5. 希姆计算精度分析工具使用说明
5.1. 版本历史
| 文档版本 | 对应软件版本 | 作者 | 日期 | 描述 |
|---|---|---|---|---|
| V1.5.2 | STCRP V1.5.1 | 希姆计算 | 2024-01-15 | 基于STCRP V1.5.1验证文档内容。 |
| V1.5.1 | STCRP V1.5.0 | 希姆计算 | 2023-07-24 | 基于STCRP V1.5.0验证文档内容。 |
| V1.5.0 | STCRP V1.4.0 | 希姆计算 | 2023-04-06 | 增加--skip_keys、--force_compare参数 |
| V1.4.0 | STCRP V1.2.0 | 希姆计算 | 2022-11-30 | 添加性能统计信息,精度分析结果总表里额外添加多列指标。增加docker挂载目录内外不一致使用示例。 |
| V1.3.1 | TensorTurbo V1.8.0 | 希姆计算 | 2022-08-16 | 添加使用示例。 |
| V1.2.0 | TensorTurbo V1.6.0 | 希姆计算 | 2022-06-08 | 添加板卡支持。 |
| V1.1.0 | TensorTurbo V1.4.0 | 希姆计算 | 2022-04-26 | 修改用例,结果总表里添加两列结果。 |
| V1.0.0 | TensorTurbo V1.3.0 | 希姆计算 | 2022-03-31 | 初始版本。 |
5.2. 概述
精度分析工具可帮助您在整网精度调试时,快速定位精度问题的根因,提高精度分析效率。通过精度分析工具生成的网络模型在CPU与NPU运行的数据对比结果分析表,可快速定位出错误节点第一个出错位置以及该位置对应的数据,在表格中将显示其NPU与CPU上的数据。
同时,还提供精度对比失败算子的详细信息,包括精度对比失败发生位置的索引号以及在CPU和NPU上的索引位置的值。
此外,精度分析同时也提供获取整网性能数据的能力,获取整网中融合算子详细的性能信息,并详细显示图调度后融合算子每次运行的性能信息。
5.3. 使用限制
目前,精度分析工具存在以下使用限制:
仅支持融合算子输出的自动转储(dump)和获取性能数据的功能。
支持TensorFlow1.x网络模型、TensorFlow2.x网络模型和ONNX网络模型。
使用dump功能时,会导致网络运行性能下降。
5.4. 前提条件
使用精度分析工具前,需要安装以下依赖软件:
配套版本的STCRP 。
Python,且版本必须为Python3.6或Python 3.7 。
5.5. 安装步骤
精度分析工具以Python脚本的形式提供。您可以选择其中一种方式获取精度分析工具包,解压后按使用流程说明使用脚本。
从服务器上下载精度分析工具安装包,解压使用即可。
适用于Python 3.7的脚本:
$ wget --user=stcp_user --password=StcpDownload http://sources.streamcomputing.com/packages/stc-hpaa-1.12.0-py37.tar.gz $ tar -xvzf stc-hpaa-1.12.0-py37.tar.gz
适用于Python 3.6的脚本:
$ wget --user=stcp_user --password=StcpDownload http://sources.streamcomputing.com/packages/stc-hpaa-1.12.0-py36.tar.gz $ tar -xvzf stc-hpaa-1.12.0-py36.tar.gz
我们会提供一个tar包,其中包括了精度分析工具的Python脚本,解压使用即可。
$ tar xvf stc-hpaa-1.12.0-py37.tar.gz $ tree . ├── common.py ├── gen_dma_perf.py ├── run_dma_data_analysis.py ├── run_npu_data_analysis.py #获取网络模型基于NPU运行结果及性能分析脚本 └── run_precision_analysis.py #NPU和CPU精度分析处理脚本
说明:请联系希姆计算技术支持获取配套软件安装包。
5.6. 使用流程
5.6.1. 获取精度数据
使用
DUMP_MEMORY_PATH设置dump数据存放的目录,用于存放dump模型执行过程中的数据,基于dump数据分析出的NPU/CPU数据,以及精度对比结果。# 设置dump数据存放目录 $ export DUMP_MEMORY_PATH=${dump_dir_name} # 示例 $ export DUMP_MEMORY_PATH=/usr/share/stc_tb/hpaa_dump/test_1
注意:目标路径只能设置为绝对路径,且路径字符长度不超过50个字符。如果目标目录不存在,则会自动新建目录;如果目标目录已存在,则会自动删除整个目录后再自动新建。设置目录时,请多加注意。
如果在容器内使用精度分析工具,需要先在主机侧挂载一个目录供主机和容器传递数据,然后在容器内使用
DUMP_MEMORY_PATH设置目标目录,且目标目录必须使用挂载目录的子目录。挂载的目录在容器内与主机侧的目录绝对路径最好完全一致。# 先在host侧创建目录 $ mkdir -p /usr/share/stc_tb/hpaa_dump # 启动容器时,宿主机的目录路径与挂载到容器内的目录路径的绝对路径最好完全一致 $ docker run -it --privileged=true -v /usr/share/stc_tb/hpaa_dump:/usr/share/stc_tb/hpaa_dump ${image} /bin/bash # 设置dump数据存放目录为挂载目录下的子目录中 # 示例 $ export DUMP_MEMORY_PATH=/usr/share/stc_tb/hpaa_dump/test_1
说明:在容器内使用时,需要确保容器内用户对host上创建的挂载目录有读写权限。若在启动容器时,宿主机的目录路径与挂载到容器内的目录路径不一致时,处理方式可参考常见问题中的问题一。
运行网络模型用例。
运行需要精度分析的网络模型用例,具体示例可参考使用示例章节。
运行工具中的NPU数据分析脚本。
# 获取网络模型基于NPU运行结果 $ python3 stc-hpaa/run_npu_data_analysis.py
调用
tf_dump_fmap,onnx_dump_fmap接口获取网络模型在CPU上的输出数据。说明:接口使用说明可参考CPU**端数据dump接口使用说明章节。
运行精度分析脚本,获取NPU和CPU精度分析处理结果。
$ python3 stc-hpaa/run_precision_analysis.py
其中,
run_precision_analysis.py脚本,运行时可传入不同参数,获取不同结果文件。您可以使用-h,--help查看帮助信息中的可选参数,其中--atol、--rtol可设置阈值、--show_graph可获取错误节点的分析图,其他参数值不建议修改。可选参数说明:
| 参数选项 | 描述 | 是否建议修改 |
|---|---|---|
| -h,--help | 显示帮助信息并退出。 | / |
| --cpu_dir | CPU数据的存放目录。 | 否 |
| --npu_dir | NPU数据的存放目录。 | 否 |
| --node_runtime_filename | 存放每个节点的运行时刻,主要用来排序。 | 否 |
| --op_config_name | 每个节点的比较时候用的atol和rtol,默认是NA表示用全局的atol/rtol。特殊需求时使用。 | 否 |
| --diff_cnt | 最大导出的出错数据个数,默认值为128。 | 否 |
| --atol | 绝对误差阈值,默认值为0.005。脚本会根据绝对误差阈值的设置来统计误差超过该阈值的结果在全部结果中的占比。 | 是 |
| --rtol | 相对误差阈值,默认值为0.2,范围在[0.0 ~ 1.0]。脚本会根据相对误差阈值的设置来统计误差超过该阈值的结果在全部结果中的占比。 | 是 |
| --show_graph | 是否显示所有错误节点的分析图,取值含义: True:显示分析图。如果数据量大,绘图会比较耗时。 False:默认值,不显示分析图。 分析图包括以下类型: {op_name}_diff.png :错误数据对应的绝对误差和相对误差散点图。 {op_name}_diff_hist.png : 相对误差和绝对误差的直方图分布。 {op_name}_hist.png:CPU和NPU数据的直方图分布。 |
是 |
| --max_bins | 直方图最大bin数,默认值为128。 | 否 |
| --min_bins | 直方图最小bin数,默认值为1,范围为[1, max_bins]。 | 否 |
| --max_cores | 精度分析时用到最大核数,默认值为16。 | 否 |
| --map_node_dict | 人为给定的参考节点与NPU节点映射dict,内容示例 :'{"cpu_name":"npu_name","b":"2"}'。映射关系唯一性和正确性需得到保证。 | 否 |
| --force_compare | 精度分析时,是否对shape不一致但size一致的节点进行分析,默认值为False。 | 否 |
bash
# 示例
$ python3 stc-hpaa/run_precision_analysis.py --atol=0.005 --rtol=0.2 --show_graph=True
5.6.2. 获取性能数据
使用
DUMP_MEMORY_PATH设置dump数据存放的目录。详细步骤可参考使用流程中的获取精度数据的步骤一。
设置
DUMP_OP_PERF环境变量。# 设置DUMP_OP_PERF环境变量,其中: # 1表示只获取性能数据;2表示同时获取精度和性能数据 $ export DUMP_OP_PERF=${mode} # 示例 $ export DUMP_OP_PERF=2
注意:性能分析只能在真实板卡环境中运行。
运行网络模型用例。
运行需要性能分析的网络模型用例,具体示例可参考使用示例章节。
运行工具中的NPU数据分析脚本,获取节点每次运行的详细性能数据。
# 获取网络模型基于NPU运行结果 $ python3 stc-hpaa/run_npu_data_analysis.py
其中
run_npu_data_analysis.py脚本支持修改参数。您可以使用-h,--help查看帮助信息中支持的参数选项,其中--perf_all_nodes可显示所有融合算子perf信息,其他参数值不建议修改。参数描述如下:
| 参数选项 | 描述 | 是否建议修改 |
|---|---|---|
| -h,--help | 显示帮助信息并退出。 | / |
| --npu_dir | NPU数据的存放目录。 | 否 |
| --output_dir | NPU数据拼接后的存放位置。 | 否 |
| --perf_all_nodes | 是否显示所有融合算子perf信息。 - True:默认值,显示所有融合算子perf信息。 - False:不显示节点名中包含_span的节点。 |
是 |
| --node_runtime_filename | 存放每个节点的运行时刻,主要用来排序。 | 否 |
| --skip_keys | 忽略名字中包含关键字的节点。 | 否 |
| --map_node_dict | 人为给定的参考节点与NPU节点映射dict,内容示例 :'{"cpu_name":"npu_name","b":"2"}'。映射关系唯一性和正确性需得到保证。 | 否 |
| --exclude_node_list | 用户指定强行忽略的节点列表。 | 否 |
| --default_concat_dim | 分组信息缺失情况下,默认的拼接轴信息,默认值0,-1表示找第一个非1轴为拼接轴。 | 否 |
bash
# 示例
$ python3 stc-hpaa/run_npu_data_analysis.py --perf_all_nodes=False
5.7. 使用示例
5.7.1. 精度误差分析
5.7.1.1. 获取精度
将以deepfm网络为例,使用精度分析工具获取精度数据:
# 设置dump数据存放目录
$ export DUMP_MEMORY_PATH=/usr/share/stc_tb/hpaa_dump/test_1
# 运行deepfm网络模型
$ python -m pytest -s test_deepfm.py::test_deepfm
# 运行精度分析工具中的NPU数据分析脚本
$ python3 stc-hpaa/run_npu_data_analysis.py
# 获取网络模型在CPU上的输出数据
# get_deepfm_output为deepfm获取CPU上输出数据的脚本,示例脚本放在tensorturbo/tools/dump_memory/下
$ python3 ./export_model_node_examples/get_deepfm_output.py
# 运行精度分析脚本
$ python3 stc-hpaa/run_precision_analysis.py
最终对比结果生成在您指定的dump数据存放目录下,即设置的DUMP_MEMORY_PATH下,其中包含:
cpu文件夹:主要保存的是获取网络模型在CPU上的数据。数据文件是按照实际网络模型中的节点名称来命名,将名称中的 “/” 替换成 “_”。
dump_data文件夹:主要保存的是dump出来的16进制的数据。经过
run_npu_data_analysis.py脚本转成二进制形式并进行数据拼接,最终输出到npu文件夹。npu文件夹:主要保存的是获取网络模型在NPU上的数据,命名规则与cpu文件夹中一样。
result文件夹:主要保存的是最终对比分析结果。
check_skip.log:执行数据拼接前由于校验错误而被跳过的节点以及详细跳过信息。
compare_skip.log:执行CPU和NPU数据比对时被跳过的节点以及详细跳过信息。
concate_skip.log:执行数据拼接时出现错误而被跳过的节点信息。
consumer_map_dict.file:标准模型的当前节点和子节点关系表。
cpu_vs_npu.csv:CPU和NPU数据比较结果分析表。
dump_memory_nodename.log:dump数据中节点名(节点名未去重)。
invalid_out_nodename.log:dump数据中在标准模型中未找到的节点名。
node_runtime.file:节点运行时序文件。
op_config.csv:算子相对误差和绝对误差配置文件,用户设置后会按照指定的上限进行相应的精度比对分析判断。
{op_name}.csv:以算子名称命名的错误算子的详细错误信息。
说明:结果文件具体说明可查看附录中的结果文件说明章节。
若--show_grap设为True,则在result文件夹下还会显示以算子名称命名的错误算子的分析图:
{op_name}_diff.png:错误节点对应的绝对误差和相对误差散点图。
{op_name}_diff_hist.png:相对误差和绝对误差的直方图分布。
{op_name}_hist.png:CPU和NPU数据的直方图分布。
5.7.1.2. 分析结果
按照上述步骤获取精度后,分析误差节点的精度问题。
查看cpu_vs_npu.csv表中的节点误差。

选取第一个出现较大误差的节点,如果误差相差都不大,则选取相对误差较大的节点。再去看其对应的csv文件。例如,根据max_abs_err选取第一个出现较大误差的节点concat,查看concat.csv。
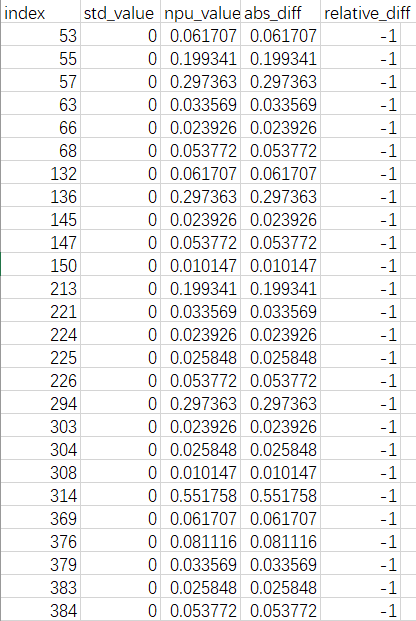
若遇到csv文件中无法显示完整的大批量错误数据并且是按照index排列,无法确定哪一个节点误差较大。可自行对比cpu文件夹与npu文件夹中的数据文件,分析精度误差的原因。
注意:网络模型在cpu和npu上的数据格式,数据格式可能存在NHWC或NCHW。对比时如果CPU与NPU上的数据格式不一致,需要先使用transpose函数改变数据排布。
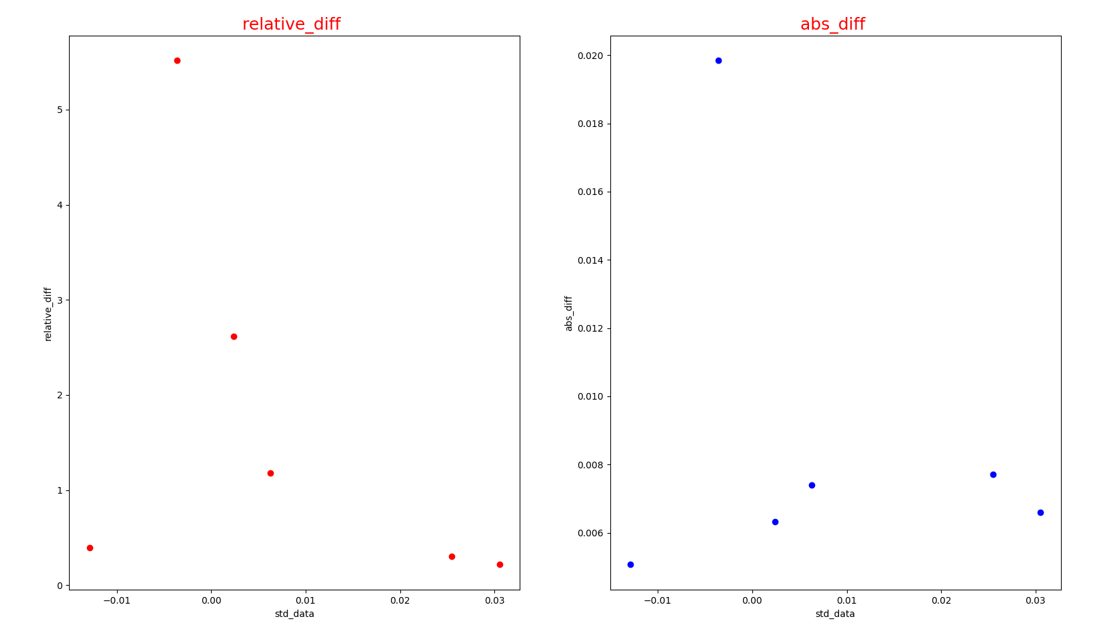
此外,若--show_grap设为True,可查看精度对比失败节点的分析图。
错误节点对应的绝对误差和相对误差散点图({op_name}_diff.png):
CPU和NPU数据的直方图分布({op_name}_hist.png):
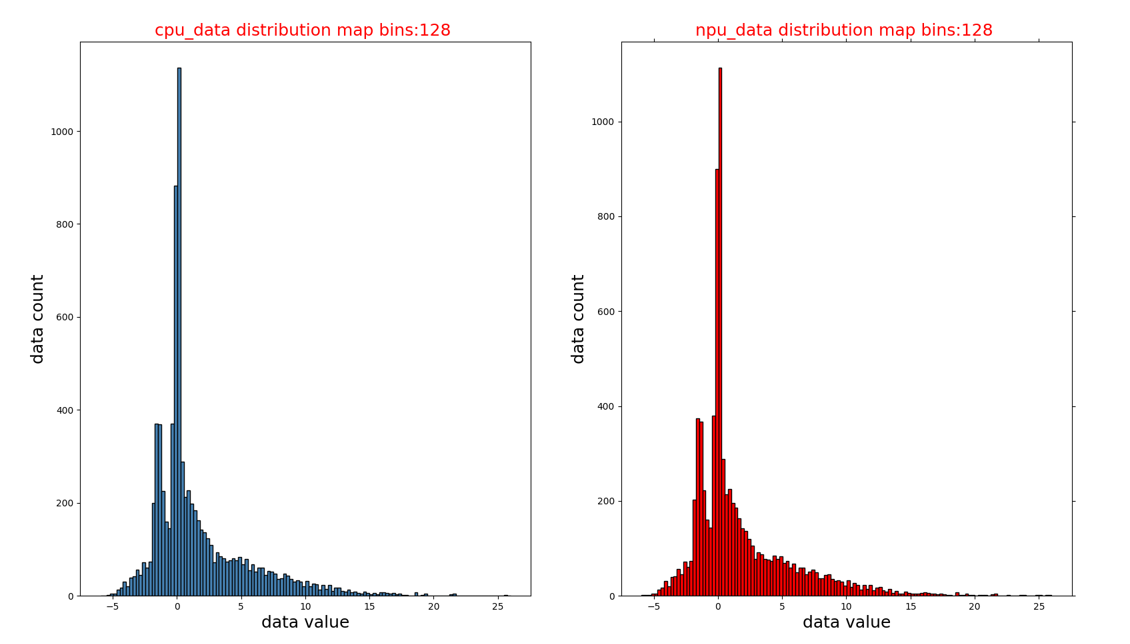
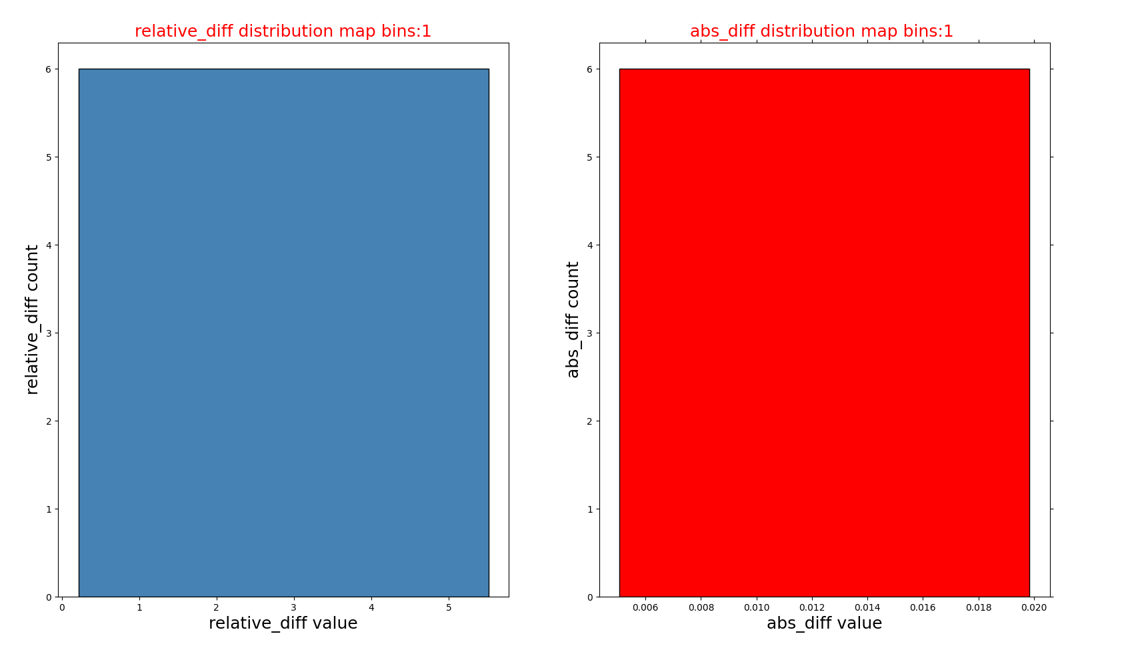
相对误差和绝对误差的直方图分布({op_name}_diff_hist.png):
5.7.1.3. 误差类型及判断方法
NPU每个节点计算输出的误差可以分为两类:
计算错误:由硬件或软件Bug问题导致的错误。
累积精度误差:由于在NPU上采用FP16计算,相对于CPU上使用FP32计算存在精度损失,并且这个精度损失逐层累积造成的误差。
根据dump出的NPU与CPU数据,分析每个dump节点的误差,并使用以下方法判断误差的类型:
统计每个节点输出的平均相对误差。按模型输入到输出的顺序排列节点,若从某个节点开始平均相对误差大幅提高,比如节点的输入位置相对误差小于0.1,而输出位置相对误差大于1,可以判断为该节点发生了计算错误;否则,该误差可能是累积精度误差。
计算NPU与CPU的dump数据的Pearson相关系数:
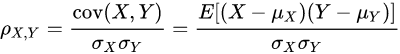
若从某个节点开始相关系数大幅减小,比如节点的输入位置相关系数大于0.9,而输出位置相关系数小于0.1,可以判断为该节点发生了计算错误;否则,该误差可能是累积精度误差。
分析误差的分布,如果误差在某个轴上明显分布不均,比如在H轴的前半部分误差较小,而后半部分误差较大,可以判断为该节点发生了计算错误;反之,若误差在所有轴上分布均匀,该误差可能是累积精度误差。下图是一个节点计算错误造成输出误差分布不均匀的例子:

5.7.1.4. 其他精度问题
CPU与NPU输出结果均存在NaN。
当发现CPU与NPU运行出来的结果都存在NaN的问题时,可考虑网络模型本身的问题,可能存在模型中算子的参数不合法的情况。
可能是算子参数为inf,使得与其他数字相乘会出错,导致结果都是NaN,此时应考虑算子问题。
可能是模型输入不合适,例如输入中包含负数,而网络模型中存在Log这一类的算子,经过该节点是会出现计算错误,使得CPU和NPU的运行结果为NaN。
CPU输出正常而NPU结果为NaN。
当发现CPU的输出正常而NPU运行出来的结果为NaN的问题时,可考虑是算子参数导致,其表现是中间输出结果超FP16范围(65504),通常两个大数相乘或者除以一个极小的数时容易出现结果超出FP16范围问题(65504)。
5.7.2. 性能分析
5.7.2.1. 获取性能
将以deepfm网络为例,使用精度分析工具获取性能数据:
# 设置dump数据存放目录
$ export DUMP_MEMORY_PATH=/usr/share/stc_tb/hpaa_dump/test_1
# 设置只跑性能分析工具
$ export DUMP_OP_PERF=1
# 运行deepfm网络模型
$ python -m pytest -s test_deepfm.py::test_deepfm
# 运行精度分析工具中的NPU数据分析脚本
$ python3 stc-hpaa/run_npu_data_analysis.py
说明:若需同时获取精度与性能数据,
DUMP_OP_PERF需设置为2。
最终对比结果生成在您指定的dump数据存放目录下,即设置的DUMP_MEMORY_PATH下,其中包含:
dump_data文件夹:主要保存的是dump出来的16进制的数据。经过
run_npu_data_analysis.py脚本转成二进制形式并进行数据拼接,最终输出到npu文件夹。result文件夹:主要保存的是最终对比分析结果。
dump_memory_nodename.log:dump数据中节点名(节点名未去重)。
op_perf.csv:整网融合算子的perf信息。
perf文件夹:节点每次运行的详细性能数据。
说明:结果文件具体说明可查看附录中的结果文件说明章节。若同时获取精度与性能数据,生成的文件请同时参考获取精度章节和本章节列出的文件。
5.7.2.2. 分析结果
分析有BaseLine的网络时:
当对比发现某个融合算子perf信息中的pld bytes增加时,说明存在重复搬移情况,需调整schedule或tiling优化。
当对比发现某个融合算子perf信息中的l1_conflict_cycle/imb_conflict_cycle增加时,说明存在l1/imb上bank冲突恶化,可尝试将tiling的L1/IMB切分参数调小。
分析新网络时:针对op_perf.csv中mcu_cycle最大的几个融合算子,首先判断是数据瓶颈还是计算瓶颈。根据不同的场景进行不同优化改进。
5.8. 附录
5.8.1. CPU端数据dump接口使用说明
5.8.1.1. tf_dump_fmap
接口描述:TensorFlow模型dump网络中间节点参考数据接口。
接口定义:
def tf_dump_fmap(
model_path: str,
input_map: dict,
feed_dict: dict,
npu_nodename_filename: str,
consumer_map_filename: str,
dump_shape_flag=False,
graph_def=None)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 | 是否建议修改 |
|---|---|---|---|---|
| model_path | str | 是 | 模型完整路径。 | 是 |
| input_map | dict | 是 | 模型输入map。 | 是 |
| feed_dict | dict | 是 | 模型输入数据。 | 是 |
| npu_nodename_filename | str | 是 | NPU 端dump出的节点列表, 默认值为CUR_NPU_NODENAME_FILENAME。 |
否 |
| consumer_map_filename | str | 是 | pb模型dump出节点生产者与消费者关系dict(pickle格式文件),默认值为consumer_map_dict.file。 |
否 |
| dump_shape_flag | bool | 否 | dump出的节点文件名是否带shape信息,默认值为False。 | 否 |
| graph_def | GraphDef | 否 | 输入的模型graph,为空时,接口内部会读取加载模型。默认值为空。 | 否 |
返回值:
无
调用示例:
from common import tf_dump_fmap, CUR_NPU_NODENAME_FILENAME
...
input_maps = {"input_tensor": tf.placeholder(shape=(BATCH_SIZE, 224, 224, 3), dtype="float16", name="input_tensor")}
feed_dicts = {"input_tensor:0": input_tensor}
tf_dump_fmap(model_path, input_maps, feed_dicts, CUR_NPU_NODENAME_FILENAME, "consumer_map_dict.file")
5.8.1.2. onnx_dump_fmap
接口描述:onnx模型dump网络中间节点参考数据接口。
接口定义:
def onnx_dump_fmap(
model_path: str,
input_map: dict,
npu_nodename_filename: str,
consumer_map_filename: str,
dump_shape_flag=False)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 | 是否建议修改 |
|---|---|---|---|---|
| model_path | str | 是 | 模型完整路径。 | 是 |
| input_map | dict | 是 | 模型输入map。 | 是 |
| npu_nodename_filename | str | 是 | NPU 端dump出的节点列表, 默认值为CUR_NPU_NODENAME_FILENAME。 |
否 |
| consumer_map_filename | str | 是 | pb模型dump出节点生产者与消费者关系dict(pickle格式文件),默认值为consumer_map_dict.file。 |
否 |
| dump_shape_flag | bool | 否 | dump出的节点文件名是否带shape信息,默认值为False。 | 否 |
返回值:
无
调用示例:
from common import onnx_dump_fmap, CUR_NPU_NODENAME_FILENAME
...
input_ids, input_mask, segment_ids = prepare_input()
input_maps = {
"input.1": input_ids.astype("int64"),
"input.3": segment_ids.astype("int64"),
"attention_mask": input_mask.astype("int64"),
}
onnx_dump_fmap(model_path, input_maps, CUR_NPU_NODENAME_FILENAME, "consumer_map_dict.file")
5.8.2. 结果文件说明
5.8.2.1. cpu_vs_npu.csv
文件描述:最终的精度对比分析结果文件。

字段说明:
| 字段名 | 描述 |
|---|---|
| op_name | 网络中节点的名称(附带显示atol/rtol参数值)。 |
| nan/inf | NPU结果数据中是否出现过nan或inf数据(比较前nan会被转成0,inf会被转成最大值)。 |
| errors/total | 不满足用户设置的相对误差和绝对误差的个数/当前算子的总个数(单位:个)。 |
| 1st_diff_offset/offset_dim/data_shape | 第一个数据错误的位置,对应的维度信息,数据shape信息。 |
| ref_value | 标准模型(TensorFlow模型、ONNX模型)第一个发生错误时的数据(目前仅保留小数点后6位有效数字),若当前算子均未发生精度对比失败,此时的值为算子输出的第一个数据。 |
| npu_value | 基于九章NPU框架的推理模型,第一个发生错误时的数据(目前仅保留小数点后6位有效数字),若当前算子均未发生精度对比失败,此时的值为算子输出的第一个数据。 |
| max_abs_err | 节点错误数据的最大绝对误差。 |
| mean_abs_err | 节点错误数据的平均绝对误差。 |
| max_abs_total | 节点数据的最大相对误差。 |
| mean_abs_total | 节点数据的平均相对误差。 |
| mean | 参考数据(TensorFlow模型、ONNX模型的数据)的均值。 |
| std | 参考数据(TensorFlow模型、ONNX模型的数据)的方差。 |
| rms | 参考数据(TensorFlow模型、ONNX模型的数据)的均方根值(root mean square)。 |
5.8.2.2. {op_name}.csv
文件描述:精度对比失败算子详细信息。
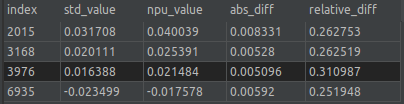
字段说明:
| 字段名 | 说明 |
|---|---|
| index | 精度对比失败发生的索引号。 |
| std_value | 标准模型相应索引位置的值。 |
| npu_value | 九章NPU模型相应索引位置的值。 |
| abs_diff | 绝对误差。 |
| relative_diff | 相对误差。 |
5.8.2.3. op_perf.csv
文件描述:最终的精度对比分析结果文件。
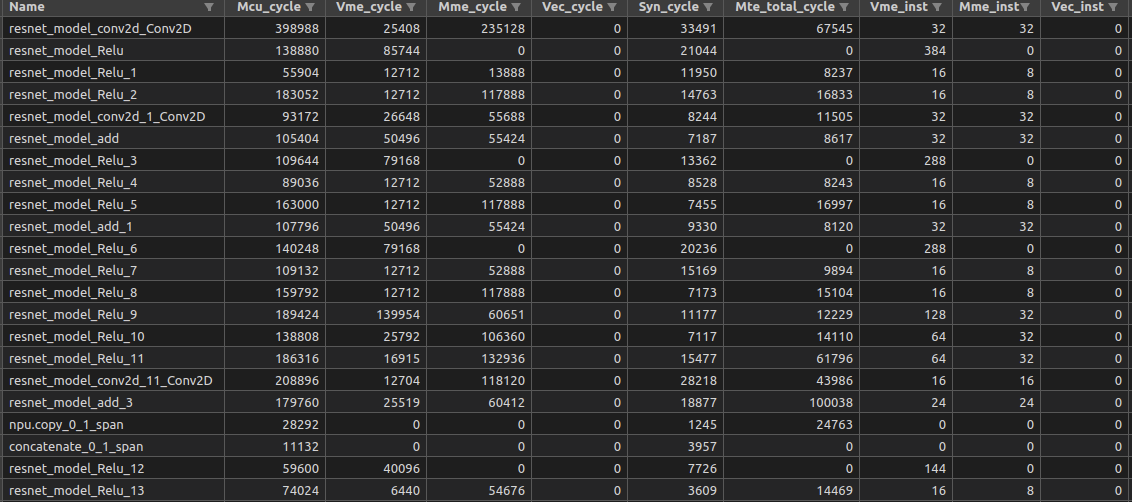
字段说明:
| 字段名 | 描述 |
|---|---|
| name | 节点名称 |
| mcu_cycle | 总的执行周期数。 |
| vme_cycle | vme执行单元的周期数。 |
| mme_cycle | mme执行单元的周期数。 |
| vec_cycle | rvv执行单元的周期数。 |
| syn_cycle | sync执行单元的周期数。 |
| mte_total_cycle | mte总周期数。 |
| vme_inst | vme指令条数。 |
| mme_inst | mme指令条数。 |
| vec_inst | rvv指令条数。 |
| syn_inst | sync指令条数。 |
| mte_pld_inst | pld指令条数。 |
| mte_icmov_inst | icmov指令条数。 |
| mte_mov_inst | mov指令条数。 |
| pal_vme_mme_cycle | vme和mme指令并行运行周期数。 |
| pal_mte_mme_cycle | vme和mme指令并行运行周期数。 |
| pal_vme_mte_cycle | vme和mte指令并行运行周期数。 |
| pal_total_cycle | vme、mme、mte总并行运行周期数。 |
| mte_icmov_cycle | icmov指令周期数。 |
| mte_l12llb_cycle | mov_l12llb指令周期数。 |
| mte_llb2l1_cycle | mov_llb2l1指令周期数。 |
| mte_pld_cycle | pld指令周期数。 |
| mte_pld_byte | pld搬移的数据总量,字节为单位。 |
| mte_l12llb_byte | mov_l12llb搬移的数据总量,字节为单位。 |
| mte_llb2l1_byte | mov_llb2l1搬移的数据总量,字节为单位。 |
| mte_icmov_byte | icmov搬移的数据总量,字节为单位。 |
| syn_wait_cycle | syn等待的周期数。 |
| vec_slot_wait_cycle | rvv指令等待执行的周期数。 |
| mme_slot_wait_cycle | mme指令等待执行的周期数。 |
| mte_slot_wait_cycle | mte指令等待执行的周期数。 |
| l1_conflict_cycle | l1冲突周期数。 |
| im_conflict_cycle | imb冲突周期数。 |
| dcache_miss_cnt | dcache 没命中次数。 |
| icache_miss_cnt | icache 没命中次数。 |
| instruction_cnt | 总指令条数。 |
| dma0_llb_conflict_cycle | dma0的LLB冲突周期数。 |
| dma0_c0_cycle0 | dma0通道0的最近一次传输的周期数。 |
| dma0_c0_cycle1 | dma0通道0的总传输的周期数。 |
| dma0_c0_byte | dma0通道0的传输的字节数。 |
| dma0_c1_cycle0 | dma0通道1的最近一次传输的周期数。 |
| dma0_c1_cycle1 | dma0通道1的总传输的周期数。 |
| dma0_c1_byte | dma0通道1的传输的字节数。 |
| dma1_llb_conflict_cycle | dma1的LLB冲突周期数。 |
| dma1_c0_cycle0 | dma1通道0的最近一次传输的周期数。 |
| dma1_c0_cycle1 | dma1通道0的总传输的周期数。 |
| dma1_c0_byte | dma1通道0的传输的字节数。 |
| dma1_c1_cycle0 | dma1通道1的最近一次传输的周期数。 |
| dma1_c1_cycle1 | dma1通道1的总传输的周期数。 |
| dma1_c1_byte | dma1通道1的传输的字节数。 |
5.8.2.4. perf/{op_name}.csv
文件描述:图调度后融合算子每次运行的perf信息。

字段说明:表格字段含义和op_perf.csv文件一致,可参考op_perf.csv的字段说明。
5.8.3. 常见问题
在容器内使用工具时,容器内挂载路径与host路径不一致。
由于dump数据功能由驱动实现,只能使用host路径,而精度分析工具使用的是容器内路径,所以需要进行两次dump数据,分别生成dump_data文件夹中的dump出的数据和result文件夹中的dump_memory_nodename.log文件,将两个文件夹放在一起后,可正常进行精度分析工具后续步骤。
以deepfm模型为例,完整演示整个步骤:
# 创建容器 $ docker run -it --privileged=true -v /usr/share/stc_tb/hpaa_dump_1008:/home/hpaa_dump ${image} /bin/bash # 进入容器 # 先设置host路径下的子目录为DUMP_MEMORY_PATH $ export DUMP_MEMORY_PATH=/usr/share/stc_tb/hpaa_dump_1008/test $ export DUMP_OP_PERF=2 # 如果之前已存在DUMP_MEMORY_PATH设置的目录,需在先删除该目录 $ rm -rf /usr/share/stc_tb/hpaa_dump_1008/test # 运行网络模型 $ python -m pytest -s test_deepfm.py::test_deepfm # 在设置的DUMP_MEMORY_PATH中会生成dump_data文件夹,可在对应挂载目录下查看 $ ls /home/hpaa_dump/test dump_data # 设置容器挂载目录下的子目录为DUMP_MEMORY_PATH $ export DUMP_MEMORY_PATH=/home/hpaa_dump/test_1 # 运行网络模型 $ python -m pytest -s test_deepfm.py::test_deepfm # 在新设置的DUMP_MEMORY_PATH中会生成dump_data和result文件夹,其中dump_data为空 $ ls /home/hpaa_dump/test_1 dump_data result # 将之前DUMP_MEMORY_PATH中会生成的dump_data拷贝到新的DUMP_MEMORY_PATH下 $ cp -r /home/hpaa_dump/test/dump_data /home/hpaa_dump/test_1 # 后续可正常使用精度分析工具,详细步骤可参考使用流程 $ python3 stc-hpaa/run_npu_data_analysis.py $ python3 get_deepfm_output.py $ python3 stc-hpaa/run_precision_analysis.py