4. 希姆计算stc-prof使用说明
4.1. 版本历史
| 文档版本 | 对应产品版本 | 作者 | 日期 | 描述 |
|---|---|---|---|---|
| V1.6.0 | STCRP v1.5.0 | 希姆计算 | 2023-08-01 | 增加支持用户指定存储文件目录功能 。 |
| V1.5.0 | STCRP v1.4.0 | 希姆计算 | 2023-04-07 | 验证文档内容。 |
| V1.4.0 | STCRP v1.3.1 | 希姆计算 | 2023-03-29 | 增加基于TensorTurbo执行模型时的性能数据采集示例。 |
| V1.3.1 | HPE V1.5.0 | 希姆计算 | 2022-11-30 | 验证文档内容。 |
| V1.3.0 | HPE V1.4.0 | 希姆计算 | 2022-08-29 | 更新help信息,增加multi-thread说明。 |
| V1.2.1 | HPE V1.3.0 | 希姆计算 | 2022-07-07 | 验证文档内容。 |
| V1.2.0 | HPE V1.2.1 | 希姆计算 | 2022-06-02 | 整篇编辑优化。 使用简单易懂的示例目标程序。 补充VME、MME、MTE等指令的简介。 |
| V1.1.0 | HPE V1.2.0 | 希姆计算 | 2022-04-11 | 增加record命令--multi-thread选项的描述。文档版本号对齐HPE发版,章节目录优化。 |
| V1.0.0 | Unknown | 希姆计算 | 2021-09-01 | 初始版本。 |
4.2. 概述
希姆计算的异构编程环境为开发、编译、运行主机端程序和设备端程序提供了完整的工具链。命令行工具stc-prof(Stream Computing Profiler)和性能数据采集接口STCPTI(Stream Computing Profiling Tool Interface)均可用于异构程序的性能分析和调优,它们采集与呈现的性能数据内容相同,只是使用方法不同。本文将介绍stc-prof和STCPTI的使用方法以及各项相关性能指标。
说明:希姆计算软硬件产品相关的基本概念,请参见希姆计算基本概念。
4.3. 前提条件
在主机上部署希姆计算异构环境。具体的步骤,请参见希姆计算异构环境安装指南。安装HPE后,stc-prof的二进制文件位于/usr/local/hpe/bin目录中。
STCPTI的接口功能主要由以下文件提供:
位于/usr/local/hpe/include中的头文件stcpti.h。
位于/usr/local/hpe/lib中的共享链接库文件libprofiler_stc.so、libtracer_stc.so。
4.4. stc-prof
4.4.1. 命令说明
执行stc-prof --help获取stc-prof命令的使用方法:
$ stc-prof --help
OVERVIEW: function tracer for stream computing heterogeneous program
Usage: stc-prof [--version] [--help] [COMMAND [OPTION...] [program]]
COMMAND:
record Record target program performance data
OPTION:
--output-dir="dir" Specify output data dir, default is stc-prof.data
--multi-thread profiling multi-thread by thread group id
dump Output Chrome tracer file
OPTION:
--input-dir="dir" Specify input data dir, default is stc-prof.data
summary Output summary of target program performance data
OPTION:
--input-dir="dir" Specify input data dir, default is stc-prof.data
--target-pid="pid" Specify output process id
--target-tid="tid" Specify output thread id
detail Output detail of target program performance data. Multiple sub-module names separated by comma can be supported
OPTION:
--input-dir="dir" Specify input data dir, default is stc-prof.data
--sub-module="DEFAULT" Output detail of target program cycle and cache performance data
--sub-module="VME" Output detail of target program VME performance data
--sub-module="MTE" Output detail of target program MTE performance data
--sub-module="MME" Output detail of target program MME performance data
--sub-module="PAL" Output detail of target program parallel data
--sub-module="MCU" Output detail of target program MCU performance data
--sub-module="MEMORY" Output detail of target program Memory data
--sub-module="MEMORY-COL" Output detail of target program Memory collision data
SUB-OPTION:
--target-pid="pid" Specify output process id when --sub-module assigned
--target-tid="tid" Specify output thread id when --sub-module assigned
stc-prof支持以下命令:
| 命令 | 描述 |
|---|---|
record |
执行目标程序并采集性能数据,采集过程中不会额外打印信息,默认按tid进行采集。采集结果默认保存在stc-prof.data目录中,并最多保存两次执行的采集结果,最近一次的结果存放stc-prof.data目录中,上一次的存放在在stc-prof.data.old目录中。此外,也可用户自行使用参数指定结果保存路径。--output-dir:指定结果保存路径。--multi-thread:指定按pid进行采集。 |
dump |
基于stc-prof.data目录中的性能数据输出CTF文件,其中包括了HPE Runtime API、stream的信息。CTF(Chrome Tracer File)文件是一类文本文件,使用JSON格式保存,用于描述各类事件发生与结束的时间。您可以使用Chrome Tracer Viewer(chrome://tracing/)打开CTF文件,可视化查看程序执行时间轴。 默认读取stc-prof.data目录中的采集结果,若在采集数据时,自行指定了保存路径,需使用参数指定结果保存的路径。 --input-dir:指定结果保存路径。 |
summary |
基于stc-prof.data目录中的性能数据展示概要信息,包括HPE Runtime API调用耗时、核函数执行耗时、sysDMA使用情况、主机端设备端数据搬移情况。支持指定以下选项进行筛选:--target-pid:筛选指定pid的性能数据。--target-tid:筛选指定tid的性能数据。默认读取stc-prof.data目录中的采集结果,若在采集数据时,自行指定了保存路径,需使用参数指定结果保存的路径。 --input-dir:指定结果保存路径。 |
detail |
基于stc-prof.data目录中的性能数据展示核函数执行过程中指定类型的详细执行信息,支持指定以下选项进行筛选:--sub-module:筛选指定类型的性能数据。支持通过逗号分隔指定多个类型,但输出信息的顺序与参数顺序无关,例如stc-prof detail --sub-module="VME,MME"筛选VME、MME指令的性能信息。--target-pid:在指定--sub-module的基础上,筛选指定pid的性能数据。--target-tid:在指定--sub-module的基础上,筛选指定tid的性能数据。支持筛选的类型如下: DEFAULT:输出多个模块汇总的性能信息,包括cycle数和cache miss计数。VME:输出VME指令相关的性能信息。VME(Vector MAC Engine)用于执行向量运算,支持两类向量运算指令,VME-CU由希姆计算自定义的向量运算指令,VME-VEC为RISC-V原生的向量运算指令。MTE:输出MTE指令相关的性能信息。MTE(Memory Transfer Engine)用于搬运数据。MME:输出MME指令相关的性能信息。MME(Matrix MAC Engine)用于执行矩阵运算。PAL:输出并行度相关的性能信息。PAL(Parallelism)用于评估运算时并行执行多种指令的占比,并行度高代表充分利用了硬件。MCU:输出MCU指令相关的性能信息。MCU(Micro Controller Unit)用于管理在NPU上执行的任务,负责包括但不限于解释指令、发射指令等。MEMORY:输出全局内存(DDR)/共享内存(LLB)/本地内存(L1)相关性能信息。MEMORY-COL:输出全局内存(DDR)/共享内存(LLB)/本地内存(L1)冲突相关信息。一般内存会划分为不同的块,如果在同一时刻访问同一块内存时会产生冲突,需要排队使用,从而导致性能下降。默认读取stc-prof.data目录中的采集结果,若在采集数据时,自行指定了保存路径,需使用参数指定结果保存的路径。--input-dir:指定输入路径。 |
4.4.2. 使用流程
使用stc-prof的分析程序性能的流程如下:
通过
record命令采集执行的目标程序的性能数据。目前工具支持HC编译后的二进制文件和基于TensorTurbo执行的模型用例。性能数据默认保存在stc-prof.data文件目录中,也可使用--output-dir参数选项指定性能数据输出目录。以matrix-multiply的代码HC文件为例,先编译源文件,再通过
record命令采集执行程序的性能数据:$ stcc --rtlib=compiler-rt matrix-multiply.hc -o matrix-multiply $ stc-prof record --output-dir=data-stc-prof ./matrix-multiply
说明:性能数据输出目录路径长度不能大于225个字节,相对路径将展开成绝对路径计算长度。
其中示例异构程序源文件matrix-multiply.hc,代码如下:
/* * Copyright (c) 2019-2021 北京希姆计算科技有限公司 (Stream Computing Inc.) * All Rights Reserved. * * NOTICE: All intellectual and technical information contained herein * are proprietary to Stream Computing Inc. Any unauthorized disemination, * copying or redistribution of this file via any medium is strictly prohibited, * unless you get a prior written permission or an applicable license agreement * from Stream Computing Inc. */ /* * This example uses internal instructions to do matrix multiply. */ #include <asm_macro.h> #include <hpe.h> #include <npurt.h> #include <stdio.h> // number of left matrix's col and right matrix's row #define LCOL_RROW 8 // local_left * local_right = local_out __device__ void matmul(__fp16 *local_out, __fp16 *local_left, __fp16 *local_right) { int shape1, shape2; // do matrix multiply and result must be stored in IM buffer shape1 = DEFINE_SHAPE(LCOL_RROW, 1); shape2 = DEFINE_SHAPE(1, LCOL_RROW); CONFIG_VE_BC_CSR(shape1, shape2, 0, 0); memul_mm((__fp16 *)IM_BUFFER_START, local_left, local_right); // move result from IM buffer to local memory shape1 = DEFINE_SHAPE(1, 1); shape2 = 0; CONFIG_VE_CSR(shape1, shape2, 0, 0); mov_m(local_out, (__fp16 *)IM_BUFFER_START); } __global__ void matmul_kernel(__fp16 *global_out, __fp16 *global_left, __fp16 *global_right) { __local__ __fp16 local_left[LCOL_RROW]; __local__ __fp16 local_right[LCOL_RROW]; __local__ __fp16 local_out; __shared__ __fp16 share_out[CoreNum]; printf("CoreNum is %d\n", CoreNum); // copy right matrix to each core memcpy(local_right, global_right, LCOL_RROW * sizeof(__fp16)); // copy a row of left matrix for each core memcpy(local_left, global_left + CoreID * LCOL_RROW, LCOL_RROW * sizeof(__fp16)); // matrix multiply matmul(&local_out, local_left, local_right); // copy result in local memory of each core to shared memory memcpy(share_out + CoreID, &local_out, sizeof(__fp16)); // sync to wait each of the core compute share_out data filled sync(); if (CoreID == 0) { // copy result in share memory of each core to global memory memcpy(global_out, share_out, CoreNum * sizeof(__fp16)); } } #define NCORE 8 int main(void) { __fp16 *dev_left, *dev_right, *dev_out; // left matrix data for 8 cores __fp16 host_left[8 * LCOL_RROW] = { 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, // row1 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, // row2 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, // row3 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, // row4 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, // row5 5.0, 5.0, 5.0, 5.0, 5.0, 5.0, 5.0, 5.0, // row6 6.0, 6.0, 6.0, 6.0, 6.0, 6.0, 6.0, 6.0, // row7 7.0, 7.0, 7.0, 7.0, 7.0, 7.0, 7.0, 7.0, // row8 }; // right matrix data __fp16 host_right[LCOL_RROW] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0}; // copy left matrix to device int mat_size_left = NCORE * LCOL_RROW * sizeof(__fp16); stcMalloc((void **)&dev_left, mat_size_left); stcMemcpy(dev_left, host_left, mat_size_left, stcMemcpyHostToDevice); // copy right matrix to device int mat_size_right = LCOL_RROW * sizeof(__fp16); stcMalloc((void **)&dev_right, mat_size_right); stcMemcpy(dev_right, host_right, mat_size_right, stcMemcpyHostToDevice); // allocate result buffer in device int mat_size_out = NCORE * sizeof(__fp16); __fp16 host_out[NCORE]; stcMalloc((void **)&dev_out, mat_size_out); matmul_kernel<<<NCORE>>>(dev_out, dev_left, dev_right); stcDeviceSynchronize(); // copy result from device to host stcMemcpy(host_out, dev_out, mat_size_out, stcMemcpyDeviceToHost); printf("matrix multiply result:"); for (int i = 0; i < NCORE; i++) printf("%.1f, ", (float)(host_out[i])); printf("\n"); stcFree(dev_left); stcFree(dev_right); stcFree(dev_out); return 0; }
采集模型性能数据,以用例入口为
test_deepfm.py中的test_deepfm接口为例:$ stc-prof record --output-dir=data-stc-prof python3 -m pytest -s test_deepfm.py
说明:您可以请自行实现模型用例,或者联系希姆计算技术支持提供协助。
通过相关命令展示性能数据。展示性能数据时,默认读取stc-prof.data目录下的性能数据,若在采集性能数据时,指定了存储目录,则需要使用
--input-dir参数选项指定输入目录。导出性能数据并转存成CTF文件。生成文件的名字可自定义,这里以perf_events.json为例:
$ stc-prof dump --input-dir=data-stc-prof > perf_events.json
展示概要信息:
$ stc-prof summary --input-dir=data-stc-prof
以展示VME指令的详细性能信息为例:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="VME"
4.4.3. 命令示例
4.4.3.1. record
采集执行的目标程序的性能数据。以执行matrix-multiply采集性能数据为例:
$ stc-prof record ./matrix-multiply
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
matrix multiply result:0.0, 36.0, 72.0, 108.0, 144.0, 180.0, 216.0, 252.0,
$ cd stc-prof.data
$ ls
default.opts stc-addition-226044.db stc-addition-pid.db
也可使用--output-dir参数选项指定性能数据输出目录。
$ stc-prof record --output-dir=data-stc-prof ./matrix-multiply
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
CoreNum is 8
matrix multiply result:0.0, 36.0, 72.0, 108.0, 144.0, 180.0, 216.0, 252.0,
$ cd data-stc-prof
$ ls
default.opts stc-addition-29234.db stc-addition-pid.db
4.4.3.2. dump
导出性能数据并转存成CTF文件,文件可使用Chrome Tracer Viewer查看程序执行时间轴,示例如下:
导出性能数据并转存成CTF文件。
$ stc-prof dump > perf_events.json
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需在导出性能数据时设置性能数据输入目录。示例如下:
$ stc-prof dump --input-dir=data-stc-prof > perf_events.json
打开Chrome Tracer Viewer(chrome://tracing/),单击Load然后选择perf_events.json即可。
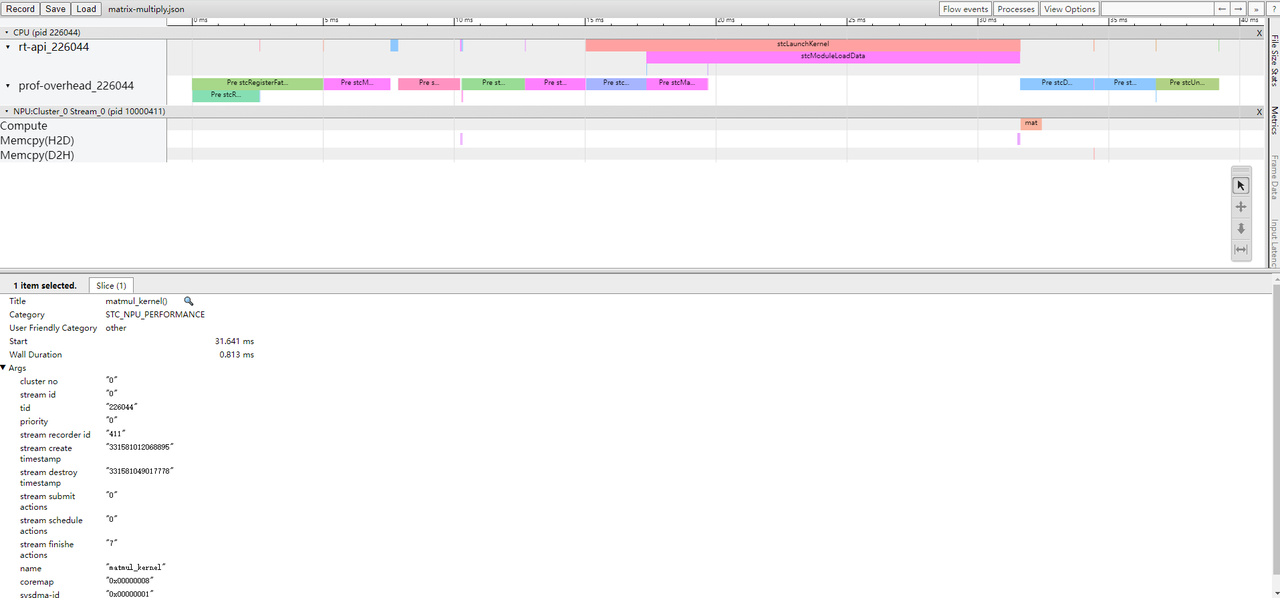
4.4.3.3. summary
展示摘要信息的示例如下:
说明:当内容大于屏幕的高度或者宽度时,可以通过方向键显示被折叠的内容。
$ stc-prof summary
pid:226044
|
--tid:226044
HPE Runtime API Info:
Pid Total Time Avg Time Total CPU Time Avg CPU Time Calls Function
====== ==================== ==================== ==================== ==================== ====== ================================
226044 2.695 us 2.695 us 2.583 us 2.583 us 1 stcDeviceSynchronize
226044 300.060 us 75.015 us 300.038 us 75.010 us 4 stcMalloc
226044 2.657 us 2.657 us 2.571 us 2.571 us 1 stcMallocHigh
226044 4.284 us 1.428 us 4.208 us 1.403 us 3 stcFree
226044 107.231 us 35.744 us 42.850 us 14.283 us 3 stcMemcpy
226044 2.754 us 2.754 us 2.675 us 2.675 us 1 stcConfigureCall
226044 16601.934 us 16601.934 us 723.381 us 723.381 us 1 stcLaunchKernel
226044 14274.015 us 14274.015 us 653.996 us 653.996 us 1 stcModuleLoadData
226044 25.512 us 25.512 us 25.431 us 25.431 us 1 stcRegisterFatBinary
226044 0.808 us 0.808 us 0.696 us 0.696 us 1 stcUnregisterFatBinary
226044 4.114 us 4.114 us 3.585 us 3.585 us 1 stcRuntimeGetVersion
------ -------------------- -------------------- -------------------- -------------------- ------ --------------------------------
Kernel Functions:
Kernel-Function Duration MCU MTE MME VME-CU VME-VEC TID
======================================== ================ ======== ======== ======== ======== ======== ========
matmul_kernel (8) 294.456 us 90582 65 28 11 0 226044
---------------------------------------- ---------------- -------- -------- -------- -------- -------- --------
Kernel Functions Memory(SysDMA):
Kernel-Function DMA-ID C0 (DDR -> LLB) C1 (LLB -> DDR) TID
======================================== ======== ========================= ========================= ========
matmul_kernel sysdma_0 0 B ( 0.0000 GB/s) 0 B ( 0.0000 GB/s) 226044
matmul_kernel sysdma_1 0 B ( 0.0000 GB/s) 16 B ( 0.2388 GB/s) 226044
---------------------------------------- -------- ------------------------- ------------------------- --------
DEVICE_TO_HOST size: 16 B speed: 0.0011 GB/s
HOST_TO_DEVICE size: 29.14 KB speed: 0.2947 GB/s
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需在展示摘要信息时设置性能数据输入目录。示例如下:
$ stc-prof summary --input-dir=data-stc-prof
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| pid | 226044 | 执行程序所在的进程ID。 |
| tid | 226044 | 执行程序所在的线程ID。 |
| HPE Runtime API Info | - Total Time:300.060 us - Avg Time:75.015 us - Total CPU Time:300.038 us - Avg CPU Time:75.010 us - Calls:4 - Function:stcMalloc |
HPE Runtime API调用耗时,包括以下项目: - Total Time:调用某个API消耗的总执行时间。 - Avg Time:单次调用某个API消耗的平均执行时间。 - Total CPU Time:调用某个API消耗的总CPU时间。 - Avg CPU Time:单次调用某个API消耗的平均CPU时间。 - Calls:调用API的次数。 - Function:调用的API。 |
| Kernel Functions | - Kernel-Function:matmul_kernel (8) - Duration:294.456 us - MCU:90582 MTE:65 - MME:28 - VME-CU:11 - VME-VEC:0 - TID:226044 |
在NPC执行核函数的性能数据信息: - Kernel-Function:核函数名称。 - Duration:核函数执行耗时。 MCU:MCU指令耗费的cycle数。 - MTE:MTE指令耗费的cycle数。 - MME:MME指令耗费的cycle数。 - VME-CU:希姆计算自定义向量运算指令耗费的cycle数。 - VME-VEC:RISC-V原生向量运算指令耗费的cycle数。 - TID:执行程序所在的线程ID。 |
| Kernel Functions Memory | - Kernel-Function:matmul_kernel - DMA-ID:sysdma_1 - C0 (DDR -> LLB):0 B ( 0.0000 GB/s) - C1 (LLB -> DDR):16 B ( 0.2388 GB/s) - TID:226044 |
sysDMA使用情况,包括以下项目: - Kernel-Function:核函数名称。 - DMA-ID:DMA控制器的ID。 - C0 (DDR -> LLB):DMA控制器Channel 0,执行程序时从DDR向LLB搬运的数据量和带宽。 - C1 (LLB -> DDR):DMA控制器Channel 1,执行程序时从LLB向DDR搬运的数据量和带宽。 - TID:执行程序所在的线程ID。 |
| DEVICE_TO_HOST | size: 16 B speed: 0.0011 GB/s | 设备端向主机端搬运的数据量和带宽。 |
| HOST_TO_DEVICE | size: 29.14 KB speed: 0.2947 GB/s | 主机端向设备端搬运的数据量和带宽。 |
4.4.3.4. detail
4.4.3.4.1. DEFAULT
输出多个模块汇总性能信息的示例如下:
$ stc-prof detail --sub-module="DEFAULT"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
NPC-CORE MCU-CYCLE MTE MME VME-CU VME-VEC DCACHE MISS ICACHE MISS
========== ============ ======== ======== ======== ======== ============ ============
NPC_00 137404 84 28 11 0 37 215
NPC_01 80360 84 28 11 0 15 137
NPC_02 80652 68 28 11 0 15 136
NPC_03 80272 68 28 11 0 15 136
NPC_04 80032 68 28 11 0 15 139
NPC_05 79200 51 28 11 0 15 137
NPC_06 79548 52 28 11 0 15 140
NPC_07 79604 52 28 11 0 15 137
---------- ------------ -------- -------- -------- -------- ------------ ------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="DEFAULT"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| MCU-CYCLE | 137404 | MCU指令耗费的cycle数。 |
| MTE | 84 | MTE指令耗费的cycle数。 |
| MME | 28 | MME指令耗费的cycle数。 |
| VME-CU | 11 | 希姆计算自定义向量运算指令耗费的cycle数。 |
| VME-VEC | 0 | RISC-V原生向量运算指令耗费的cycle数。 |
| DCACHE-MISS | 37 | DCACHE MISS计数。 |
| ICACHE-MISS | 215 | ICACHE MISS计数。 |
4.4.3.4.2. VME
输出VME指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="VME"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
NPC-CORE VME-CU VME-CU INST VME-VEC VME-VEC INST VME VME-MME VME-MTE VME-MME-MTE
========== ======== ============= ======== ============= ======================================
NPC_00 11 1 0 0 8.9% 0.0% 0.0% 0.0%
NPC_01 11 1 0 0 8.9% 0.0% 0.0% 0.0%
NPC_02 11 1 0 0 10.3% 0.0% 0.0% 0.0%
NPC_03 11 1 0 0 10.3% 0.0% 0.0% 0.0%
NPC_04 11 1 0 0 10.3% 0.0% 0.0% 0.0%
NPC_05 11 1 0 0 12.2% 0.0% 0.0% 0.0%
NPC_06 11 1 0 0 12.1% 0.0% 0.0% 0.0%
NPC_07 11 1 0 0 12.1% 0.0% 0.0% 0.0%
---------- -------- ------------- -------- ------------- --------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="VME"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| VME-CU | 11 | 希姆计算自定义向量运算指令耗费的cycle数。 |
| VME-CU INST | 1 | 希姆计算自定义向量运算指令的数量。 |
| VME-VEC | 0 | RISC-V原生向量运算指令耗费的cycle数。 |
| VME-VEC INST | 0 | RISC-V原生向量运算指令的数量。 |
| VME | 8.9% | 执行VME指令占wall-clock time的百分比。 |
| VME-MME | 0.0% | 并行执行VME、MME指令的并行度,即占wall-clock time的百分比。 |
| VME-MTE | 0.0% | 并行执行VME、MTE指令的并行度,即占wall-clock time的百分比。 |
| VME-MME-MTE | 0.0% | 并行执行VME、MME、MTE指令的并行度,即占wall-clock time的百分比。 |
4.4.3.4.3. MTE
输出MTE指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="MTE"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
NPC-CORE MTE MTE INST MTE MTE-MME MTE-VME MTE-MME-VME
========== ======== ========== ======================================
NPC_00 84 1 68.3% 0.0% 0.0% 0.0%
NPC_01 84 1 68.3% 0.0% 0.0% 0.0%
NPC_02 68 1 63.6% 0.0% 0.0% 0.0%
NPC_03 68 1 63.6% 0.0% 0.0% 0.0%
NPC_04 68 1 63.6% 0.0% 0.0% 0.0%
NPC_05 51 1 56.7% 0.0% 0.0% 0.0%
NPC_06 52 1 57.1% 0.0% 0.0% 0.0%
NPC_07 52 1 57.1% 0.0% 0.0% 0.0%
---------- -------- ---------- --------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MTE"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| MTE | 84 | MTE指令耗费的cycle数。 |
| MTE INST | 1 | MTE指令的数量。 |
| MTE | 68.3% | 执行MTE指令占wall-clock time的百分比。 |
| MTE-MME | 0.0% | 并行执行MTE、MME指令的并行度,即占wall-clock time的百分比。 |
| MTE-VME | 0.0% | 并行执行MTE、VME指令的并行度,即占wall-clock time的百分比。 |
| MTE-MME-VME | 0.0% | 并行执行MTE、MME、VME指令的并行度,即占wall-clock time的百分比。 |
4.4.3.4.4. MME
输出MME指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="MME"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
NPC-CORE MME MME INST MME MME-VME MME-MTE MME-VME-MTE
========== ======== ========== ======================================
NPC_00 28 1 22.8% 0.0% 0.0% 0.0%
NPC_01 28 1 22.8% 0.0% 0.0% 0.0%
NPC_02 28 1 26.2% 0.0% 0.0% 0.0%
NPC_03 28 1 26.2% 0.0% 0.0% 0.0%
NPC_04 28 1 26.2% 0.0% 0.0% 0.0%
NPC_05 28 1 31.1% 0.0% 0.0% 0.0%
NPC_06 28 1 30.8% 0.0% 0.0% 0.0%
NPC_07 28 1 30.8% 0.0% 0.0% 0.0%
---------- -------- ---------- --------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MME"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| MME | 28 | 自定义MME指令的cycle数。 |
| MME INST | 1 | 自定义MME指令的数量。 |
| MME | 22.8% | 执行MME指令占wall-clock time的百分比。 |
| MME-VME | 0.0% | 并行执行MME、VME指令的并行度,即占wall-clock time的百分比。 |
| MME-MTE | 0.0% | 并行执行MME、MTE指令的并行度,即占wall-clock time的百分比。 |
| MME-VME-MTE | 0.0% | 并行执行MME、VME、MTE指令的并行度,即占wall-clock time的百分比。 |
4.4.3.4.5. PAL
输出并行度相关性能信息的示例如下:
$ stc-prof detail --sub-module="PAL"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
NPC-CORE PAL(ALL) PAL(MTE/MME) PAL(MTE/VME) PAL(VME/MME)
========== ================ ================ ================ ================
NPC_00 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_01 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_02 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_03 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_04 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_05 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_06 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_07 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
---------- ---------------- ---------------- ---------------- ----------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="PAL"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| PAL(ALL) | 0(0.000%) | 并行执行MTE、MME、VME指令的并行度,即占wall-clock time的百分比。 |
| PAL(MTE/MME) | 0(0.000%) | 并行执行MTE、MME指令的并行度,即占wall-clock time的百分比。 |
| PAL(MTE/VME) | 0(0.000%) | 并行执行MTE、VME指令的并行度,即占wall-clock time的百分比。 |
| PAL(VME/MME) | 0(0.000%) | 并行执行VME、MME指令的并行度,即占wall-clock time的百分比。 |
4.4.3.4.6. MCU
输出MCU指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="MCU"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
NPC-CORE MCU INST MCU CYCLE DCACHE MISS ICACHE MISS
========== ============ ============ ============ ============
NPC_00 7487 137404 37 215
NPC_01 4186 80360 15 137
NPC_02 4186 80652 15 136
NPC_03 4186 80272 15 136
NPC_04 4186 80032 15 139
NPC_05 4186 79200 15 137
NPC_06 4186 79548 15 140
NPC_07 4186 79604 15 137
---------- ------------ ------------ ------------ ------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MCU"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| MCU INST | 7487 | MCU指令的数量。 |
| MCU CYCLE | 137404 | MCU指令耗费的cycle数。 |
| DCACHE MISS | 37 | DCACHE MISS计数。 |
| ICACHE MISS | 215 | ICACHE MISS计数。 |
说明:指定MCU可能比指定DEFAULT统计出的MCU CYCLE数量偏大。由于指定MCU时统计对象为non-stopable的第三方寄存器,而指定DEFAULT时会在核函数执行结束后立即停止计数。
4.4.3.4.7. MEMORY
输出DDR/LLB/L1相关性能信息的示例如下:
$ stc-prof detail --sub-module="MEMORY"
matmul_kernel: (cluster_0 tid:226044) duration: 294.456 us
SYSDMA-ID C0 (DDR -> LLB) C1 (LLB -> DDR)
======================================================================================================
sysdma_0 0 B (0.000 GB/s) 0 B (0.000 GB/s)
sysdma_1 0 B (0.000 GB/s) 16 B (0.239 GB/s)
******************************************************************************************************
NPC-CORE ICMOV PLD L1 -> LLB LLB -> L1
======================================================================================================
NPC_00 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.025 GB/s) 0 B (0 GB/s)
NPC_01 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.025 GB/s) 0 B (0 GB/s)
NPC_02 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.031 GB/s) 0 B (0 GB/s)
NPC_03 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.031 GB/s) 0 B (0 GB/s)
NPC_04 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.031 GB/s) 0 B (0 GB/s)
NPC_05 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.042 GB/s) 0 B (0 GB/s)
NPC_06 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.041 GB/s) 0 B (0 GB/s)
NPC_07 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.041 GB/s) 0 B (0 GB/s)
------------------------------------------------------------------------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MEMORY"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| SYSDMA-ID | sysdma_1 | 核函数使用的DMA控制器的ID。 |
| C0 (DDR -> LLB) | 0 B (0.000 GB/s) | DMA控制器Channel 0,执行程序时从DDR向LLB搬运的数据量和带宽。 |
| C1 (LLB -> DDR) | 16 B (0.239 GB/s) | DMA控制器Channel 1,执行程序时从LLB向DDR搬运的数据量和带宽。 |
| NPC-CORE | NPC_00 | 核函数使用的NPC Core的ID。 |
| ICMOV | 0 B (0 GB/s) | MTE icmov指令相关的数据量与带宽。 |
| PLD | 0 B (0 GB/s) | MTE pld指令相关的数据量与带宽。 |
| L1 -> LLB | 2 B (0.025 GB/s) | MTE mov.llb.l1指令相关的数据量与带宽。 |
| LLB -> L1 | 0 B (0 GB/s) | MTE mov.l1.llb指令相关的数据量与带宽。 |
4.4.3.4.8. MEMORY-COL
输出DDR/LLB/L1冲突相关信息的示例如下:
$ stc-prof detail --sub-module="MEMORY-COL"
matmul_kernel: (cluster_0,tid:226044) duration: 294.456 us
SYSDMA-ID LLB COLLISION
======================================================================================================
sysdma_0 0
sysdma_1 0
******************************************************************************************************
NPC-CORE L1 COLLISION TYPE L1 COLLISION VAL IM COLLISION TYPE IM COLLISION VAL
======================================================================================================
NPC_00 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_01 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_02 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_03 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_04 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_05 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_06 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_07 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
------------------------------------------------------------------------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MEMORY-COL"
各列输出信息描述如下:
| 项目 | 示例值 | 描述 |
|---|---|---|
| SYSDMA-ID | sysdma_1 | 核函数使用的DMA控制器的ID。 |
| LLB COLLISION | 0 | 在同一时刻访问了LLB上的同一块内存,记录产生冲突的次数。 |
| NPC-CORE | NPC_0 | 核函数使用的NPC Core的ID。 |
| L1 COLLISION TYPE | L1_COLS_TO_MEM | 在同一时刻访问了L1上的同一块内存,产生冲突,类型标记为L1_COLS_TO_MEM。 |
| L1 COLLISION VAL | 0 | 访问L1时产生冲突的次数。 |
| IM COLLISION TYPE | IM_COLS_TO_MEM | 在同一时刻访问了IM(Intermediate Buffer)上的同一块内存,产生冲突,类型标记为IM_COLS_TO_MEM。 |
| IM COLLISION VAL | 0 | 访问IM时产生冲突的次数。 |
4.5. STCPTI
4.5.1. 使用流程
使用STCPTI分析目标异构程序性能的流程如下:
在异构程序源代码中添加STCPTI性能数据采集代码。
包含头文件stcpti.h。
定义用于记录性能数据的STCpti_PerfDatas结构体。
调用
stcptiKernelContextCreate为当前进程创建核函数性能数据采集的上下文。调用
stcptiKernelEnable开始采集性能数据。执行核函数。
调用
stcDeviceSynchronize等待执行完成。调用
stcptiKernelGetPerfDatas获取核函数性能数据。调用
stcptiKernelDisable停止采集性能数据。输出核函数性能数据。输出方法和STCpti_PerfDatas结构体的元素有关,详细的元素说明,请参见数据类型章节。
调用
stcptiKernelContextRelease为当前进程释放核函数性能数据采集的上下文。
编译添加了性能数据代码采集的异构程序,编译时需要添加链接选项
-lprofiler_stc和-ltracer_stc。以在matrix-multiply.hc中添加STCPTI性能数据采集代码后的matrix-multiply-stcpti.hc为例:$ stcc --rtlib=compiler-rt matrix-multiply-stcpti.hc -DNCORE=8 -lprofiler_stc -ltracer_stc -o matrix-multiply-stcpti
执行编译得到的二进制文件。
$ ./matrix-multiply-stcpti
4.5.2. 代码示例
添加了STCPTI性能数据采集代码后,matrix-multiply-stcpti.hc的完整示例代码如下:
/*
* Copyright (c) 2019-2021 北京希姆计算科技有限公司 (Stream Computing Inc.)
* All Rights Reserved.
*
* NOTICE: All intellectual and technical information contained herein
* are proprietary to Stream Computing Inc. Any unauthorized disemination,
* copying or redistribution of this file via any medium is strictly prohibited,
* unless you get a prior written permission or an applicable license agreement
* from Stream Computing Inc.
*/
/*
* This example uses internal instructions to do matrix multiply.
*/
#include <asm_macro.h>
#include <hpe.h>
#include <npurt.h>
#include <stdio.h>
#if !defined(__SHC_NPU_COMPILE__)
#include <stcpti.h>
#endif
// number of left matrix's col and right matrix's row
#define LCOL_RROW 8
// local_left * local_right = local_out
__device__ void matmul(__fp16 *local_out, __fp16 *local_left,
__fp16 *local_right) {
int shape1, shape2;
// do matrix multiply and result must be stored in IM buffer
shape1 = DEFINE_SHAPE(LCOL_RROW, 1);
shape2 = DEFINE_SHAPE(1, LCOL_RROW);
CONFIG_VE_BC_CSR(shape1, shape2, 0, 0);
memul_mm((__fp16 *)IM_BUFFER_START, local_left, local_right);
// move result from IM buffer to local memory
shape1 = DEFINE_SHAPE(1, 1);
shape2 = 0;
CONFIG_VE_CSR(shape1, shape2, 0, 0);
mov_m(local_out, (__fp16 *)IM_BUFFER_START);
}
__global__ void matmul_kernel(__fp16 *global_out, __fp16 *global_left,
__fp16 *global_right) {
__local__ __fp16 local_left[LCOL_RROW];
__local__ __fp16 local_right[LCOL_RROW];
__local__ __fp16 local_out;
__shared__ __fp16 share_out[CoreNum];
printf("CoreNum is %d\n", CoreNum);
// copy right matrix to each core
memcpy(local_right, global_right, LCOL_RROW * sizeof(__fp16));
// copy a row of left matrix for each core
memcpy(local_left, global_left + CoreID * LCOL_RROW,
LCOL_RROW * sizeof(__fp16));
// matrix multiply
matmul(&local_out, local_left, local_right);
// copy result in local memory of each core to shared memory
memcpy(share_out + CoreID, &local_out, sizeof(__fp16));
// sync to wait each of the core compute share_out data filled
sync();
if (CoreID == 0) {
// copy result in share memory of each core to global memory
memcpy(global_out, share_out, CoreNum * sizeof(__fp16));
}
}
#define NCORE 8
int main(void) {
__fp16 *dev_left, *dev_right, *dev_out;
// define struct for recording performance data
STCpti_PerfDatas perf_data = {0};
// enable stcpti
stcptiKernelContextCreate();
stcptiKernelEnable();
// left matrix data for 8 cores
__fp16 host_left[8 * LCOL_RROW] = {
0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, // row1
1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, 1.0, // row2
2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, 2.0, // row3
3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, 3.0, // row4
4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, 4.0, // row5
5.0, 5.0, 5.0, 5.0, 5.0, 5.0, 5.0, 5.0, // row6
6.0, 6.0, 6.0, 6.0, 6.0, 6.0, 6.0, 6.0, // row7
7.0, 7.0, 7.0, 7.0, 7.0, 7.0, 7.0, 7.0, // row8
};
// right matrix data
__fp16 host_right[LCOL_RROW] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0};
// copy left matrix to device
int mat_size_left = NCORE * LCOL_RROW * sizeof(__fp16);
stcMalloc((void **)&dev_left, mat_size_left);
stcMemcpy(dev_left, host_left, mat_size_left, stcMemcpyHostToDevice);
// copy right matrix to device
int mat_size_right = LCOL_RROW * sizeof(__fp16);
stcMalloc((void **)&dev_right, mat_size_right);
stcMemcpy(dev_right, host_right, mat_size_right, stcMemcpyHostToDevice);
// allocate result buffer in device
int mat_size_out = NCORE * sizeof(__fp16);
__fp16 host_out[NCORE];
stcMalloc((void **)&dev_out, mat_size_out);
matmul_kernel<<<NCORE>>>(dev_out, dev_left, dev_right);
stcDeviceSynchronize();
// copy result from device to host
stcMemcpy(host_out, dev_out, mat_size_out, stcMemcpyDeviceToHost);
printf("matrix multiply result:");
for (int i = 0; i < NCORE; i++)
printf("%.1f, ", (float)(host_out[i]));
printf("\n");
// get performance data
stcptiKernelGetPerfDatas(&perf_data);
stcptiKernelDisable();
const char* name = NULL;
for (int i = 0; i < perf_data.kernelPerfDataSize; i++) {
STCpti_KernelPerfDatas *kernel_perf_datas_ptr =
&perf_data.pKernelPerfDatas[i];
for (int j = 0; j < kernel_perf_datas_ptr->kernelNpcPerfDataSize; j++) {
STCpti_KernelNpcPerfData *kernel_npc_perf_data_ptr =
&kernel_perf_datas_ptr->arrKernelNpcPerfData[j];
for (int m = 0; m < STC_PTI_EVENT_ID_SYSDMA0_DMA_ID; m++) {
stcptiGetEventNameFromID(m, &name);
printf("kernel: %d npc: %d event %02d %s [%u]\n", i, j, m, name,
kernel_npc_perf_data_ptr->event[m]);
}
}
for ( int k = STC_PTI_EVENT_ID_SYSDMA0_DMA_ID; k < STC_PTI_EVENT_ID_MAX; k++ ){
stcptiGetEventNameFromID(k, &name);
STCpti_KernelDmaPerfData* kernel_dma_perf_data_ptr =
&(kernel_perf_datas_ptr->kernelDmaPerfData);
printf("kernel: %d dma event %02d %s [%u]\n", i, k, name,
kernel_dma_perf_data_ptr->event[ k - STC_PTI_EVENT_ID_SYSDMA0_DMA_ID]);
}
}
stcptiKernelContextRelease();
stcFree(dev_left);
stcFree(dev_right);
stcFree(dev_out);
return 0;
}
其中,STCPTI性能数据采集代码如下,省略号部分代表其他代码:
......
// !defined(__SHC_NPU_COMPILE__)宏用于控制仅在主机端代码进行编译时生效。
#if !defined(__SHC_NPU_COMPILE__)
#include <stcpti.h>
#endif
......
int main(void) {
......
// 定义用于记录性能数据的结构体。
STCpti_PerfDatas perf_data = {0};
......
// 为当前进程创建核函数性能数据采集的上下文。
stcptiKernelContextCreate();
// 开始采集性能数据。
stcptiKernelEnable();
......
// 执行核函数并等待执行完成。
matmul_kernel<<<NCORE>>>(dev_out, dev_left, dev_right);
stcDeviceSynchronize();
......
// 获取核函数性能数据。
stcptiKernelGetPerfDatas(&perf_data);
// 停止采集性能数据。
stcptiKernelDisable();
// 输出核函数性能数据。
const char* name = NULL;
for (int i = 0; i < perf_data.kernelPerfDataSize; i++) {
STCpti_KernelPerfDatas *kernel_perf_datas_ptr =
&perf_data.pKernelPerfDatas[i];
for (int j = 0; j < kernel_perf_datas_ptr->kernelNpcPerfDataSize; j++) {
STCpti_KernelNpcPerfData *kernel_npc_perf_data_ptr =
&kernel_perf_datas_ptr->arrKernelNpcPerfData[j];
for (int m = 0; m < STC_PTI_EVENT_ID_SYSDMA0_DMA_ID; m++) {
stcptiGetEventNameFromID(m, &name);
printf("kernel: %d npc: %d event %02d %s [%u]\n", i, j, m, name,
kernel_npc_perf_data_ptr->event[m]);
}
}
for ( int k = STC_PTI_EVENT_ID_SYSDMA0_DMA_ID; k < STC_PTI_EVENT_ID_MAX; k++ ){
stcptiGetEventNameFromID(k, &name);
STCpti_KernelDmaPerfData* kernel_dma_perf_data_ptr =
&(kernel_perf_datas_ptr->kernelDmaPerfData);
printf("kernel: %d dma event %02d %s [%u]\n", i, k, name,
kernel_dma_perf_data_ptr->event[ k - STC_PTI_EVENT_ID_SYSDMA0_DMA_ID]);
}
}
// 为当前进程释放核函数性能数据采集的上下文。
stcptiKernelContextRelease();
......
}
4.5.3. 接口定义
4.5.3.1. stcptiKernelContextCreate
函数描述:为当前进程创建核函数性能数据采集的上下文。
函数类型:同步函数
函数定义:
__host__ stcProfilerResult_t stcptiKernelContextCreate()
函数参数:
None
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.2. stcptiKernelContextRelease
函数描述:释放当前进程的核函数性能数据采集的上下文。
函数类型:同步函数
函数定义:
__host__ stcProfilerResult_t stcptiKernelContextRelease()
函数参数:
None
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.3. stcptiKernelContextReleaseAll
函数描述:释放所有进程的核函数性能数据采集的上下文。
函数类型:同步函数
函数定义:
__host__ stcProfilerResult_t stcptiKernelContextReleaseAll()
函数参数:
None
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.4. stcptiKernelEnable
函数描述:启动当前进程的性能数据采集。
函数类型:同步函数
函数定义:
__host__ stcProfilerResult_t stcptiKernelEnable()
函数参数:
None
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.5. stcptiKernelDisable
函数描述:停止当前进程的性能数据采集。
函数类型:同步函数
__host__ stcProfilerResult_t stcptiKernelDisable()
函数参数:
None
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.6. stcptiKernelGetPerfDatas
函数描述:获取当前进程的性能数据采集结果。
函数类型:同步函数
函数定义:
__host__ stcProfilerResult_t stcptiKernelGetPerfDatas(struct STCpti_PerfDatas *perf_data)
函数参数:
| 名称 | 输入/输出 | 类型 | 描述 |
|---|---|---|---|
| perf_data | 输出参数 | STCpti_PerfDatas | 用于返回所有核函数在所有NPC上的性能数据。详细的数据类型描述,请参见STCpti_PerfDatas章节。 |
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.7. stcptiGetEventNameFromID
函数描述:获取指定性能数据采集事件的值对应的名称。
函数类型:同步函数
函数定义:
__host__ stcProfilerResult_t stcptiGetEventNameFromID(int e, const char **eventName);
函数参数:
| 参数名称 | 输入/输出 | 类型 | 描述 |
|---|---|---|---|
| e | 输入参数 | int | 待查询的性能数据采集事件的值。 |
| eventName | 输出参数 | const char ** | 查询到的event名称。event的值和名称的对应关系,请参见stcPtiEventID_t章节。 |
函数返回值:
| 类型 | 描述 |
|---|---|
| stcProfilerResult_t | 详细的数据类型描述,请参见stcProfilerResult_t章节。 |
4.5.3.8. stcptiKernelIsMcuCycle32Ovf
函数描述:判断32位的MCU Cycle寄存器是否溢出。
函数类型:同步函数
函数定义:
__host__ bool stcptiKernelIsMcuCycle32Ovf(struct STCpti_KernelNpcPerfData kernel_perf_data);
函数参数:
| 名称 | 输入/输出 | 类型 | 描述 |
|---|---|---|---|
| kernel_perf_data | 输入参数 | STCpti_KernelNpcPerfData | 需要查询的NPC性能数据。详细的数据类型描述,请参见STCpti_PerfDatas章节。 |
函数返回值:
| 类型 | 描述 |
|---|---|
| bool | - 1:溢出。 - 0:未溢出。 |
4.5.3.9. stcptiKernelGetMcuCycle64
函数描述:获取64位的MCU cycle数值。
函数类型:同步函数
函数定义:
__host__ uint64_t stcptiKernelGetMcuCycle64(struct STCpti_KernelNpcPerfData kernel_perf_data);
函数参数:
| 名称 | 输入/输出 | 类型 | 描述 |
|---|---|---|---|
| kernel_perf_data | 输入参数 | STCpti_KernelNpcPerfData | 需要查询的NPC性能数据。详细的数据类型描述,请参见STCpti_PerfDatas章节。 |
函数返回值:
| 类型 | 描述 |
|---|---|
| uint64_t | 获取到的MCU cycle数值。 |
4.5.3.10. stcptiKernelIsMcuCycle64Ovf
函数描述:判断64位的MCU Cycle寄存器是否溢出。
函数类型:同步函数
函数定义:
__host__ bool stcptiKernelIsMcuCycle64Ovf(struct STCpti_KernelNpcPerfData kernel_perf_data);
函数参数:
| 参数名称 | 输入/输出 | 类型 | 描述 |
|---|---|---|---|
| kernel_perf_data | 输入参数 | STCpti_KernelNpcPerfData | 需要查询的NPC性能数据。详细的数据类型描述,请参见STCpti_PerfDatas章节。 |
函数返回值:
| 类型 | 描述 |
|---|---|
| bool | - 1:溢出。 - 0:未溢出。 |
4.5.4. 数据类型
4.5.4.1. STCpti_PerfDatas
STCpti_PerfDatas结构体的属性如下:
| 属性名称 | 属性类型 | 属性描述 |
|---|---|---|
| pKernelPerfDatas | STCpti_KernelPerfDatas * | STCpti_KernelPerfDatas数组的指针,保存了所有核函数的性能数据。该数组的每个元素对应一个核函数中采集到的性能数据,包括在每个NPC上的性能数据和sysDMA相关的性能数据。 |
| kernelPerfDataSize | size_t | STCpti_KernelPerfDatas数组的大小。 |
其中,STCpti_KernelPerfDatas结构体的属性如下:
| 属性名称 | 属性类型 | 属性描述 |
|---|---|---|
| pKernelName | char * | 指向Kernel名称的指针。 |
| arrKernelNpcPerfData | STCpti_KernelNpcPerfData * | STCpti_KernelNpcPerfData数组的指针,保存了单个核函数使用NPC的性能数据。该数组的每个元素对应一个NPC上的性能数据,包括MCU指令、VME指令、MME指令、MTE指令等的性能信息,例如cycle数等。 |
| kernelNpcPerfDataSize | size_t | STCpti_KernelNpcPerfData数组的大小。 |
| kernelDmaPerfData | STCpti_KernelDmaPerfData | 保存了sysDMA相关的性能数据,例如LLB、DDR之间搬运的数据量和带宽。 |
4.5.4.2. stcProfilerResult_t
数据描述:记录了调用STCPTI接口的结果。支持的结果类型如下:
| 枚举成员 | 枚举值 | 描述 |
|---|---|---|
| STC_PROFILER_ERROR | -1 | 接口调用失败。 |
| STC_PROFILER_SUCCESS | 0 | 接口调用成功。 |
| STC_PROFILER_ERROR_INVALID_ARGU | 1 | 调用接口时传入了无效的参数。 |
| STC_PROFILER_ERROR_UNKNOW | 2 | 调用接口时产生了未知的错误。 |
4.5.4.3. stcPtiEventID_t
数据描述:记录了性能数据采集事件的类型。支持的类型如下:
| 枚举成员 | 枚举值 | 描述 |
|---|---|---|
| STC_PTI_EVENT_ID_MCU_CYCLE | 0 | MCU指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_VME_CYCLE | 1 | 希姆计算自定义向量运算指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_MME_CYCLE | 2 | MME指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_VEC_CYCLE | 3 | RISC-V原生向量运算指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYN_CYCLE | 4 | SYNC指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_MTE_TOTAL_CYCLE | 5 | 所有类型MTE指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_VME_INST | 6 | 希姆计算自定义向量运算指令的数量。 |
| STC_PTI_EVENT_ID_MME_INST | 7 | MME指令的数量。 |
| STC_PTI_EVENT_ID_VEC_INST | 8 | RISC-V原生向量运算指令的数量。 |
| STC_PTI_EVENT_ID_SYN_INST | 9 | SYNC指令的数量。 |
| STC_PTI_EVENT_ID_MTE_PLD_INST | 10 | MTE pld指令的数量。 |
| STC_PTI_EVENT_ID_MTE_ICMOV_INST | 11 | MTE icmov指令的数量。 |
| STC_PTI_EVENT_ID_MTE_MOV_INST | 12 | MTE mov指令的数量。 |
| STC_PTI_EVENT_ID_PAL_VME_MME_CYCLE | 13 | 并行执行VME、MME指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_PAL_MTE_MME_CYCLE | 14 | 并行执行MTE、MME指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_PAL_VME_MTE_CYCLE | 15 | 并行执行VME、MTE指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_PAL_TOTAL_CYCLE | 16 | 并行执行VME、MME、MTE指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_MTE_ICMOV_CYCLE | 17 | MTE icmov指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_MTE_L12LLB_CYCLE | 18 | 从L1向LLB搬运数据耗费的cycle数。 |
| STC_PTI_EVENT_ID_MTE_LLB2L1_CYCLE | 19 | 从LLB向L1搬运数据耗费的cycle数。 |
| STC_PTI_EVENT_ID_MTE_PLD_CYCLE | 20 | MTE pld指令耗费的cycle数。 |
| STC_PTI_EVENT_ID_MTE_PLD_BYTE | 21 | 通过MTE pld指令搬运的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_MTE_L12LLB_BYTE | 22 | 从L1向LLB搬运的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_MTE_LLB2L1_BYTE | 23 | 从LLB向L1搬运的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_MTE_ICMOV_BYTE | 24 | 通过MTE icmov指令搬运的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_SYN_WAIT_CYCLE | 25 | 开始SYNC后NPC Cluster内所有Core完成运算所等待的cycle数。 |
| STC_PTI_EVENT_ID_VEC_SLOT_WAIT_CYCLE | 26 | 向量运算指令从接收到执行所等待的cycle数。 |
| STC_PTI_EVENT_ID_MME_SLOT_WAIT_CYCLE | 27 | MME指令从接收到执行所等待的cycle数。 |
| STC_PTI_EVENT_ID_MTE_SLOT_WAIT_CYCLE | 28 | MTE指令从接收到执行所等待的cycle数。 |
| STC_PTI_EVENT_ID_MIF_L1_CONFLICT_CYCLE | 29 | 通过MIF(Memory Interface)访问L1时产生冲突的cycle数。 |
| STC_PTI_EVENT_ID_MIF_IM_CONFLICT_CYCLE | 30 | 通过MIF访问IM时产生冲突的cycle数。 |
| STC_PTI_EVENT_ID_MCU_EVENT3_TYPE_CNT | 31 | 可配置寄存器。 |
| STC_PTI_EVENT_ID_MCU_EVENT4_TYPE_CNT | 32 | 可配置寄存器。 |
| STC_PTI_EVENT_ID_MCU_EVENT5_TYPE_CNT | 33 | 可配置寄存器。 |
| STC_PTI_EVENT_ID_MCU_EVENT6_TYPE_CNT | 34 | 可配置寄存器。 |
| STC_PTI_EVENT_ID_MCU_EVENT6H_TYPE_CNT | 35 | STC_PTI_EVENT_ID_MCU_EVENT6_TYPE_CNT的高32位。 |
| STC_PTI_EVENT_ID_MCU_MCOUNTER_OVERFLOW | 36 | 判断性能数据采集事件的计数是否溢出。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_ID | 37 | DMA控制器0的ID。 |
| STC_PTI_EVENT_ID_SYSDMA0_LLB_CONFLICT_CYCLE | 38 | 通过DMA控制器0访问LLB时产生冲突的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_C0_CYCLE0 | 39 | DMA控制器0上Channel 0最近一次数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_C0_CYCLE1 | 40 | DMA控制器0上Channel 0所有数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_C0_BYTE | 41 | DMA控制器0上Channel 0传输的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_C1_CYCLE0 | 42 | DMA控制器0上Channel 1最近一次数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_C1_CYCLE1 | 43 | DMA控制器0上Channel 1所有数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA0_DMA_C1_BYTE | 44 | DMA控制器0上Channel 0传输的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_ID | 45 | DMA控制器1的ID。 |
| STC_PTI_EVENT_ID_SYSDMA1_LLB_CONFLICT_CYCLE | 46 | 通过DMA控制器1访问LLB时产生冲突的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_C0_CYCLE0 | 47 | DMA控制器1上Channel 0最近一次数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_C0_CYCLE1 | 48 | DMA控制器1上Channel 0所有数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_C0_BYTE | 49 | DMA控制器1上Channel 0传输的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_C1_CYCLE0 | 50 | DMA控制器1上Channel 1最近一次数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_C1_CYCLE1 | 51 | DMA控制器1上Channel 1所有数据传输耗费的cycle数。 |
| STC_PTI_EVENT_ID_SYSDMA1_DMA_C1_BYTE | 52 | DMA控制器1上Channel 1传输的数据量,单位为字节。 |
| STC_PTI_EVENT_ID_MAX | 53 | stcPtiEventID_t枚举定义的边界值。 |
4.6. 已知问题
在CentOS7环境下stc-prof抓取不到stcGetErrorString接口,因此会导致统计的调用次数与其他os环境不一致。