1. 希姆计算TensorTurbo使用说明
1.1. 版本历史
| 文档版本 | 对应产品版本 | 作者 | 日期 | 说明 |
|---|---|---|---|---|
| V1.12.0 | STCRP V1.5.0 | 希姆计算 | 2023-07-26 | 文档架构调整和编辑优化。 |
| V1.11.0 | STCRP V1.4.0 | 希姆计算 | 2023-04-04 | 新增TensorTurbo支持的Config。架构调整和编辑优化。 |
| V1.10.0 | STCRP V1.3.0 | 希姆计算 | 2023-01-16 | 不再体现部分模型的自动图优化和手动图调度对比。 |
| V1.9.0 | STCRP V1.2.0 | 希姆计算 | 2022-12-06 | 更新TensorTurbo支持自动图优化的模型列表。更新编译模型章节内容,主要涉及模型接口相关内容。 |
| V1.8.0 | STCRP V1.1.0 | 希姆计算 | 2022-09-08 | 更新TensorTurbo支持自动图优化的模型列表。 |
| V1.7.0 | TensorTurbo 1.7.0 | 希姆计算 | 2022-08-01 | 配套TensorTurbo V1.7.0发版文档。 |
| V1.6.0 | TensorTurbo 1.6.0 | 希姆计算 | 2022-06-30 | 配套TensorTurbo V1.6.0发版文档。 |
| V1.5.0 | TensorTurbo 1.5.0 | 希姆计算 | 2022-06-02 | 统一扩展名格式。 |
| V1.4.0 | TensorTurbo 1.4.0 | 希姆计算 | 2022-04-29 | 整篇编辑优化。基本概念单独成篇。补充量化参数说明。更新支持自动图优化的模型。更新手动图调度示意图和示例。 |
| V1.3.0 | TensorTurbo 1.3.0 | 希姆计算 | 2022-03-31 | 更新编译模型章节内容。支持的OP列表单独成篇。 |
| V1.2.0 | TensorTurbo 1.2.0 | 希姆计算 | 2022-03-01 | 新增支持logical_not、not_equal、less_equal算子。 |
| V1.2.0.RC1 | TensorTurbo 1.2.0 | 希姆计算 | 2022-02-24 | 初始对外版本。 |
1.2. TensorTurbo介绍
TensorTurbo是一个基于TVM二次开发的AI编译器,通过简洁的编译接口将主流框架下的预训练模型编译为STCP920上的可执行文件。使用TensorTurbo时,您只需要导入模型并按需设置编译参数。TensorTurbo会自动将不同框架下的模型转换为统一的TensorTurbo IR Module,最终得到可执行的二进制文件,简化推理过程。在编译过程中会进行定制性优化,例如通过子图划分、子图并发调度、子图内循环优化、子图内向量化、自动的图优化和算子优化等手段提高硬件资源的利用率,提升模型在STCP920上的推理性能。同时TensorTurbo也提供了手动图调度接口,进一步满足自行优化的需求。
1.3. 使用TensorTurbo编译模型
1.3.1. 执行步骤
导入模型。TVM提供了导入接口,支持直接导入TensorFlow、PyTorch、ONNX等主流框架的模型以及TVM Relay IR,不同格式的模型文件会转换为统一的IR Module。
启动编译。TensorTurbo的编译接口支持图优化参数,另外还提供了TensorTurbo Config,方便您提升模型的精度或性能,以及进行代码调试。
导出编译好的stcobj文件。基于stcobj,可以直接执行,或者将导出的stcobj作为一个模块部署到实际业务中。
1.3.2. 代码示例
下文以ResNet50 V2、模型框架TensorFlow 1.15(pb文件)为例,使用TensorTurbo编译模型输出二进制文件的代码示例如下:
import tb
import tvm
from tb.relay.graph_schedule import *
import tensorflow as tf
model_path = "./resnet-50_v2.pb"
out_path = "./resnet-50_v2.stcobj"
graph_def = tf.compat.v1.GraphDef()
with tf.compat.v1.gfile.GFile(model_path, "rb") as f:
graph_def.ParseFromString(f.read())
mod, params = tvm.relay.frontend.from_tensorflow(graph_def)
config = {"tb.dump_auto_graphschedule": True} # execute dump function
with tvm.transform.PassContext(config=config):
tb_mod = tb.relay.backend.build_module(mod, params, "stc_tc")
tb_mod.export_library(out_path)
1.4. 使用TensorTurbo部署模型
1.4.1. 执行步骤
引入必要的库。
加载编译好的stcobj文件。
输入数据传递给该模型进行推理,并输出推理结果。
1.4.2. 代码示例
import tb
import tvm
import numpy as np
# stc run
graph_exec = tb.kernel.Executor.load_from_stcobj("resnet-50_v2.stcobj")
input_data_stc = {"input_1_0" : input_data["input_1_0"].astype("float16")}
np.save("input_1_0.npy", input_data["input_1_0"].astype("float16"))
graph_exec.set_input(input_data_stc)
stc_out = graph_exec()[0]
print("=============== stc out ====================")
print(stc_out)
1.5. Config支持
希姆计算提供了一些和模型相关的配置项(Config),通过这些Config您可以调整模型的精度与性能,也可以dump出图调度过程中的重要阶段的产出信息,通过分析图调度信息从而制定合适的图调度策略。
1.5.1. Config使用流程
使用Config的一般过程如下:
加载模型。
根据需要设置Config。
通过
tvm.transform.PassContext载入设置的Config,例如将常用的Config汇总在一个yaml文件,然后代码中读取该文件中的配置信息,最后将配置信息通过tvm.transform.PassContext的参数载入。调用
tb_mod = tb.relay.backend.build_module编译模型。运行模型,确认Config的效果。
用于改善精度或性能:对比打开和关闭Config的精度或性能差异。
用于调试:查看并分析dump出的文件。
1.5.2. 代码示例
下文以用于改善精度的tb.bisection_sum配置项为例,演示Config的一般使用流程:
# 加载模型
mod, params = relay.frontend.from_tensorflow(graph_def)
...
# 设置Config
config={
"tb.bisection_sum": "Performance",
}
...
# 编译模型
with tvm.transform.PassContext(
config=config
):
...
tb_mod = tb.relay.backend.build_module(
mod,
params,
target,
schedule=schedule,
)
...
# 运行模型
out_list, perf_recs = tvm_run(tb_mod, feed_data)
...
在我们对bert_128_mixin_asr_end2end模型的测试中:
当
tb.bisection_sum设为"Performance",模型输出的最大绝对误差(Max Absolute Diff)为0.00235。当
tb.bisection_sum设为"Precision",此模型的所有LayerNormalization算子使用二分法累加,模型输出的Max Absolute Diff为0.00115。更多详情,请参见下文用于改善精度 > tb.bisection_sum章节。
说明:测试结果可能受多方面因素影响,模型输出的最大绝对误差以您的实际测试为准。
1.5.3. 用于改善精度
1.5.3.1. tb.expand_multi_axis_reduce
描述:对reduce类算子,控制是否将具有多规约轴的算子扩展为多个具有单规约轴的算子。
类型:String
取值范围:
"Performance"(缺省值):不对reduce类算子做规约轴扩展。
"Precision":对reduce类算子,将具有多规约轴的算子扩展为多个具有单规约轴的算子。在目前的模型中,已知当Mean算子做reduce操作时,如果有多个规约轴且维度较大(大于等于30)可能会出现精度问题,这时可以打开
tb.expand_multi_axis_reduce改善精度,但扩展的同时会增加参与计算的算子个数,因此可能导致性能下降。"Customization":模型中多规约轴的reduce算子,如果reduce轴大小小于64则做规约轴扩展。您也可以将Customization设置为其他正整数,如果reduce轴大小小于该正整数则做规约轴扩展。
注意:
tb.expand_multi_axis_reduce设置为正整数时,也需要对正整数加引号(" "),例如"64"。
1.5.3.2. tb.bisection_sum
描述:控制对模型中涉及累加的算子是否使用二分法累加。
二分法累加是指将需累加的数据分成前后两部分,将它们对应位置相加,然后将结果再分成前后两部分,对应位置相加,此过程递归进行。在执行模型时,通常会涉及累加的算子,包括LayerNormalization、LpNormalization、Mean、Sum、ReduceL1、ReduceL2、ReduceLogSum、ReduceLogSumExp、ReduceProd、ReduceSumSquare、MeanVarianceNormalization和InstanceNormalization。对于多个规约轴且涉及累加的算子需先通过设置tb.expand_multi_axis_reduce,将其扩展为多个具有单规约轴的算子后再做二分累加。使用二分法累加可以减小进行相加的两个操作数大小的差距,从而可以改善精度,但是同时增加了额外的相加操作,需要增加指令数和占用额外的buffer,导致性能损失。
类型:String
取值范围:
"Performance"(缺省值):设置为
"Performance"时,不使用二分法累加。"Precision":设置为
"Precision"时,模型中涉及累加的算子使用二分法累加。"Customization":设置为
"Customization"时,模型中涉及累加的算子,如果reduce轴大小大于等于128则使用二分法累加。您也可以将Customization设置为其他正整数,如果模型中涉及累加,且reduce轴大小大于等于该正整数,则会对模型中涉及累加的算子使用二分法累加。
注意:
tb.bisection_sum设置为正整数时,也需要对正整数加引号(" "),例如"64"。
1.5.3.3. tb.bisection_matmul
描述:根据K轴(规约轴)大小控制模型中的matmul算子是否使用二分法累加。使用二分法累加可以减小进行相加的两个操作数大小的差距,从而可以改善精度,但是同时增加了额外的相加操作,需要增加指令数和占用额外的buffer,导致性能损失。
类型:int
取值范围:
-1(缺省值):对模型中的matmul算子不使用二分法累加。0:对模型中所有的matmul算子使用二分法累加。>0:代表K轴阈值,阈值需设置为整数,设置好阈值后,只对K轴上大于阈值的matmul算子使用二分法累加。
1.5.4. 用于改善性能
1.5.4.1. tb.use_auto_spill
描述:在手动图调度时,控制是否允许group内部算子的输出数据自动溢出到LLB/DDR。
允许自动溢出:可以将整个group看做一个黑盒,只需考虑整个group的最终输出数据的存储占用即可,无需细化到group的内部算子。这时可以降低手动图调度方案的设计难度,但自动溢出时会增加额外的数据搬运,进而可能导致性能下降。
不允许自动溢出:必须保证过程中所有节点的存储占用(包括整个group的最终输出数据、group内部算子的输出数据)不能超过L1的存储限制。这时需要了解group内部算子的情况,手动图调度方案的设计难度会相应增加。
类型:bool
取值范围:
True:如果group内部算子的输出数据可以全部驻留在L1,则不会自动溢出到LLB/DDR;否则部分输出数据会自动溢出到LLB/DDR,但此时group输出数据的mem_scope依然是手动图调度方案中设置的值,因此建议仅在group内部算子对输出数据的存储位置要求不严格时选择打开tb.use_auto_spill。False(缺省值):各group内部算子的输出数据必须可以驻留在L1,即输出数据的最大存储占用不能超过L1的存储限制,否则存储分配报错。
1.5.4.2. tb.loop
描述:控制对kernel函数的第几个参数进行循环计算,减少参数的加载过程,从而改善模型性能。
类型:list
取值范围:
[]:空位代表不设置,即不进行循环计算。
[arg0, arg1, ...]:需要进行循环计算的参数list。其中arg{index}对应kernel函数的参数列表,从0开始计算,例如设置为
"tb.loop": [0,4]。循环次数为:round{tensor_batch/model_batch+1},其中tensor_batch为实际输入的batch,model_batch为编译模型时所采用的batch,相除结果向上取整。
1.5.5. 用于输出调试信息
1.5.5.1. tb.dump_graphschedule
描述:控制是否在手动图调度过程中导出典型阶段对应的relay文件。
类型:bool
取值范围:
True:自动生成graphschedule目录,并导出典型阶段的relay文件。希姆计算提供的STC_DDK工具可以解析图调度结果,对解析出的图调度结果可以用Netron可视化查看,详细说明请参见希姆计算STC_DDK使用说明。False:不导出典型阶段对应的relay文件。
1.5.5.2. tb.dump_auto_graphschedule
描述:控制是否在自动图调度过程中导出典型阶段对应的relay文件。
类型:bool
取值范围:
True:自动生成auto_graphschedule目录,并导出典型阶段的relay文件。希姆计算提供了ScheduleViewer工具解析图调度结果,对解析出的图调度结果则可以用Netron可视化查看,详细说明请参见希姆计算STC_DDK使用说明。False:不导出典型阶段对应的relay文件。
1.5.5.3. tb.dump_file
描述:用于导出模型编译过程中生成的C++代码(保存至cc文件),便于分析和调试模型。
类型:str
取值范围:默认导出至模型编译脚本所在目录的out.cc文件中。您可以手动设置为其他文件,例如设置为"tb.dump_file":/home/stc/resnet50-test/resnet50-out.cc。如果设置的值中包括路径,请确保该路径存在,否则会导出失败。
1.6. 图调度
1.6.1. 原理
针对高速缓存速度快但容量较小的问题,我们提供了图调度功能提高计算图的局部性,方便您更高效地利用高速缓存。简单来说,您可以通过图调度功能在整个网络上发掘算子间重用L1/LLB上数据的机会,实现在计算过程中数据常驻L1/LLB,从而提高计算效率,同时避免在L1/LLB和DDR之间频繁搬运数据,也降低了对LLB、DDR带宽的需求。
1.6.2. 优势
相比以算子为单位执行,经过图调度的计算图在执行时有以下优势:
提高局部性:实现在计算过程中数据常驻L1/LLB,避免因数据量大溢出至速度相对较慢的DDR。
提高并行度:实现并行处理没有相互依赖的计算,减少时间步骤的同时充分利用硬件资源。
1.6.3. 优势来源
结合下图,简单说明了图调度优势的来源:
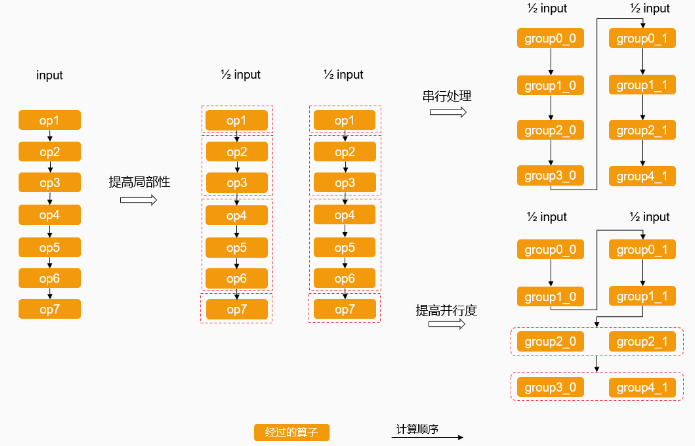
说明:图中算子分组、数据切分等方式仅为示例,用于简单说明优势的来源,实际设计图调度方案时请根据模型的网络结构等因素合理确定相应的策略。
原计算图以算子为单位执行,每个算子处理完所有input后才会走到下一个算子。此时中间结果对应所有input,如果大小超出L1/LLB的容量,则数据溢出缓存到DDR,频繁搬运数据会降低性能。
分别从划分input和算子考虑优化。可以按内存使用将input划分为多份(以2份为例)分批计算,确保不超过L1/LLB的容量就不用溢出缓存到DDR,提高了局部性。这时,每份数据经过的算子相同,实际上已经扩展成为2个同构的计算图。为方便表示,可以将算子划分为多个group(以4个group为例)。
将input划分为多份后,在处理完部分input后即可走到下一个算子。此时虽然中间结果可以常驻L1/LLB,但如果继续按原计算顺序串行处理每份数据,时间步骤的增多又会导致性能降低。
为提高并行度,可以找到内存占用较小的部分并行计算,并相应调整计算顺序。由于处理2份数据的计算图相同,并行的计算之间没有相互依赖,调整计算顺序不会影响对同一input的最终结果。这样,中间结果常驻L1/LLB,同时降低了时间步骤增多带来的影响,可以获得整体更优的性能。
1.6.4. 功能入口
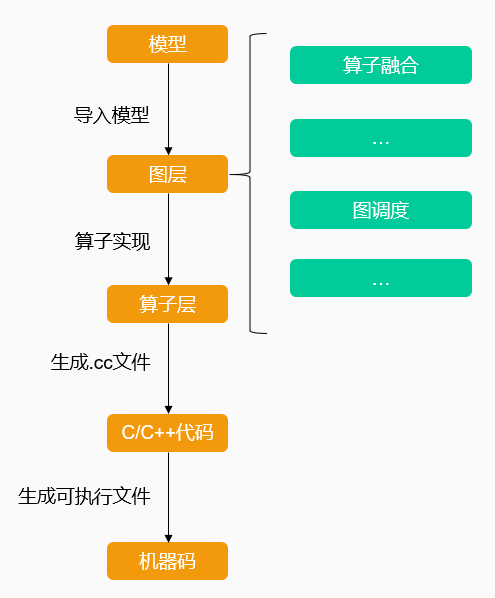
在一个完整的模型推理流程中,使用不同的图调度方式会导致编译得到的可执行文件有差异,进而影响推理性能。在使用流程中,如果狭义地理解使用图调度的操作,可以认为是传入图调度相关参数的操作,从而影响编译过程。
而在模型编译流程中,图调度功能的入口位于图层级别,如下图所示:
1.6.5. 支持的方案
图调度在模型编译阶段进行,模型导入经过图层后、图层Lower到算子层前会进行一系列优化动作,图调度则是其中一环。TensorTurbo目前支持自动图调度和手动图调度:
自动图调度:自动设置图模型的合理的、性能较优的调度信息,从而避免对图模型结构的分析,节省您的工作量。
手动图调度:您可通过手写API操作Relay IR,指定每个算子的图调度信息,满足功能和性能上的定制化需求。
| 阶段 | 自动图调度 | 手动图调度 | | ------------------------------------------------------------ | ------------------------------------------------------------ | ------------------------------------------------------------ | | 设计方案 | 希姆计算设计 | 使用者自行设计 | | 实现 | 希姆计算实现 | 希姆计算提供API,使用者自行实现。更多使用详情,请参见希姆计算手动图调度方案设计指南。 | | 使用流程:获取模型和数据集。了解模型信息,确定模型输入项和模型输出项。加载模型。编译模型。运行模型的编译结果。 | 在使用build_module编译模型时,定义config通过tb.graph_schedule_level指定自动图调度的级别为3。 | 在使用build_module编译模型时,读入手动设计的图调度方案,并通过schedule参数传入调度信息。 | | 查看效果 | 在config中tb.dump_auto_graphschedule为True,打开dump开关。 | 在config中tb.dump_graphschedule为True,打开dump开关。 |
说明:因为直接写手动图调度方案比较难,我们建议您通过自动图调度方案(启发式图调度方案)转手动图调度方案后,再对转出来的手动图调度方案进行分析和优化,最后执行优化后的手动图调度方案。更多详情,请参见希姆计算STC_DDK使用说明。
1.7. 接口定义
1.7.1. 编译模型接口
1.7.1.1. tvm.relay.frontend.from_onnx
接口描述:导入ONNX模型(onnx文件)并转换为同等的Relay文件。
接口定义:
tvm.relay.frontend.from_onnx(model, shape=None, dtype="float32", opset=None, freeze_params=True, convert_config=None)
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| model | onnx.ModelProto | 是 | onnx.ModelProto实例对象。 |
| shape | dict[str, tuple] | 否 | 输入的shape信息,默认值为None。 |
| dtype | str或dict | 否 | 数据元素的类型,默认值为float32。 |
| opset | int | 否 | opset版本,默认值为None。 |
| freeze_params | bool | 否 | 冻结权重参数项,默认值为True。True:将模型权重参数嵌入到模型中,作为常量,有助于模型静态化。False:模型权重参数保持变量化。 |
| convert_config | dict | 否 | 模型中算子转换配置项,默认值为None。默认值为None时,里面的配置项为{"use_nt_batch_matmul": True},将onnx模型中的matmul算子转换成NT格式nn.batch_matmul。 |
返回值:
| 类型 | 描述 |
|---|---|
| tvm.ir.module.IRModule | 模型转换的IRModule实例对象。 |
| dict | IRModule实例对象使用的参数,例如{"feature_bias": [[259, 1], "float32", "-0.44907734", "1.3026619", "0.47860476", "0.3003683"]}。 |
调用示例:
import onnx import tvm model = onnx.load("model.onnx") mod, params = tvm.relay.frontend.from_onnx(model)
1.7.1.2. tvm.relay.frontend.from_tensorflow
接口描述:导入Tensorflow模型(pb文件)并转换为同等的Relay文件。
接口定义:
tvm.relay.frontend.from_tensorflow(graph, layout="NHWC", shape=None, outputs=None, convert_config=None)
- 参数说明:
<table border="1" class="docutils">
<thead>
<tr>
<th><strong>参数</strong></th>
<th><strong>类型</strong></th>
<th><strong>是否必选</strong></th>
<th><strong>描述</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>graph</td>
<td>GraphDef</td>
<td>是</td>
<td>Tensorflow GraphDef实例对象。</td>
</tr>
<tr>
<td>layout</td>
<td>string</td>
<td>否</td>
<td>数据格式类型Layout,默认值为NHWC。</td>
</tr>
<tr>
<td>shape</td>
<td>Dict[str, list]</td>
<td>否</td>
<td>输入shape。</td>
</tr>
<tr>
<td>outputs</td>
<td>list(str)</td>
<td>否</td>
<td>输出的Tensor名。</td>
</tr>
<tr>
<td>convert_config</td>
<td>dict[str, Any]</td>
<td>否</td>
<td>模型中算子转换配置项,默认值为None。默认值为None时,里面的配置项为<code>{"use_dense": True, "use_nt_batch_matmul": True}</code>,将TensorFlow模型中的matmul算子转换成nn.dense或nn.matmul,batch_matmul算子转换成NT格式<code>nn.batch_matmul</code>。</td>
</tr>
</tbody>
</table>
- 返回值:
<table border="1" class="docutils">
<thead>
<tr>
<th><strong>类型</strong></th>
<th><strong>描述</strong></th>
</tr>
</thead>
<tbody>
<tr>
<td>tvm.ir.module.IRModule</td>
<td>模型转换的IRModule实例对象。</td>
</tr>
<tr>
<td>dict</td>
<td>IRModule实例对象使用的参数,例如{"feature_bias": [[259, 1], "float32", "-0.44907734", "1.3026619", "0.47860476", "0.3003683"]}。</td>
</tr>
</tbody>
</table>
- 调用示例:
```Python
import tvm
import tensorflow as tf
with tf.Graph().as_default():
with tf.Session() as sess:
meta_graph_def = tf.compat.v1.saved_model.loader.load(sess, ["serve"], "saved_model")
graph_def = sess.graph_def
mod, params = tvm.relay.frontend.from_tensorflow(graph_def)
1.7.1.3. tvm.relay.frontend.from_pytorch
接口描述:导入PyTorch模型(pb文件)并转换为同等的Relay文件。
接口定义:
tvm.relay.frontend.from_pytorch(script_module, input_infos, custom_convert_map=None, default_dtype="float32", use_parser_friendly_name=False)
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| script_module | TopLevelTracedModule | 是 | TopLevelTracedModule实例对象。 |
| input_infos | list[tuple] | 是 | 输入的shape信息。 |
| custom_convert_map | dict | 否 | 自定义算子转换映射关系,转换映射后,模型中左边的算子会被右边的算子所代替。例如{"aten::stft": stft}。 |
| default_dtype | str | 否 | 默认数据类型,默认值为float32。 |
| use_parser_friendly_name | bool | 否 | 是否使用更友好的权重参数名,默认值为False。True:对权重参数名称使用.来替换_,方便用户阅读。False:不改变权重参数名称。 |
返回值:
| 类型 | 描述 |
|---|---|
| tvm.ir.module.IRModule | 模型转换的tvm.IRModule实例对象。 |
| dict | IRModule实例对象使用的参数,例如{"feature_bias": [[259, 1], "float32", "-0.44907734", "1.3026619", "0.47860476", "0.3003683"]}。 |
调用示例:
import torch import tvm model = torch.jit.load("model.pb") traced_model = torch.jit.trace(model, inputs) mod, params = tvm.relay.frontend.from_pytorch(traced_model.eval(), input_infos=shape_list)
1.7.1.4. tvm.relay.frontend.from_keras
接口描述:导入Keras模型(h5文件)并转换为同等的Relay文件。
接口定义:
tvm.relay.frontend.from_keras(model, shape=None, layout="NCHW")
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| model | keras.engine.training.Model或tensorflow.keras.models.Model | 是 | Keras Model实例对象。 |
| shape | dict[str, list或tuple] | 否 | 输入的shape信息,默认值为None。 |
| layout | str | 否 | 数据格式类型Layout,默认值为NHWC。 |
返回值:
| 类型 | 描述 |
|---|---|
| tvm.ir.module.IRModule | 模型转换的tvm.IRModule实例对象。 |
| dict | IRModule实例对象使用的参数,例如{"feature_bias": [[259, 1], "float32", "-0.44907734", "1.3026619", "0.47860476", "0.3003683"]}。 |
调用示例:
from tensorflow import keras import tvm model = keras.models.load_model('model.h5') mod, params = tvm.relay.frontend.from_keras(model)
1.7.1.5. tvm.parser.fromtext
接口描述:加载Relay模型。
接口定义:
tvm.parser.fromtext(source, source_name="from_string")
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| source | str | 是 | relay模型文件内容。 |
| source_name | str | 否 | relay模型名称,默认值为from_string。 |
返回值:
| 类型 | 描述 |
|---|---|
| tvm.ir.module.IRModule | 加载模型后生成的IRModule对象。 |
调用示例:
import tvm mod = tvm.parser.fromtext(open("model.relay", "r").read())
1.7.1.6. tb.relay.backend.build_module
接口描述:编译传入的relay模型文件。
接口定义:
tb.relay.backend.build_module(mod, params, target, kernel_name="", schedule=None)
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| mod | tvm.ir.module.IRModule | 是 | 模型的IRModule对象。 |
| params | dict | 是 | IRModule实例对象使用的参数,例如{"feature_bias": [[259, 1], "float32", "-0.44907734", "1.3026619", "0.47860476", "0.3003683"]}。 |
| target | str | 是 | 设备类型标识,一般为stc_tc。 |
| kernel_name | str | 否 | 自定义核函数名称,默认值为空,体现在编译结果中则为NPUKernel。 |
| schedule | function | 是 | 图层调度函数,默认值为None。默认为None时,编译模型时使用启发式自动图优化方案,您可以通过配置参数指定自动图优化的级别。您也可以自行手写图调度方案进行调用。 |
返回值:
| 类型 | 描述 |
|---|---|
| tvm.runtime.module.Module | 编译模型后生成的runtime module对象。 |
调用示例
import tb import tvm mod, params = tvm.relay.frontend.from_onnx(model, shape_dict) with tvm.transform.PassContext(config=transform_config): tb_mod = tb.relay.backend.build_module(mod, params, "stc_tc")
1.7.1.7. tb_mod.export_library
接口描述:导出编译好的文件。
接口定义:
tb_mod.export_library(file_name)
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| file_name | str | 是 | 导出的编译文件名。 |
返回值: 无
调用示例:
import tb import tvm tb_mod.export_library("model.stcobj")
1.7.1.8. tb.kernel.Executor.load_from_stcobj
接口描述:加载stcobj文件。
接口定义:
tb.kernel.Executor.load_from_stcobj(obj_path, kernel_name=None)
参数说明:
| 参数 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| obj_path | str | 是 | 编译好的stcobj文件的路径。 |
| kernel_name | str | 否 | 自定义核函数名称,默认值为空,体现在编译结果中则为NPUKernel。 |
返回值:
| 类型 | 描述 |
|---|---|
| tb.kernel.executor.Executor | 加载编译后生成的stcobj文件对象。 |
调用示例:
import tb tb_mod = tb.kernel.Executor.load_from_stcobj("./resnet50.stcobj")
1.7.2. 手动图调度接口
在调用手动图调度API前,需要导入相关依赖:
import tb
from tvm.target import Target
from tb.relay.graph_schedule import (
SetSpanName,
GetNPUSubFunctions,
ListOps,
Group,
GroupOps,
SplitGroups,
NPUMemScope,
ScheduleInfo,
Schedule,
)
1.7.2.1. SetSpanName
接口描述:为每个算子设置唯一的名称。
接口定义:
def SetSpanName()
参数说明:
无
返回值:
为算子设置过唯一名称的IRModule。
调用示例:
mod = SetSpanName()(mod)
1.7.2.2. GetNPUSubFunctions
接口描述:获取主函数中的NPU Kernel函数列表,返回由NPU Kernel函数组成的list。NPU Kernel函数用于表示在NPU上执行的计算子图,NPU Kernel函数之外的部分则在CPU上执行。
接口定义:
def GetNPUSubFunctions(function)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| function | Function | 是 | 待索引的主函数。 |
| index | int | 否 | 某个NPU计算子图的索引号。 |
返回值:
NPU Kernel函数组成的list。
调用示例:
func = GetNPUSubFunctions(mod["main"])[0]
1.7.2.3. ListOps
接口描述:获取IRModule所有算子的列表,以dict的形式列出,dict中算子顺序按DAG上的深度优先后序遍历,而非实际的计算顺序。
接口定义:
def ListOps(function, use_uni_name=False)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| function | Function | 是 | 待索引的NPU Kernel函数。 |
| use_uni_name | bool | 否 | True:返回算子组成的dict,key为SpanName,value为一类算子的list。如果已经调用SetSpanName为每个算子设置唯一的名称,则list的length为1。False(默认):返回算子组成的dict,key为IRModule内的算子名,value为一类算子的list。 |
返回值:
IRModule内算子组成的dict。
调用示例:
ops = ListOps(func, use_uni_name=True)
1.7.2.4. class Group
接口描述:描述分组策略,接收输入节点、输出节点列表作为参数,输入节点和输出节点中间的算子将会划分为一个group。其中输入节点、输出节点均使用ListOps得到的算子表示,划分完成后,输入节点的output会作为该group整体的input,而输出节点的output则作为该group整体的output。
注意:group之间不允许包含同一个算子(即重叠),且一个算子必须属于某个group。
接口定义:
class Group(Node):
"""A structure containing group nodes."""
def __init__(self, inputs, output):
"""Create an op group
output: relay.Expr or List[relay.Expr]
The output node of the group.
inputs: List[relay.Expr]
The input nodes of the group.
Returns
-------
group : tb.relay.graph_schedule.Group
The created op group
"""
self.__init_handle_by_constructor__(_ffi_api.Group, output, inputs)
def __getitem__(self, index):
return self.subgroups[index] if len(self.subgroups) > 0 else self
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| inputs | list | 是 | group的输入节点。 |
| output | list | 是 | group的输出节点。 |
返回值:
包含分组信息的Group实例。
调用示例:
# Four-stage partition of resnet-50 graph
groups = [
Group([func.params[0]], ops["add"][15]),
Group([ops["add"][15]], ops["add"][31]),
Group([ops["add"][31]], ops["add"][55]),
Group([ops["add"][55]], ops["nn.softmax"][0]),
]
1.7.2.5. GroupOps
接口描述:根据描述的分组策略划分group。对Group进行代码变换,将子图的信息保存到Relay IR上并封装成函数,后续以调用函数的形式执行子图中的计算。
接口定义:
def GroupOps(groups=None)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| groups | list | 是 | 包含分组信息的Group实例,输入节点和输出节点中间的算子将会划分为一个group。 |
返回值:
group粒度的IRModule。
调用示例:
mod = GroupOps(groups)(mod)
1.7.2.6. SplitGroups
接口描述:描述切分策略并将每个group切分为多个同构的subgroup,保证subgroup的计算都可以在L1上完成。切分完成后,会自动在适当的位置插入split和concatenate算子。
说明:必须保证subgroup内所有算子均可以独立完成计算,各部分之间不会相互影响。
接口定义:
def SplitGroups(groups)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| groups | dict | 是 | 切分策略,支持指定切分轴(split axis)和切分份数(split factor)。目前支持以下形式:groups[0]: 2:表示将group0按batch轴split成2份。groups[0]: (x, 2):表示将group0按轴x切分成2份。默认batch轴为0轴,因此如果x为0,则效果和groups[0]: 2相同。groups[0]: (x, 2, 4, 8):表示将group0按轴x切分成3份,即如果起始index为0,则这3份分别包括0~1、2~3、4~7。groups[0]: [(0, 2), (1, 4)]:表示将group0先按0轴切分成2份,再按1轴切分成4份。说明:x可以取整数表示第几根轴,也可以取字符串reduce 表示reduce轴。 |
返回值:
subgroup粒度的IRModule。
调用示例:
# Group split
mod = SplitGroups(
{
groups[0]: batch // 2,
groups[1]: batch // 4,
groups[2]: batch // 8,
groups[3]: batch // 16,
}
)(mod)
1.7.2.7. ScheduleInfo
接口描述:为subgroup以及自动插入的split和concatenate算子设置输出节点的mem_scope和core_bind,即汇总和存储output的位置。
mem_scope、core_bind、mem_free_l1、mem_free_llb会提供给算子作为属性信息,方便算子根据属性信息执行计算逻辑。core_bind还会为图层提供数据分布信息,例如在concatenate时,图层会根据其core_bind判断是否需要插入npu.redistribution算子。
接口定义:
def ScheduleInfo(node, mem_scope=NPUMemScope.UNSPECIFIED, core_bind=None, mem_free_l1=None, mem_free_llb=None)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| node | 算子名称或Group实例 | 是 | 调度对象,可以是subgroup以及自动插入的split和concatenate算子。需要注意的是:如果subgroup有多个输出,需要以tuple或者list的形式为每个输出指定mem_scope和core_bind。需要为每个subgroup指定一个ScheduleInfo结构,形成一个ScheduleInfo list,其中ScheduleInfo的顺序即计算顺序。 |
| mem_scope | enum | 是 | 调度对象输出最后存放的位置,支持设置为:NPUMemScope.L1:存放在L1上。NPUMemScope.LLB:存放在LLB上。NPUMemScope.DDR:存放在DDR上。需要注意的是:除了输出节点,subgroup内部所有算子的mem_scope均应为 L1。如果需要将内部算子的mem_scope设置为LLB或DDR,只能以该算子为边界重新分组。split算子的mem_scope只能和其输入相同。如果不为concatenate算子设置mem_scope,则concatenate算子的默认mem_scope为DDR。整个计算图最后输出的mem_scope只能为DDR。 |
| core_bind | ndarray | 否 | 数据绑核状态,默认为None,即不手动设置。当mem_scope为LLB或DDR时,为subgroup设置core_bind可方便进一步推导内部算子的core_bind。 |
| mem_free_l1 | int | 否 | 进入subgroup或算子前可用的L1大小。 |
| mem_free_llb | int | 否 | 进入subgroup或算子前可用的LLB大小。 |
返回值:
包含调度信息的ScheduleInfo实例。
调用示例:
注意:由于调用
SplitGroups切分group后自动插入了split和concatenate算子,因此需要再次调用ListOps获取最新的算子列表。
# Schedule groups
# Topological order of subgroups
ops = ListOps(GetNPUSubFunctions(mod["main"])[0])
graph_schedule = [
ScheduleInfo(Op("split_0_span"), NPUMemScope.DDR, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][0], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][1], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(Op("concatenate_0_span"), NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][0], NPUMemScope.LLB, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[0][2], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][3], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(Op("concatenate_1_span"), NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][1], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(Op("concatenate_2_span"), NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[2][0], NPUMemScope.LLB, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[0][4], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][5], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(Op("concatenate_3_span"), NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][2], NPUMemScope.LLB, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[0][6], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][7], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(Op("concatenate_4_span"), NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][3], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(Op("concatenate_5_span"), NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[2][1], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(Op("concatenate_6_span"), NPUMemScope.L1, [7, 6, 5, 4, 3, 2, 1, 0]),
ScheduleInfo(groups[3][0], NPUMemScope.DDR, [7, 6, 5, 4, 3, 2, 1, 0]),
]
1.7.2.8. Schedule
接口描述:根据ScheduleInfo实例描述的调度信息指导生成后端的算子代码。
接口定义:
def Schedule(topo=None)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| topo | list | 是 | ScheduleInfo实例,包含执行顺序以及mem_scope、core_bind之类的调度信息。 |
返回值:
调度后的IRModule
调用示例:
with Target("stc_tc"):
mod = Schedule(graph_schedule)(mod)