3. 希姆计算手动图调度方案设计指南
3.1. 版本历史
| 版本 | 作者 | 日期 | 说明 |
|---|---|---|---|
| V1.2.0 | 希姆计算 | 2023-07-26 | 架构调整和编辑优化。 |
| V1.1.0 | 希姆计算 | 2023-04-06 | 架构调整和编辑优化。 |
| V1.0.0 | 希姆计算 | 2022-01-20 | 初始对内版本。 |
3.2. 概述
TensorTurbo支持自动图调度和手动图调度,本文介绍手动图调度相关的设计思路、实现方式、示例。
整体来说,流程如下:
设计手动图调度方案。
通过希姆计算提供的手动图调度接口,写出手动图调度方案的代码实现。
使用实现的手动图调度方案。
验证图调度效果。
3.3. 方案设计考虑因素
在设计图调度方案时建议充分考虑以下因素:
模型的网络结构:不同模型包含的算子、计算逻辑等可能存在差异,需要了解其网络结构,才能推导出合理的分组策略。例如,ResNet50在计算过程中靠后stage的output size不断减半,则可以寻找output size减半附近的节点作为分组边界,更有可能设计出符合内存占用要求的策略。
数据量:数据量直接影响内存占用,需要结合输入的数据量和L1的容量,推导出合理的子图拆分策略。例如给定一个输入,如果单核就可以处理所有输入的数据,则无需拆分子图;如果需要多核,甚至单cluster的所有核都无法处理输入的数据,则需要根据内存占用情况拆分子图,分批处理输入的数据。
局部性和时间步骤的平衡:分批处理输入的数据可以保证计算结果常驻L1/LLB,但也可能增加时间步骤,因此需要同时评估局部性和时间步骤,推导出最佳平衡点并实际验证调度效果,才能确定最优的图调度策略。
3.4. 方案设计流程
说明:图调度方案相关的内容有一定理解门槛,建议您先了解下 希姆计算基本概念。
您可以参考以下步骤设计图调度方案,但并非所有的图调度方案都必须包括所有步骤,请根据模型的实际情况合理取舍:
取较小的batch size计算内存占用,一般取
batch_size = 1。以STCP920支持的数据类型FP16为例介绍,FP16对应的内存占用计算公式:内存占用(KiB) = 参数量×2÷1024。算子分组。根据模型的特点,选择合适的位置作为划分点,将整个网络中连续的、空间占用相似的算子划分为一组。
设计group切分策略。如果某个group的内存占用较大,超过单核上的L1存储空间的大小,则无法用单核完成一条样本的推理任务,需要为该group指定合适的切分轴和切分因子,将group切分为多个subgroup,通过多核配合完成推理任务。
预估最佳batch size。为充分利用硬件资源,基于算子分组、group切分得到新的计算图考量各阶段的内存占用大小,预估出一个硬件利用率尽量高的batch size。
设计mem_scope策略。基于新的计算图以及预估的batch size,确定中间结果的存储位置。如果L1上可以存储所有中间结果,则无需溢出至LLB;如果L1上无法存储所有中间结果,则需要溢出到LLB上从而留出更多的L1存储空间,这样虽然会带来额外的数据搬运,但可以通过计算调度实现L1/LLB之间的数据搬运和L1上的计算并行,掩盖数据搬运耗时。
设计core_bind策略。对在非batch轴进行切分的算子组,指定其绑核方案,并调整其结果的存储层级。汇总不同核间的数据时,主要的考量因素是尽量减少核间搬运。
完成计算调度。综合考虑前述步骤得到的batch size、group切分、mem_scope、core_bind信息,排布出优化后的计算顺序。
说明:为一个模型从头开始设计全新的图调度方案,要求开发者熟悉模型特点以及TensorTurbo编译过程。为降低使用门槛和成本,您也可以利用TensorTurbo提供的自动图调度功能。具体来说,在编译模型时采用自动图调度,并通过STC-DDK工具导出重要阶段的Relay IR,了解对应的算子分组、group切分等策略,然后基于自动图调度方案进一步调优。详细用法,请参见希姆计算STC_DDK使用说明。
为方便您理解通用步骤,下文分别以DeepFM、BERT-Base、ResNet-50为例,演示图调度方案的设计过程。
说明:示例中的图调度方案是从分析模型特点的角度得到的,实际效果需要运行验证,并根据实际情况进行必要的调整,例如batch size等。
3.5. 方案实现流程
实现图调度方案时,您需要从具体模型的网络结构出发,通过我们提供的API对原计算图进行算子分组、子图拆分、算子调度等操作,保证各算子的输入、输出、中间结果数据可以常驻L1/LLB。
对STCP920来说,不同模型在调度流程上类似,都是调用TensorTurbo提供的手动图调度接口完成索引、算子分组、子图拆分、算子调度等操作。一般来说,进行手动图调度的流程如下:
接收IRModule作为输入。
如需为算子设置唯一的名称,调用
SetSpanName。索引:索引主函数中可以在NPU上执行的NPU Kernel函数,并索引这些NPU Kernel函数中的算子。
NPU Kernel函数索引:索引主函数中的NPU Kernel函数,返回由NPU Kernel函数组成的list,顺序按主函数中DAG后序遍历。NPU Kernel函数用于表示在NPU上执行的计算子图,NPU Kernel函数之外的部分则在CPU上执行。
tb.relay.graph_schedule.GetNPUSubFunctions(function)
算子索引:索引NPU Kernel函数中的算子,返回算子组成的dict,您可以从dict中找到输入function中的每个算子,其中key为算子名称,value为一类算子的list,顺序存放了输入function中的每个算子,例如
{"add": [add_op0, add_op1...], "conv2d": [conv0, conv1...], ...}。dict中算子顺序按DAG上的深度优先后序遍历,而非实际的计算顺序。在Relay IR中,只存在DAG表示算子之间的数据依赖关系,并没有实际确定的计算顺序**。**说明:IR变换Pass会导致之前索引到的算子失效,在经过优化等可能会改变Relay IR的操作后,需要重新获取新的算子索引。
tb.relay.graph_schedule.ListOps(function)
算子分组:在图调度中,group代表一个多输入、单输出的DAG,描述整网计算图中一个子图,例如将具有相似内存占用的block分为一组,将拆分逻辑、调度参数相同的算子分为一组等。分组后各group作为独立的调度单元,视为一个整体对其内部所有算子进行调度,简化后续的子图拆分等操作。
将指定输入节点、输出节点中间的算子划分为一个Group。
#描述分组策略 tb.relay.graph_schedule.Group(output, list[input])
对Group进行代码变换,将子图的信息保存到Relay IR上并封装成函数,后续以调用函数的形式执行子图中的计算。
#执行分组操作 tb.relay.graph_schedule.GroupOps(list[group])
调用
SplitGroups将每个group切分为多个同构的subgroup。 子图拆分:通过合适的拆分维度和拆分因子将子图拆分为更小规模的计算,保证该子图的计算都可以在L1上完成,提高局部性,即输入输出和中间结果的大小都不超过L1的大小限制。子图拆分必须保证Group内所有算子均可以独立完成计算,各部分之间不会相互影响。拆分维度目前仅支持batch,即将输入拆分为几个batch完成计算。 拆分后每个group形成一个或多个subgroup,group对应的函数前后会自动添加split、concat算子,完成拆分子图、汇总计算结果。拆分维度目前仅支持batch,即将输入拆分为几个batch完成计算。例如,假设输入为16张图片,group的拆分因子为8代表需要分8个batch完成计算,单次可处理2张图片;group的拆分因子为1代表1个batch即可完成计算,单次就可以处理全部16张图片。说明:如果内存占用超过L1的容量,需要从group粒度和拆分因子考虑调整。group粒度越细,包含的算子越少,可能涉及的计算规模越小;拆分因子越大,每个子图需要计算的数据规模越小。
#调用SplitGroups切分group后自动插入了split和concatenate算子,因此需要再次调用SetSpanName(如需为算子设置唯一的名称)和ListOps获取最新的算子列表。 tb.relay.graph_schedule.SplitGroups(dict{group : split_factor})
说明:调用
SplitGroups切分group后自动插入了split和concatenate算子,因此需要再次调用>SetSpanName(如需为算子设置唯一的名称)和ListOps获取最新的算子列表。调用
ScheduleInfo为各subgroup设置输出节点的调度信息,包括mem_scope和core_bind。 算子调度:为计算图中的所有子图以及未分组算子(如有)指定计算顺序、输出数据存储位置、计算绑定核的属性。合理的算子调度可以减少时间步骤和核间数据传输,最大化利用硬件资源。创建调度规则。存在多个Group时,需要为每个Group指定一个ScheduleInfo结构,形成一个ScheduleInfo list,其中ScheduleInfo的顺序即计算顺序。
tb.relay.graph_schedule.ScheduleInfo(op_or_group, mem_scope, core_bind)
| **参数** | **类型** | **说明** |
| --------- | -------- | ------------------------------------------------------------ |
| mem_scope | IntEnum | Group/算子输出数据的存储位置,可选值:NPUMemScope.DDR、NPUMemScope.LLB、NPUMemScope.L1。您需要仔细考虑所有计算结果的存储位置,保证中间结果的不会超过L1、LLB的容量限制。如果指定的mem_scope不合理,可能会导致编译器后端存储分配失败。 |
| core_bind | NDArray | group/算子输出数据在L1上的核间分布。例如[[0, 1], [2, 3], [4, 5], [6, 7]],表示拆分为4份,分别输出在[0, 1]、[2, 3]、[4, 5]、[6, 7]核上,所有核的数据汇总起来才构成了完整的结果。 |
在汇总中间结果时可能有多种方案可选,主要的考量因素是尽量减少核间搬运,再进一步考虑到NOC网络的拓扑结构,可以找到一种对NOC网络带宽需求最小的最优分配方案。
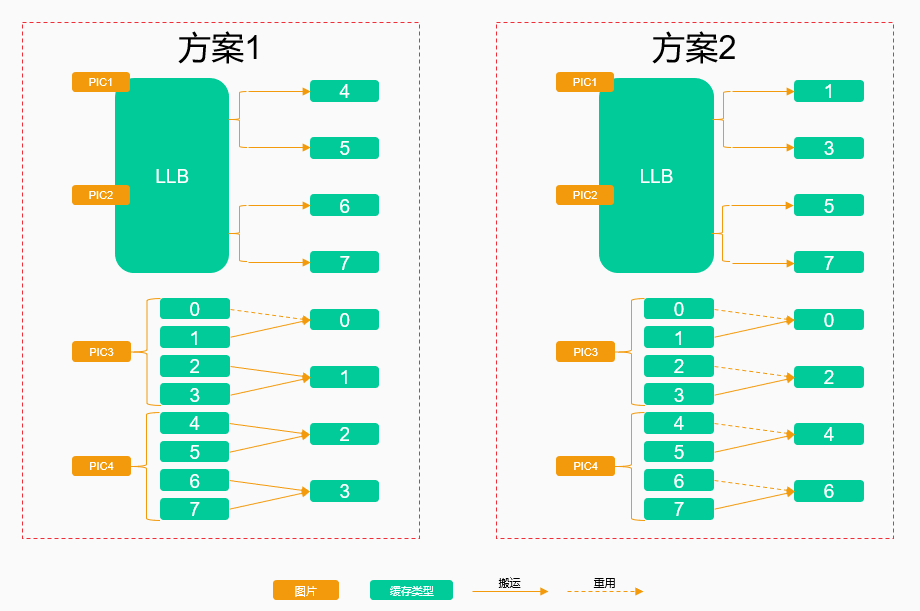
还是以ResNet50为例,假设PIC1、PIC2的中间结果缓存在LLB上,PIC3、PIC4的中间结果缓存在L1上,如果PIC3使用了0 ~ 3核,PIC4使用了4 ~ 7核,示例方案如下:
- 方案1:按核的index顺序搬移,需要进行7次核间搬运。
- 方案2:重用了4个核上的数据,仅需要4次核间搬运,该方案明显更优。

重新组织IR,将每个Group的ScheduleInfo保存在IR上,用于指导生成后端的算子代码,返回调度后的IRModule。
tb.relay.graph_schedule.Schedule(list[ScheduleInfo])
设计出图调度方案后,还需要看实际运行时是否达到了预想的效果。您可以通过TensorTurbo支持的Config
tb.dump_graphschedule导出模型编译过程中图调度典型阶段的Relay IR,并通过STC_DDK提供stc_ddk.scheduleviewer命令一键解析成可以在Netron中可视化查看的JSON文件,直观地验证不同图调度方案对模型编译结果的影响。说明:
tb.dump_graphschedule以及更多TensorTurbo支持的Config的说明,请参见希姆计算TensorTurbo使用说明中的Config支持章节。
3.6. 方案使用流程
在编译模型时,通过编译接口tb.relay.backend.build_module的schedule参数指定使用代码实现的手动图调度方案。
基于tvm、tb提供的接口,针对单个模型启用手动图调度的示例代码如下:
# 导入依赖的模块
import onnx
import tvm
import tb
import numpy as np
...
# 导入模型文件
model = onnx.load("model.onnx")
mod, params = tvm.relay.frontend.from_onnx(model)
...
# 配置编译参数,例如dump中间文件等。
config={
"tb.dump_graphschedule": True
}
...
# 编译模型
with tvm.transform.PassContext(
config=config
):
...
tb_mod = tb.relay.backend.build_module(
mod,
params,
"stc_tc",
target,
schedule=tb.kernel.schedule.resnet50_schedule,
)
...
# 导出可执行文件
tb_mod.export_library("./resnet50_manualschedule.stcobj")
...
# 执行模型,使用随机数作为输入
graph_exec = tb.kernel.Executor.load_from_stcobj("./resnet50_{schedulemode}.stcobj")
input_data_stc = {"input_1_0" : input_data["input_1_0"].astype("float16")}
np.save("input_1_0.npy", input_data["input_1_0"].astype("float16"))
graph_exec.set_input(input_data_stc)
stc_out = graph_exec()[0]
print("=============== stc out ====================")
print(stc_out)
...
3.7. 方案示例
3.7.1. DeepFM图调度方案
3.7.1.1. 分析模型特点
DeepFM是面向推荐的经典模型,其中包括了FM Layer(Factorization Machine Layer)和隐藏层(Hidden Layer),底部共享相同的input。FM Layer用于抽取低阶特征,Hidden Layer为DNN,用于抽取高阶特征。
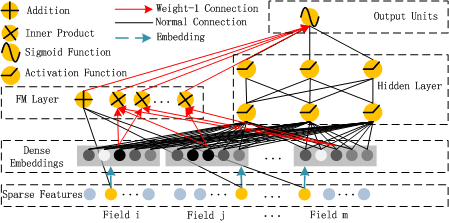
DeepFM输入特征,经过数据预处理后转化为包含{feat_index,feat_value}的dict,feat_index和feat_value各占一份空间,再结合batch_size,则大小为batch_size×field_size×2。
FM一次项部分根据feat_index查找对应的一次项因数,得到对应的feature_bias。
除输入特征外,DeepFM中主要涉及四个权重:
weights['feature_bias']:维度是[self.feature_size, 1]。存储对特征的一维交叉计算,对应FM公式中的一维计算部分,对每个特征附加长度为1的权重。
weights['feature_embeddings'] :维度是[feature_size, embedding_size]。存储每个feature的embedding表示(即每个feature的向量化结果),feature_size是总的特征数量。embedding转换相当于一个全连接层,将一个特征转换为一个向量。
weights['layer_0']:维度是(last_layer_neuron_num, current_layer_neuron_num),对应DNN中神经元的权重部分,这部分存储在Weight Buffer中,不占用Data Buffer。
weights['bias_0']:维度是(1, current_layer_neuron_num),对应DNN中的偏置部分,这部分存储在Weight Buffer中,不占用Data Buffer。
假设选定的预训练模型中,field_size = 39、feature_size = 259、embedding_size = 8,则FM一次项、FM二次项、DNN部分的结构及输出shape如下图所示:
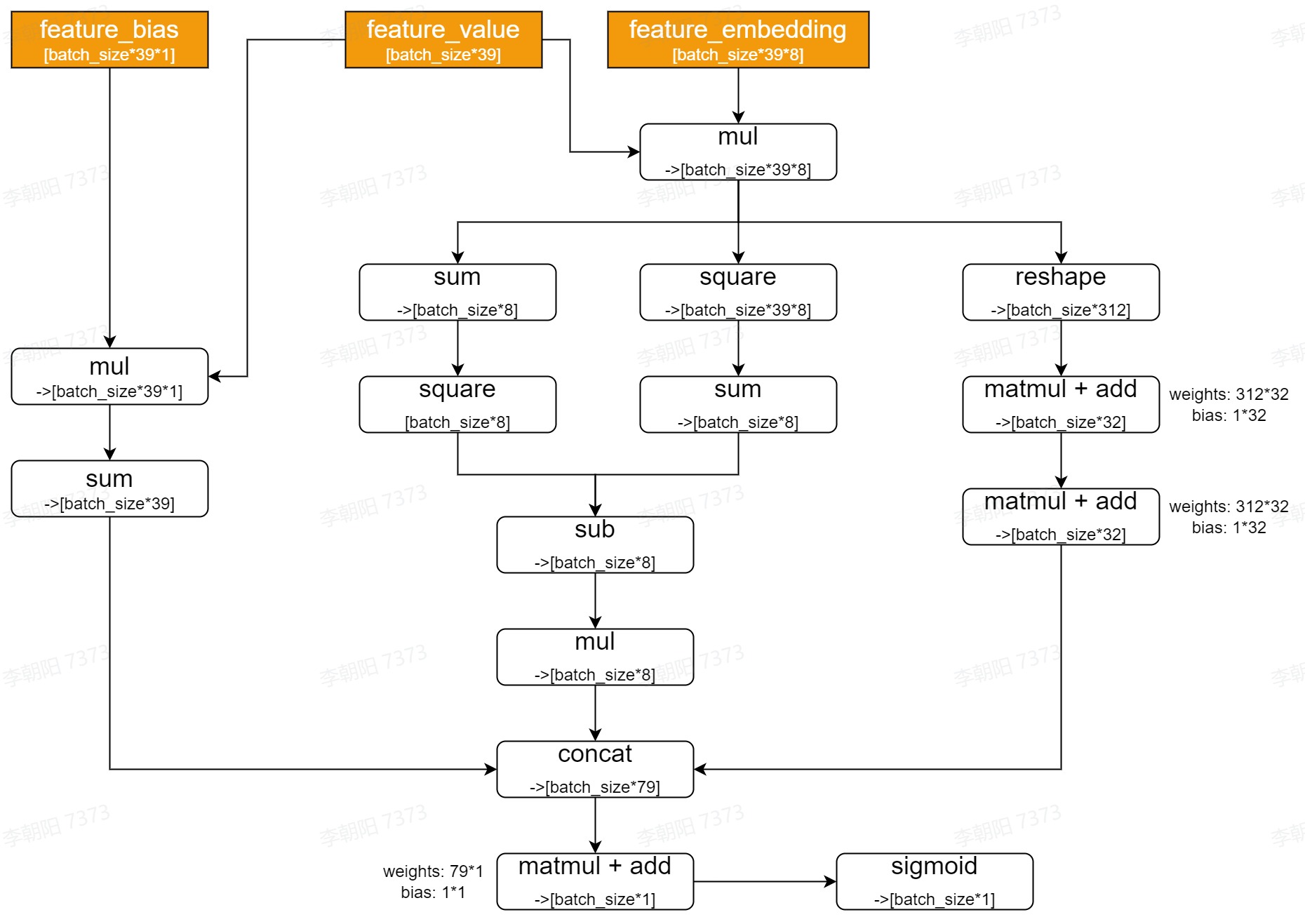
假设batch_size = 1,则计算过程中直接影响内存占用大小的输出shape分别为:
input shape:1×39×1(feature_bias)、1×39(feature_value)、1×39×8(feature_embedding)
middle shape:1×39×8(mul)、1×39×1(mul)、1×8(sum)、1×39×8(square)、1×312(reshape)
output shape:1×1(matmul+add)
3.7.1.2. 设计图调度方案
图调度方案的参考设计思路如下:
取最小batch size(
batch_size = 1)计算内存占用。由内存占用计算公式得到输出shape对应的内存占用大小约为:input size + middle size + ouput size = (390×2÷1024) + (990×2÷1024) + (1×2÷1024) = 2.7KiB。算子分组。DeepFM的数据集很小,对应训练出来的模型也很小,L1存储空间足够执行整个计算过程,可以简单地将所有算子划分到一个group。
设计group切分策略。L1存储空间足够执行整个计算过程,不需要进行group切分。
预估最佳batch size。单次计算过程共占用2.7KiB,则单核的1MiB Data Buffer向下取整可处理379(1024÷2.7)条样本,继续按64对齐向下取整为320条样本,因此单cluster可处理320×8条样本,即取batch size为320×8。
设计mem_scope策略。无需特别的mem_scope设计,全部在L1上完成,计算完成后结果直接传回DDR。
设计core_bind策略。无需特别的core_bind设计。
完成计算调度。无需特别的计算调度。
3.7.2. BERT-Base图调度方案(max_seq_len = 128)
3.7.2.1. 分析模型特点
BERT-Base是面向NLP的经典编码预训练模型,其中采用了Multi-Head Attention结构,在编码句子中的单词或字符时兼顾前后出现的信息,从而获得更好的编码效果。BERT-Base的整体网络结构如下:
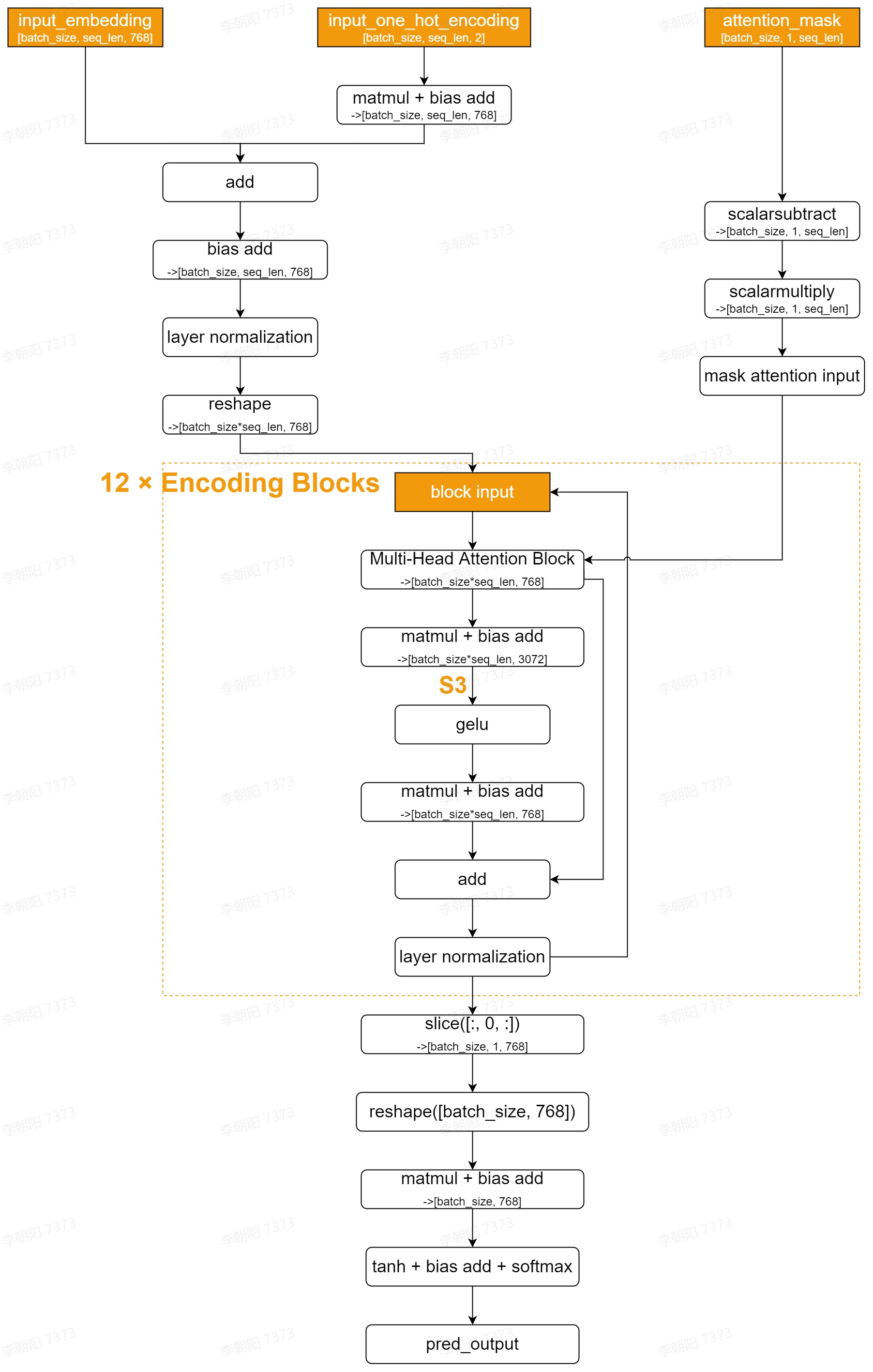
其中,每个Encoding Block中Multi-Head Attention Block的网络结构如下:
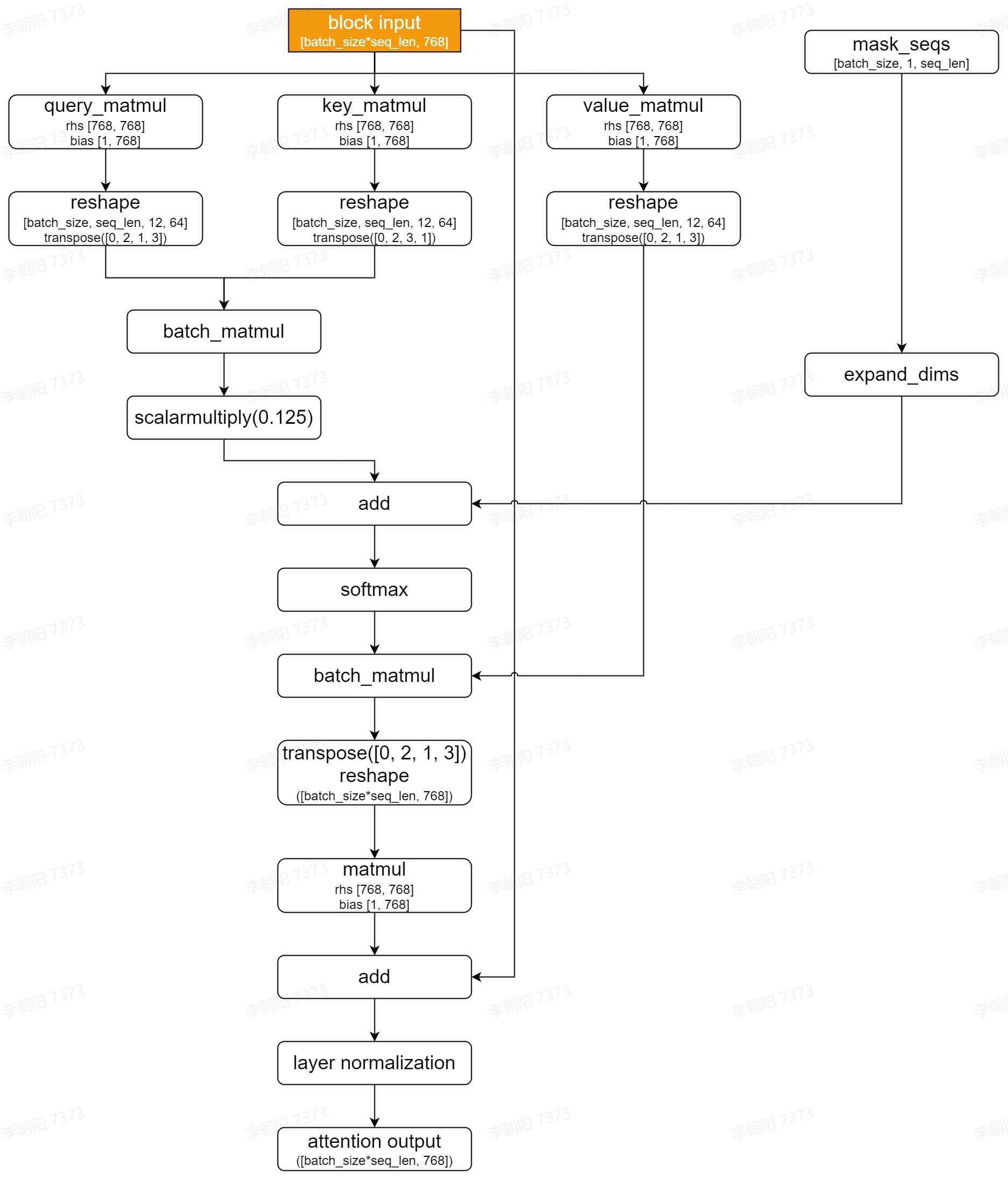
由BERT-Base的网络结构可知,其计算过程可以大致分为Preprocess阶段、12个Encoding Block、Postprocess阶段。在整个计算过程中,直接影响内存占用大小的输出shape分为三类:
S2:Multi-Head Attention Block中的第一个batch matmul处的输出,S2为[batch_size, 12, seq_len, seq_len]。具体位置,请见Multi-Head Attention Block的网络结构图中的标记。
S3:Multi-Head Attention Block后的第一个全连接层的输出,S3为[batch_size, seq_len, 3072]。具体位置,请见BERT-Base的整体网络结构图中的标记。
S1:其他大部分位置的输出,S1为[batch_size, seq_len, 768]或更小。
可见在整个计算过程中,输出shape的变化为S1 - S2 - S3 - S1。内存占用呈先增后减的趋势,具有典型的菱形特征,因此针对该特征进行菱形调度。简单来说,围绕三类输出shape以及最大句子长度(max_seq_len)计算最大内存占用,将连续的、内存占用相似的算子分到一组,并根据处理单个句子所需的核数,对应确定group切分策略以减少单次计算的内存占用,避免计算过程中数据溢出到低速缓存。
3.7.2.2. 设计图调度方案
以max_seq_len = 128为例,图调度方案的参考设计思路如下:
取较小的batch size(
batch_size = 1)计算内存占用。由内存占用计算公式得到输出shape对应的内存占用大小为:S1 size:1×128×768×2÷1024 = 192KiB
S2 size:1×12×128×128×2÷1024 = 384KiB
S3 size:1×128×3072×2÷1024 = 768KiB
算子分组。从整个网络看,可以用Encoding Block作为划分点;从单个Encoding Block看,可以用matmul作为划分点。
Encoding Block前后的部分内存占用变化不大,且需要在L1上存储的数据块的数量和尺寸都不大,因此可以将Encoding Block前后的部分各划分为一个group,标记为Pre_encoding group和Post_encoding group。
Encoding Block内的Multi-Head Attention Block部分,各类matmul计算可以自然地分别划分为一个group,标记为Encoding group 0、Encoding group 1、Encoding group 2、Encoding group 3、Encoding group 4。
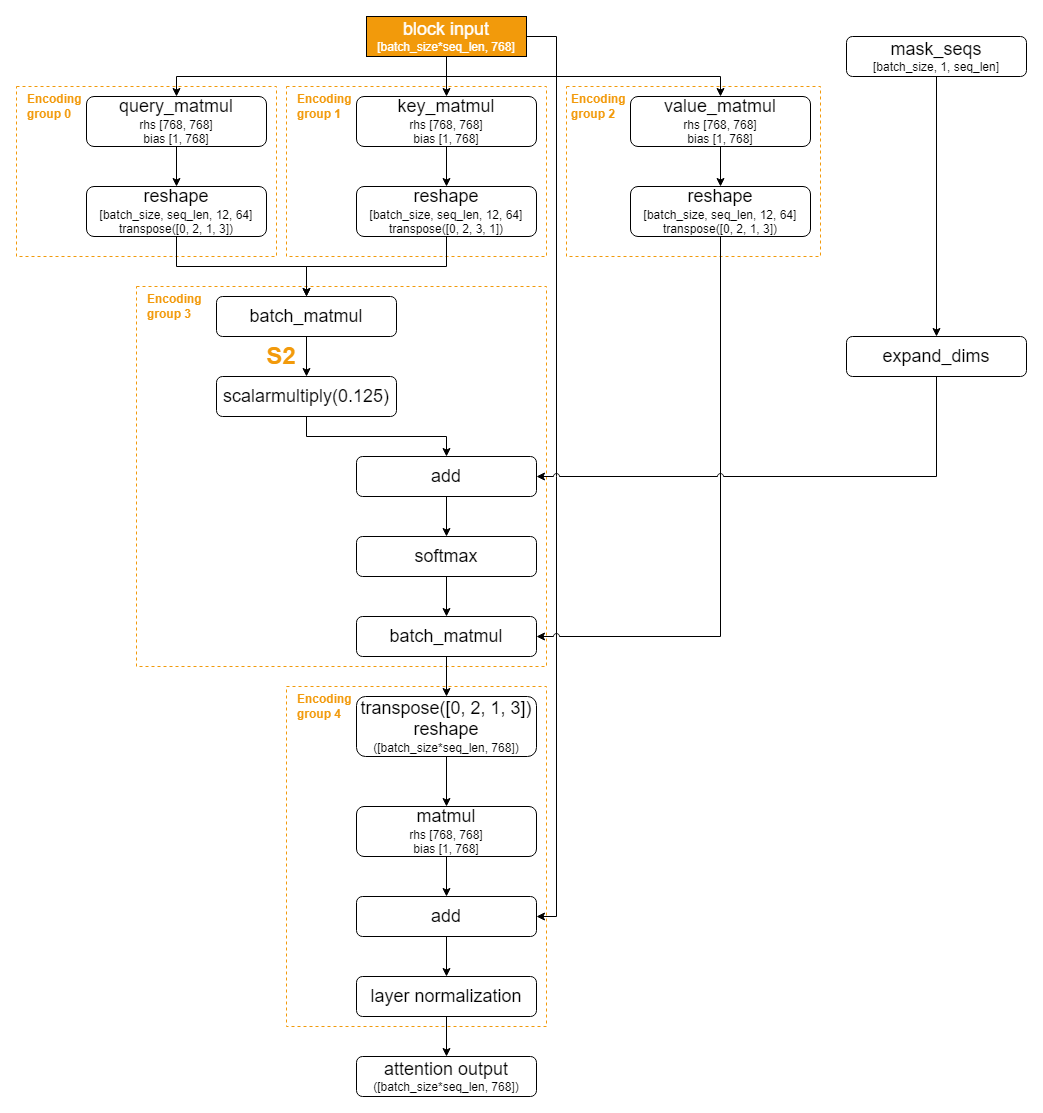
Encoding Block内Multi-Head Attention Block之后的部分,包括两个matmul在内的剩余算子划分为一个group,标记为Encoding double matmul group。
设计group切分策略并预估最佳batch size。由于最大的S3 size为768KiB,1核正好可以完成1条样本的推理任务,即8核可以完成8条样本的推理任务,因此取
batch_size = 8,且无需做group切分。说明:如果max_seq_len取更大的值,导致了单核无法完成一个句子的推理任务,就必须进行group切分。例如
max_seq_len = 256时,S2 size和S3 size均为1536KiB,超过了单核的处理能力,就需要多核配合完成任务,设计对应的mem_scope、core_bind,并完成计算调度。设计mem_scope策略。无需特别的mem_scope设计,全部在L1上完成,计算完成后结果直接传回DDR。
设计core_bind策略。按batch轴等分即可。
完成计算调度。根据前述步骤得到的batch size、group切分、mem_scope、core_bind信息,可以得到如下调度信息表:
| group(batch_size = 8) | split | core_bind shape | mem_scope |
|---|---|---|---|
| Pre_encoding group | 1 | [8, ] | L1 |
| Encoding group 0 | 1 | [8, ] | L1 |
| Encoding group 1 | 1 | [8, ] | L1 |
| Encoding group 2 | 1 | [8, ] | L1 |
| Encoding group 3 | 1 | [8, ] | L1 |
| Encoding group 4 | 1 | [8, ] | L1 |
| Encoding double matmul group | 1 | [8, ] | L1 |
| Post_encoding group | 1 | [8, ] | DDR |
进而可以得到计算调度示意图,所有group的计算均顺序执行,且过程中core_bind未发生变化,因此整 个计算图可以合并成如下形式表示调度逻辑。
3.7.3. ResNet-50图调度方案(input_size = 224×224×3)
3.7.3.1. 分析模型特点
ResNet-50是面向CV的经典卷积神经网络模型,其中采用了Residual结构,确保梯度不会随着网络深度的增加而消失。ResNet-50的整体网络结构如下,以input_size = 224×224×3为例,取较小的batch size(batch_size = 1)计算内存占用。由数据类型为FP16,可知内存占用计算方式:内存占用(KiB) = 参数量×2÷1024。
说明:output size列中未包含的通道数,体现在了参数量(最大内存占用)列中。
| layer name | output size | 50 layer | 下采样位置 | 参数量(最大内存占用) |
|---|---|---|---|---|
| Conv1 | 112×112 | 7×7, 64, stride 2 | 做一次下采样。 | 112×112×64 (1568KiB) |
| Conv2_x | 56×56 | 3×3 max pool, stride 2$$$$\begin{bmatrix}1\times1,&64\3\times3,&64\1\times1,&256\ \end{bmatrix} \times 3 $$$$ | 在max pool处做一次下采样。 | 56×56×256 (1568KiB) + 56×56×256 (1568KiB) = 3136KiB |
| Conv3_x | 28×28 | $$$$\begin{bmatrix}1\times1,&128\3\times3,&128\1\times1,&512\ \end{bmatrix} \times 4 $$$$ | 在第一个3×3卷积处做一次下采样。 | 下采样前:28×28×512 (784KiB) + 56×56×256 (1568KiB) = 2352KiB下采样后:28×28×512 (784KiB) + 28×28×512 (784KiB) = 1568KiB |
| Conv4_x | 14×14 | $$$$\begin{bmatrix}1\times1,&256\3\times3,&256\1\times1,&1024\ \end{bmatrix} \times 6 $$$$ | 在第一个3×3卷积处做一次下采样。 | 下采样前:14×14×1024 (392KiB) + 28×28×512 (784KiB) = 1176KiB下采样后:14×14×1024 (392KiB) + 14×14×1024 (392KiB) = 784KiB |
| Conv5_x | 7×7 | $$$$\begin{bmatrix}1\times1,&512\3\times3,&512\1\times1,&2048\ \end{bmatrix} \times 3 $$$$ | 在第一个3×3卷积处做一次下采样。 | 下采样前:7×7×2048 (196KiB) + 14×14×1024 (392KiB) = 588KiB下采样后:7×7×2048 (196KiB) + 7×7×2048 (196KiB) = 392KiB |
| 1×1 | average pool, 1000-d fc, softmax |
从ResNet-50的网络结构可知,其计算过程可以大致分为6个阶段,前5个阶段的主体为一次或多次卷积运算,过程中output size不断减小,内存占用呈递减趋势,具有典型的倒金字塔特征,因此针对该特征进行倒金字塔调度。简单来说,围绕各阶段的output size计算最大内存占用,将连续的、内存占用相似的算子分到一组,并根据处理单张图片所需的核数,对应确定group切分策略以单次计算减少内存占用,避免计算过程中数据溢出到低速缓存。
说明:ResNet-50采用了Residual结构,因此在计算最大内存占用时,需要同时考虑原始+Residual部分。
在高速缓存容量有限的前提下,计算过程中靠前的stage数据量大,单cluster可以处理的图片少;靠后的stage数据量小,单cluster可以处理的图片多。在设计图调度方案时:
从内存占用考虑,计算每个stage中的output size,将内存占用相似的block划分到同一组。
Resnet50的核心算子为conv2d,残差block的结构相似,因此对应的拆分逻辑也可以相同。
包含残差分支的block的内存占用大,需要拆分。这些block都以add算子结束,因此可以取add算子作为分组边界。
3.7.3.2. 设计图调度方案
以input_size = 224×224×3为例,图调度方案的参考设计思路如下:
取较小的batch size(
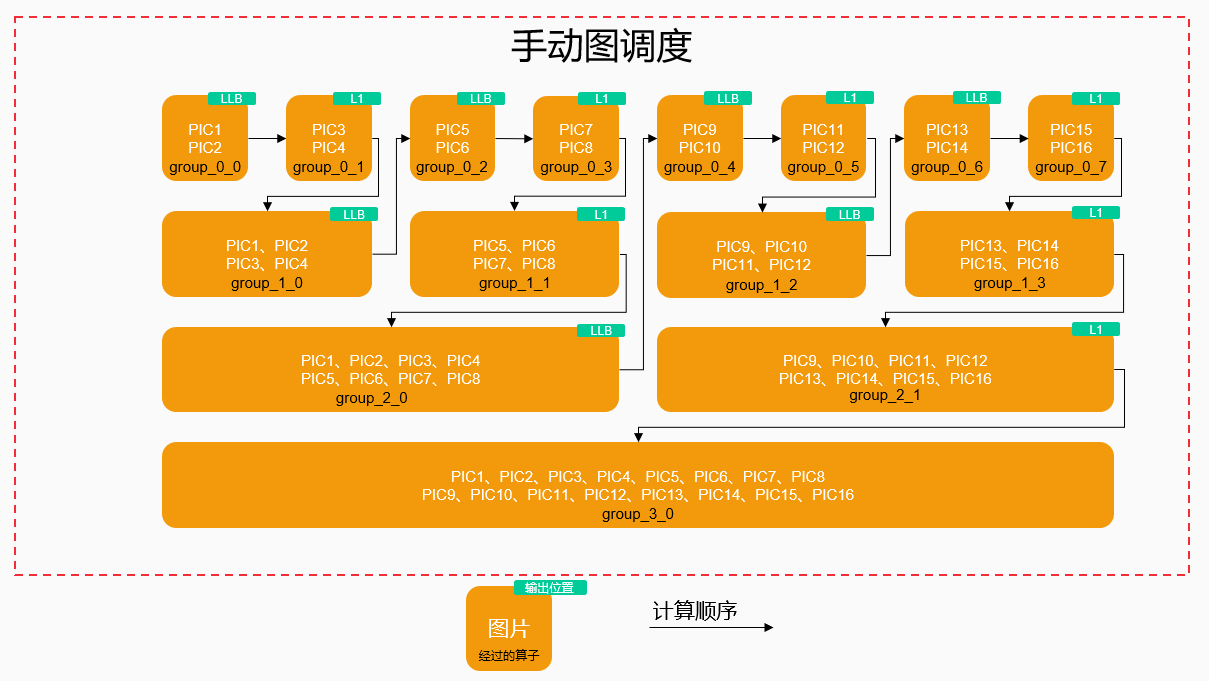
batch_size = 1)计算内存占用。计算过程中,图片的output size不断减小,但通道数不断增加,因此在计算内存占用大小时要同时考虑output size和通道数的变化。算子分组。从整个网络看,可以用下采样的位置作为划分点。
开始至Conv3_x下采样前,内存占用最大时需要4核处理1张图片,因此划分为一个group,标记为group_0。如果需要3核处理1张图片,单cluster的8核最多也只能处理2张图片,因此不如直接分配4核。
Conv3_x下采样后至Conv4_x下采样前,内存占用最大时需要2核处理1张图片,因此划分为一个group,标记为group_1。
Conv4_x下采样后至Conv5_x下采样前,内存占用最大时需要1核处理1张图片,因此划分为一个group,标记为group_2。
Conv5_x下采样后至结束,内存占用最大时1核可以处理2张图片,因此划分为一个group,标记为group_3。
设计group切分策略并预估最佳batch size。由于在group_3中1核可以处理2张图片,即8核最多可以同时处理16张图片,为充分利用硬件资源,取
batch_size = 16。output size在group_0至group_4中是不断2倍递减的趋势,可以为每个group设置不同的切分因子,从而得到如下group切分策略:group_0的切分因子为2,切分为8个subgroup,标记为group_0_0 ~ group_0_7。
group_1的切分因子为4,切分为4个subgroup,标记为group_1_0 ~ group_0_3。
group_2的切分因子为8,切分为2个subgroup,标记为group_2_0 ~ group_0_1。
group_3的切分因子为16,不做切分,对应1个subgroup,标记为group_3_0。
设计mem_scope策略。在group_0 ~ group_2阶段,L1上无法存储16张图片的数据,需要溢出到LLB上从而留出更多的L1存储空间,这样虽然会带来额外的数据搬运,但可以通过计算调度实现L1/LLB之间的数据搬运和L1上的计算并行,掩盖数据搬运耗时。
设计core_bind策略。在group_0 ~ group_1阶段需要多核配合处理1张图片,必然需要汇总不同核间的数据,主要的考量因素是尽量减少核间搬运。例如,假设PIC1 ~ PIC2的中间结果缓存在LLB上,PIC3 ~ PIC4的中间结果缓存在L1上,其中PIC3使用了0 ~ 3核的L1,PIC4使用了4 ~ 7核的L1。下图方案1中按核的index顺序搬移,需要进行7次核间搬运,而方案2中重用了4个核上的数据,仅需要4次核间搬运。
完成计算调度。从开始单cluster的8核只能处理2张图片,到最后单cluster可以处理16张图片,内存占用变化较大,需要溢出到LLB上从而留出更多的L1存储空间。具体来说,处理完部分input后将中间结果溢出到LLB,然后继续处理一部分input,避免在output size较大的阶段将所有16张图片的数据存储在L1上,并在output size变小时将数据汇总回L1上。根据前述步骤得到的batch size、group切分、mem_scope信息,可以得到计算调度示意图如下:
3.7.3.3. 代码示例
ResNet50手动图调度方案的完整代码示例如下:
说明:需要自行设计方法,将手动图调度方案传递进去并在build_module时生效,例如TensorTurbo内置的
schedule=tb.kernel.schedule.resnet50_schedule。
def resnet50_schedule(mod, batch=16):
"""resnet50 schedule"""
# Graph scheduling primitives
func = GetNPUSubFunctions(mod["main"])[0]
ops = ListOps(func)
# Four-stage partition of resnet-50 graph
groups = [
Group([func.params[0]], ops["add"][15]),
Group([ops["add"][15]], ops["add"][31]),
Group([ops["add"][31]], ops["add"][55]),
Group([ops["add"][55]], ops["nn.softmax"][0]),
]
mod = GroupOps(groups)(mod)
# Group split
mod = SplitGroups(
{
groups[0]: batch // 2,
groups[1]: batch // 4,
groups[2]: batch // 8,
groups[3]: batch // 16,
}
)(mod)
# Schedule groups
# Topological order of subgroups
ops = ListOps(GetNPUSubFunctions(mod["main"])[0])
graph_schedule = [
ScheduleInfo(ops["split"][0], NPUMemScope.DDR, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][0], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][1], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][0], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][0], NPUMemScope.LLB, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[0][2], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][3], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][1], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][1], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(ops["concatenate"][2], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[2][0], NPUMemScope.LLB, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[0][4], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][5], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][3], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][2], NPUMemScope.LLB, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[0][6], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][7], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][4], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][3], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(ops["concatenate"][5], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[2][1], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(ops["concatenate"][6], NPUMemScope.L1, [7, 6, 5, 4, 3, 2, 1, 0]),
ScheduleInfo(groups[3][0], NPUMemScope.DDR, [7, 6, 5, 4, 3, 2, 1, 0]),
]
with Target("stc_tc"):
mod = Schedule(graph_schedule)(mod)
return mod