_resnet50-torch-fp32
Thread Num : 1
Exec Count : 1
List Batch : [8, ]
******************************************
================ STC Graph Dump ================
NAME: graph
Node Idx: 0
Name : torch_jit_export
Source : /home/ubuntu/open_resnet50-torch-fp32/./torch_jit_export.stcobj
SRC_TYPE : STC
INPUTS :
Idx: 0, Name: input_1, Shape: [16, 3, 224, 224], DType: FLOAT32, TType: INPUT, Loc: HOST, batch_pos: 0, max: 128
OUTPUTS:
Idx: 0, Name: softmax_tensor_0, Shape: [16, 1000], DType: FLOAT32, TType: OUTPUT, Loc: HOST, batch_pos: 0, max: 128
==================================================
#### Benchmark Start...
[Fri Dec 16 16:24:09 2022] [/home/ubuntu/stc_ddk/stc_aie/src/runtime/backend/node_exec_stc.hpp:32 ] <CheckInfoWithTensor> <INFO> Tensor: input_1 will do cast for diff data_type.
[Fri Dec 16 16:24:09 2022] [/home/ubuntu/stc_ddk/stc_aie/src/runtime/backend/node_exec_stc.hpp:32 ] <CheckInfoWithTensor> <INFO> Tensor: softmax_tensor_0 will do cast for diff data_type.
THREAD: 1, per count: 1, remind: 0
#### Future Run Done.
res count: 1, min: 8464, max: 8464, total: 8464
==========================================
==========================================
Count Total : 1
Latency Min : 8464 us
Latency Max : 8464 us
Latency AVG : 8.464 ms
through_put : 118.147
==========================================
#### Benchmark Done !!!
1.6.1.2. 命令说明
stc_ddk.benchmark命令的定义如下:
$ stc_ddk.benchmark -m {model_path} -n {loop_count} -t {thread_num} -w {warm_up} -b {batch_size}
stc_ddk.benchmark命令支持的参数如下表所示:
| 参数 | 类型 | 说明 | 是否必选 | 示例 |
|---|---|---|---|---|
| m | string | 经过stc_aic编译后生成的stcobj与JSON文件所在的文件夹路径。 | 是 | /home/ubuntu/open_resnet50-torch-fp32 |
| n | INT | 指定Benchmark执行的次数,默认为100。 | 否 | 100 |
| t | INT | 指定Benchmark执行所用的线程数量,默认为1。 | 否 | 4 |
| w | INT | 指定模拟业务计算前warm_up(预热)的次数,默认为10。 | 否 | 10 |
| b | string | 指定模型的batch size,默认为1。 | 否 | 8 |
1.6.2. Python代码形式
1.6.2.1. 执行步骤
说明:Python接口定义请参见接口说明章节。
编写Python脚本,调用STC_DDK的Python部署接口部署模型。
执行Python脚本。
1.6.2.2. Python脚本示例
from stc_ddk import tools
model_dir = "/home/ubuntu/open_resnet50-torch-fp32/"
count = 100
thread = 8
warm_up = 10
batch_list = "8"
res = tools.stc_benchmark(model_dir, count, thread, warm_up, batch_list)
print(res)
示例中的代码逻辑如下:
导入tools。
传入model.json以及stcobj文件所在的路径。
设置运行参数。
调用
tools.stc_benchmark,获取推理性能。
1.7. 使用STC_DDK分析图调度效果
STC_DDK支持通过命令行形式解析图层IR文件,分析图调度效果。
1.7.1. 执行步骤
编译模型,注意修改dump图调度信息对应的config。详细的编译步骤,请参见*希姆计算TensorTurbo使用说明>config支持>用于输出调试信息章节* 。
查看dump出的IR文件。
自动图调度IR文件:生成名为auto_graphschedule的目录。
手动图调度IR文件:生成名为graphschedule的目录。
Pass粒度的IR文件:保存到dump_ir目录中,IR文件的命名格式为<pass_id>_Infertype.ir,例如第一个Pass对应的文件为00001_InferType.ir。
解析dump出的IR文件,得到JSON文件。
解析单个文件:指定文件位置。
解析目录下所有文件:指定目录位置,支持将自动图调度方案转换为手动图调度方案。
使用可视化工具加载JSON文件,查看图调度过程中计算图结构的变化。请按需选择可视化工具,例如Netron。
1.7.2. IR文件说明
图调度IR文件对应了图调度过程中的典型阶段,说明如下:
raw.ir:原始算子粒度的Relay IR。
grouped.ir:经过Group之后且以Group为粒度的Relay IR。
group_splitted.ir:经过Split / Concat之后且以被拆分的Group为粒度的Relay IR。
group_scheduled.ir:调度过后的Group级别的Relay IR,在手写图调度ScheduleInfo的时候需要用到。
dag_scheduled.ir:调度过后的Fuse Op级别的Relay IR,在排查具体问题时需要用到。
1.7.3. 解析命令说明
stc_ddk.scheduleviewer命令的定义如下:
解析单个文件:
$ stc_ddk.scheduleviewer --input {file_name} --unformat
解析目录下所有文件:
$ stc_ddk.scheduleviewer --input {folder_name} --convert --unformat
stc_ddk.scheduleviewer命令支持的参数如下表所示:
| 参数 | 说明 | 是否必选 |
|---|---|---|
| input | 待解析的单个relay文件名或存放relay文件的文件夹名。 | 是 |
| convert | 设置该参数后,可将启发式自动图调度方案转换为手动图调度方案,生成的手动图调度方案以YAML格式呈现。您可对生成的图调度方案进行分析优化后使用。注意:仅在解析目录下所有文件时可用。因为手动图调度和启发式自动图调度的实现存在差异,所以部分转换成功的启发式自动图调度方案直接使用时会出现编译失败的情况。受模型网络结构影响,当模型含有Split算子或者tuple元组时,启发式自动图调度不进行Groups的划分,grouped.ir、 group_splitted.ir、group_scheduled.ir的解析结果文件中无Groups信息,无法将启发式自动图调度转换成手动图调度方案。 | 否 |
| unformat | 解析得到的节点名和属性内容长度默认最多显示50个字符,超过50个字符以省略号(...)结尾,如果您希望取消该限制,可在解析命令后添加--unformat参数。 |
否 |
说明:
受手动图调度和启发式自动图调度的Dump功能影响,当保存的IR文件内容有误时,STC_DDK的解析功能会失效。
在多轴切分场景下,IR文件中出现多个Split算子,group_splitted.ir,group_scheduled.ir的解析会出现误差,无法与Python侧的SplitGroups配置项一致对应。
1.7.4. 可视化信息说明
1.7.4.1. 计算图结构
计算图结构的示例如下所示:
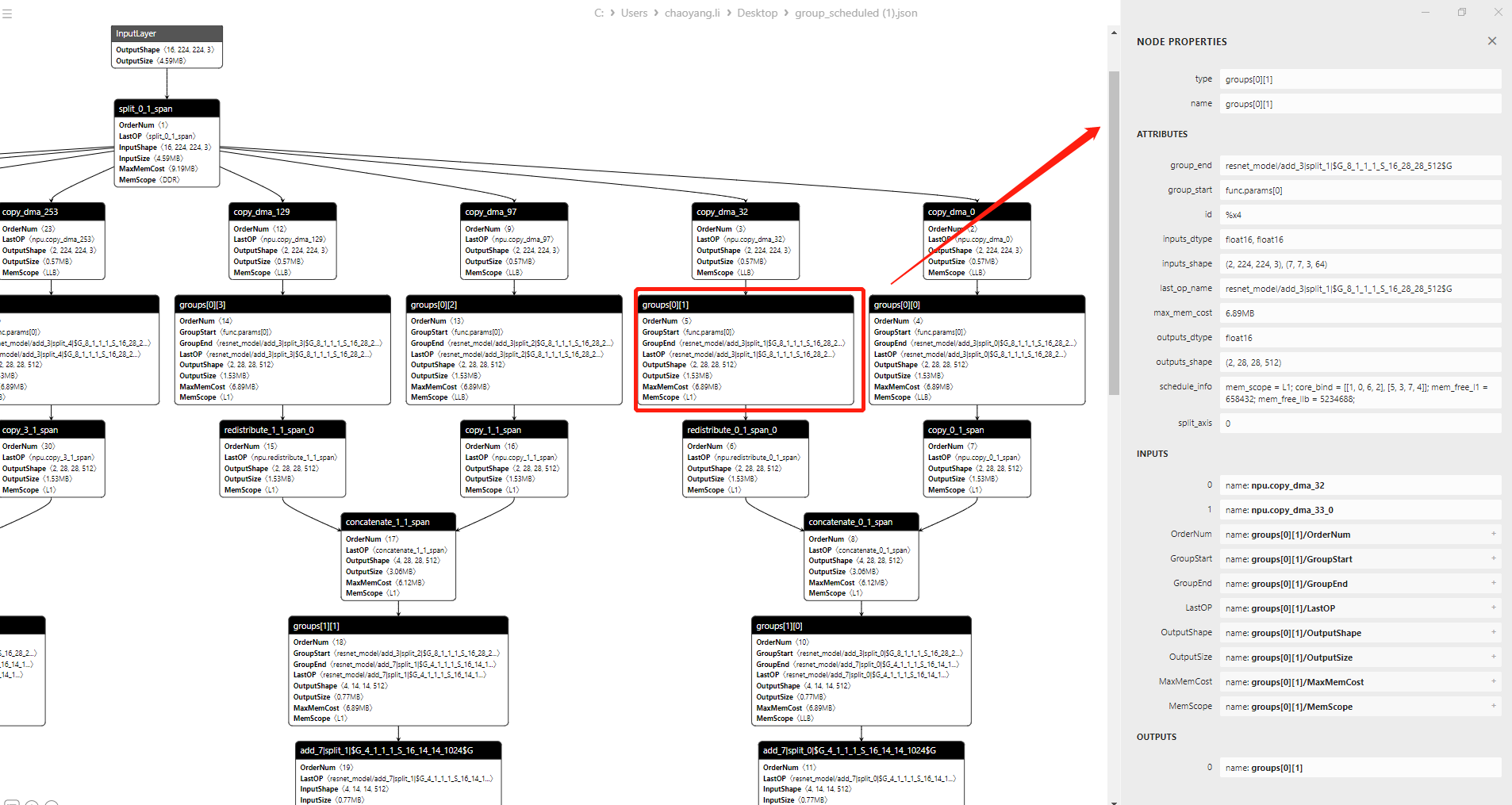
图视图中展示了主要的节点信息:
| 字段名 | 说明 |
|---|---|
| OrderNum | 节点执行顺序,Schedule后节点的OrderNum属性和实际运行顺序一致,即group_scheduled.json、dag_scheduled.json文件里的OrderNum属性与实际运行顺序是一致的。 |
| GroupStart | Group的起始节点。说明:当起始节点名过长时,节点名会部分以省略号的形式展现。完整的起始节点名,可在ATTRIBUTES模块的group_start区域查看。 |
| GroupEnd | Group的结束节点。说明:当结束节点名过长时,节点名会部分以省略号的形式展现。完整的结束节点名,可在ATTRIBUTES模块的group_end区域查看。 |
| LastOP | 节点为Fuse Op时,所包含最后一个Op的span_name。 |
| OutputShape | 节点输出的shape。 |
| OutputSize | 节点输出KB大小。 |
| MaxMemCost | Fuse Op或Group的最大内存占用大小,单位为MB。节点为Fuse Op时,值为Fuse Op的最大内存占用。节点为Group时,值为Group的最大内存占用。 |
| MemScope | Fuse Op或Group的ScheduleInfo信息中的MemScope。 |
1.7.4.2. 属性列表
在图视图中单击任一节点,会打开该节点的属性列表。示例如下所示:
列表视图中展示了节点所有的属性信息:
NODE PROPERTIES
| 字段名 | 说明 |
|---|---|
| type | 节点显示名称:节点为Fuse Op时,为Op type的拼接,并加上index。节点为Group时,为Group节点名称。 |
| name | 节点全称:节点为Fuse Op时,为包含Op的span_name的拼接。节点为Group时,为Group节点显示名称。 |
ATTRIBUTES
| 字段名 | 说明 |
|---|---|
| group_end | Group的结束节点,在这里显示的是完整的结束节点名。 |
| group_start | Group的起始节点,在这里显示的是完整的起始节点名。 |
| id | 对应IR文件中的id。 |
| inputs_dtype | 节点输入的dtype。 |
| inputs_shape | 节点输入的shape。 |
| last_op_name | 节点为Fuse Op时,所包含最后一个Op的span_name。 |
| max_mem_cost | Fuse Op或Group的最大内存占用大小,单位为MB。节点为Fuse Op时,值为Fuse Op的最大内存占用。节点为Group时,值为Group的最大内存占用。 |
| outputs_dtype | 节点输出的dtype。 |
| outputs_shape | 节点输出的shape。 |
| op | 节点所包含的op,以op_index的形式呈现包含的算子,例如op0。 |
| schedule_info | 节点的ScheduleInfo信息,包含以下内容:mem_scope:输出存放位置。core_bind:绑核方案。mem_free_l1:L1剩余空间大小,结果为-1时表示L1剩余空间大小计算失败。mem_free_llb:LLB剩余空间大小,结果为-1时表示LLB剩余空间大小计算失败。说明:如节点有多个ScheduleInfo信息,会以ScheduleInfo_index的形式呈现节点的调度信息。 |
| split_axis | 表示Group或Fuse Op切分时,对Group或Fuse Op输出Tensor的哪个轴进行切分。节点为Group,且被拆分时,值为被拆分的axis值。节点为Fuse Op时,进行split操作的axis值。 |
| split_factor | 基于split_axis对Tensor切分的份数。 |
INPUTS
| 字段名 | 说明 |
|---|---|
| 0、 1、 2、3... | 节点的非常数输入项。 |
| 其余项 | 冗余项,不建议您使用。 |
OUTPUTS
| 字段名 | 说明 |
|---|---|
| 0、1、2、3... | 节点的输出项。 |
注意:
节点(Fuse Op)输入中的常量不会以节点形式展现,您可在点击该节点后在右侧出现的面板中的inputs_dtype和inputs_shape中查看常量信息。
目前显示的group下标顺序并不是实际手动设置的group顺序,您在设置split策略和ScheduleInfo时需重点关注。
1.8. 通过STC_DDK使用手动图调度方案
1.8.1. 前提条件
已通过STC_DDK导出YAML格式的自动图调度方案。导出方式请参见本文使用STC_DDK分析图调度效果章节。
1.8.2. 使用流程
查看导出的自动图调度方案,确实是否满足您的需求,按需进行修改。
导入模型文件。
调用引入的load_schedule方法。
加载YAML文件里的手动图调度方案。
进行模型编译。
1.8.3. 代码示例
import tvm
from tvm.target import Target
import tb
from tb.relay.graph_schedule import *
from stc_ddk.stc_aic.scheduleviewer import load_schedule
def load_relay(relay_path):
with open(relay_path, "r") as f:
mod = tvm.parser.parse(f.read())
return mod, {}
def tvm_build(mod, params, target, schedule_fn):
transform_config = {"tb.dump_graphschedule": True} # execute dump function
with tvm.transform.PassContext(instruments=[tb.DumpIR()], opt_level=3, config=transform_config):
tb_mod = tb.relay.backend.build_module(mod, params, target, schedule=schedule_fn)
print("STC-TVM build completed for", target)
return tb_mod
if __name__ == "__main__":
relay_path = "model.relay"
mod, params = load_relay(file)
# mod代表Relay IR Module,manual_config.yaml文件路径以您的manual_config.yaml实际路径为准
schedule_fn = load_schedule(mod, "auto_graphschedule/manual_config.yaml")
tb_mod = tvm_build(mod, params, "stc_tc", schedule_fn)
tb_mod.export_library("model.stcobj")
1.9. 接口说明
1.9.1. stc_aic接口(Python)
1.9.1.1. load_model
接口描述:将模型文件(例如PyTorch、TensorFlow或ONNX格式的文件)导入,并转换为ONNX或TensorFlow格式。转换后的模型文件可方便地加载和处理。
接口定义:
def load_model(kwargs)
参数说明:
**kwargs以key-value形式传入模型的信息,支持传入的模型相关信息如下:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| filename | str | 是 | 模型文件的路径。 |
| input_shapes | dict[str, list] | 否 | 模型的输入名以及shape信息,默认值为None。 |
| input_dtypes | dict[str,str] | 否 | 模型的输入名以及其对应的数据类型。 |
| output_names | str | 否 | 模型输出项名称,进行模型格式转换时需设置该参数,例如output_1。 |
| opset | INT | 否 | opset版本,默认值为13。只在输入模型为PyTorch模型时使用。 |
| to_onnx | bool | 否 | 是否将模型转换为ONNX格式,默认为False。设置为False时,不会进行模型转换。设置为True时,将模型转换为ONNX格式。 |
| signature | list[str] | 否 | TensFlow SavedModel类型模型属性,默认为serve,可传入新的signature。 |
| custom_op | list[str] | 否 | 如果模型中含有您自定义的算子(如通过TensorFlow自定义算子),需要传入自定义算子type。 |
| custom_op_lib | list[str] | 否 | 如果模型中含有自定义算子,需传入该自定义算子所需的自定义算子依赖库.so文件的路径。 |
返回值:
| 类型 | 描述 |
|---|---|
| dict | 模型相关的信息。其中包括:graph:模型转换和加载后得到的TensorFlow模型或ONNX模型。origin_shape:原始模型的输入shape和输出shape。frontend_type:模型图前端类型,可以是TensorFlow或ONNX。 |
1.9.1.2. extract_sub_graphs
接口描述:对加载的待处理原始模型进行切图处理,切成适合在CPU或NPU上推理部署的子图,从而改善模型的性能。
接口定义:
def extract_sub_graphs(model_info):
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| model_info | dict或者graph_pb2.GraphDef或者ModelProto | 是 | 通过load_model加载得到的模型相关信息,信息以字典形式展示,主要包括以下内容:graph:模型转换和加载后得到TensorFlow模型或ONNX模型。origin_shape:原始模型的输入shape和输出shape。frontend_type:模型图前端类型,TensorFlow或ONNX。ONNX和TensorFlow等形式加载得到的待处理模型对象,模型对象一般包括图结构、节点、输入、输出等信息。 |
| input_shapes | list[dict] | 否 | 模型输入的一组或多组input_shape信息。 |
返回值:
| 类型 | 描述 |
|---|---|
| graph_pb2.GraphDef或者ModelProto | 进行切图后的模型对象。 |
| list[dict] | 模型的切图结果列表,包含子图名称(graph_name)、子图对象(graph)、运行端(device)、子图类型(frontend_type)、子图文件路径(file)、子图输入(inputs)、子图输出(outputs)信息。例如['graph_name', 'graph', 'device', 'frontend_type', 'file', 'inputs', 'outputs']。 |
1.9.1.3. compile_graph
接口描述:对模型的切图结果进行编译。
接口定义:
def compile_graph(sub_graphs, config={}):
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| sub_graphs | list[dict] | 是 | 模型的切图结果列表。 |
| config | dict | 否 | NPU图部分编译配置项。 |
1.9.1.4. dump_json
接口描述:生成model.json文件保存模型的切图结果,供stc_aie调用。
接口定义:
def dump_json(model_info, sub_graphs, out_folder_):
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| model_info | dict或者graph_pb2.GraphDef或者ModelProto | 是 | 通过load_model加载得到的模型相关信息,信息以字典形式展示,主要包括以下内容:graph:模型转换和加载后得到TensorFlow模型或ONNX模型。origin_shape:原始模型的输入shape和输出shape。frontend_type:模型图前端类型,可以是TensorFlow或ONNX。ONNX和TensorFlow等形式加载得到的待处理模型对象,模型对象一般包括图结构、节点、输入、输出等信息。 |
| sub_graphs | 模型的切图结果列表 | 是 | 模型的切图结果列表。 |
| out_folder_ | 保存目标文件夹 | 是 | 保存模型的切图结果文件夹。 |
返回值:
| 类型 | 描述 |
|---|---|
| dict[stc, Any] | 模型切图结果信息。 |
1.9.2. stc_aie接口(C)
1.9.2.1. LoadModel
接口描述:加载模型。
接口定义:
STC_GRAPH LoadModel(const char* file);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| file | const char* | 是 | 通过stc_aic得到的模型文件夹路径或模型文件夹中model.json路径。 |
返回值:
| 类型 | 描述 |
|---|---|
| STC_GRAPH | 模型的句柄信息。 |
1.9.2.2. ReleaseModel
接口描述:释放模型资源。
接口定义:
void ReleaseModel(STC_GRAPH graph);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| graph | STC_GRAPH | 是 | LoadModel的返回值。 |
返回值:无
1.9.2.3. DumpModel
接口描述: Dump模型信息。
接口定义:
void DumpModel(STC_GRAPH graph);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| graph | STC_GRAPH | 是 | LoadModel的返回值。 |
返回值:无
1.9.2.4. CreateTensor
接口描述:创建STCTensor。
接口定义:
STC_TENSOR CreateTensor(const char* name, int64_t *dims, int dim_size, const char* d_type, void* data = NULL);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| name | const char* | 是 | STCTensor的名字。 |
| dims | INT64_t* | 是 | STCTensor的维度信息。 |
| dim_size | INT | 是 | STCTensor的维度长度。 |
| d_type | const char* | 是 | STCTensor的数据类型。支持类型列表 ["Float32", "Float16", "INT64", "INT32", "INT16", "INT8", "UINT64", "UINT32", "UINT16", "UINT8"],不区分大小写。 |
| data | void* | 否 | STCTensor的数据内存存放的地址。当为null时,STCTensor内部会随机分配内存。 |
返回值:
| 类型 | 描述 |
|---|---|
| STC_TENSOR | STCTensor的句柄信息。 |
1.9.2.5. GetTensorData
接口描述:获取STCTensor的数据内存存放的地址。
接口定义:
const void* GetTensorData(STC_TENSOR tensor);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| tensor | STC_TENSOR | 是 | STCTensor的句柄。 |
返回值:
| 类型 | 描述 |
|---|---|
| const void* | 存放STCTensor数据的内存地址。 |
1.9.2.6. GetTensorName
接口描述:获取STCTensor的名称信息。
接口定义:
const char* GetTensorName(STC_TENSOR tensor);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| tensor | STC_TENSOR | 是 | STCTensor的句柄。 |
返回值:
| 类型 | 描述 |
|---|---|
| const char* | STCTensor的名字信息。 |
1.9.2.7. GetTensorDataType
接口描述:获取STCTensor的数据类型信息。
接口定义:
const char* GetTensorDataType(STC_TENSOR tensor);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| tensor | STC_TENSOR | 是 | STCTensor的句柄。 |
返回值:
| 类型 | 描述 |
|---|---|
| const char* | STCTensor的数据类型名称。 |
1.9.2.8. GetTensorDim
接口描述: 获取STCTensor的维度信息。
接口定义:
int GetTensorDim(STC_TENSOR tensor, int64_t* dims);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| tensor | STC_TENSOR | 是 | STCTensor的句柄。 |
| dims | INT64_t* | 是 | 存放获取的维度信息。可使用MAX_DIMS_NUM进行初始化长度。 |
返回值:
| 类型 | 描述 |
|---|---|
| INT | 获取维度信息的长度。获取成功时,得到的维度信息的长度大于0。 获取失败时,得到的维度信息的长度等于0。 |
1.9.2.9. DestoryTensor
接口描述:释放STCTensor资源。
接口定义:
void DestoryTensor(STC_TENSOR tensor);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| tensor | STC_TENSOR | 是 | STCTensor的句柄。 |
返回值:无
1.9.2.10. CreateGraphExec
接口描述:创建模型执行器。
接口定义:
STC_GRAPH_EXEC CreateGraphExec(STC_GRAPH graph);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| graph | STCGraph | 是 | 模型的句柄。 |
返回值:
| 类型 | 描述 |
|---|---|
| STC_GRAPH_EXEC | Stc模型执行器的句柄。 |
1.9.2.11. GraphExecRun
接口描述:通过模型执行器执行推理服务。
接口定义:
int GraphExecRun(STC_GRAPH_EXEC ge, const char **outs, STC_TENSOR *inputs, int in_num, STC_TENSOR *outputs, int out_num);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| ge | STC_GRAPH_EXEC | 是 | 模型执行器的句柄。 |
| out_names | const char ** | 是 | 执行推理期望获取输出的名字信息。 |
| inputs | STC_TENSOR * | 是 | 执行推理传入的STCTensor信息。 |
| in_num | INT | 是 | 执行推理传入的STCTensor 数量。 |
| outputs | STC_TENSOR * | 是 | 存放执行推理获取到的输出STCTensor信息。 |
| out_num | INT | 是 | 执行推理期望获取输出数量。 |
返回值:
| 类型 | 描述 |
|---|---|
| INT | 执行成功时,返回0。执行失败时,返回-1。 |
1.9.2.12. DestoryGraphExec
接口描述: 释放模型执行器资源。
接口定义:
void DestoryGraphExec(STC_GRAPH_EXEC ge);
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| ge | STC_GRAPH_EXEC | 是 | 模型执行器的句柄。 |
返回值:无