HPE使用指南
HPE概述
HPE(Heterogeneous Programming Engine)是面向硬件产品的异构编程引擎,包括驱动、运行时、监控调试工具等模块,在CPU+NPU的异构环境中提供了服务器识别NPU以及完成NPU基本操作的能力。
HPE支持通过C++语言扩展接口开发异构程序,如果您有使用Python语言扩展接口开发异构程序的需求,请独立安装HPE-Python。异构程序包括在CPU上运行的主机端程序和在NPU上运行的设备端程序,HPE为开发、编译、运行主机端程序和设备端程序提供了完整的工具链。
前提条件
已安装异构编程引擎HPE,具体操作,请参见STCRP安装指南。
使用stc-topo感知设备拓扑
stc-topo是一款用于检查服务器硬件拓扑的工具。它能够展示机器内NPU的互连方式、NUMA架构等关键信息。
大模型训练通常依赖多块NPU进行并行计算,此时NPU间的通信效率对整体性能至关重要。硬件拓扑结构直接决定了训练任务的性能上限。通过 stc-topo 查看这些拓扑细节,有助于针对性优化通信策略、资源分配和模型并行方案,从而显著提升训练效率并降低成本。
说明:在Docker环境中不支持使用stc-topo命令。
示例如下:
$ stc-topo
GPU0 GPU1 GPU2 GPU3 GPU4 GPU5 GPU6 GPU7 CPU Affinity NUMA Affinity
GPU0 LOC PIX PIX PIX SYS SYS SYS SYS 0-27,56-83 0
GPU1 PIX LOC PIX PIX SYS SYS SYS SYS 0-27,56-83 0
GPU2 PIX PIX LOC PIX SYS SYS SYS SYS 0-27,56-83 0
GPU3 PIX PIX PIX LOC SYS SYS SYS SYS 0-27,56-83 0
GPU4 SYS SYS SYS SYS LOC PIX PIX PIX 28-55,84-111 1
GPU5 SYS SYS SYS SYS PIX LOC PIX PIX 28-55,84-111 1
GPU6 SYS SYS SYS SYS PIX PIX LOC PIX 28-55,84-111 1
GPU7 SYS SYS SYS SYS PIX PIX PIX LOC 28-55,84-111 1
参数说明:
| 参数 | 说明 |
|---|---|
| LOC | 本地连接。 |
| PIX | 连接最多遍历一个PCIe桥。 |
| PXB | 连接跨越多个PCIe桥(不跨越PCIe主机桥)。 |
| PHB | 连接遍历PCIe以及PCIe主机桥。 |
| SYS | 连接遍历PCIe以及NUMA节点之间的SMP互连(例如,QPI/UPI)。 |
| CPU Affinity | 离当前GPU最近的CPU编号。 |
| NUMA Affinity | 所属NUMA节点。 |
使用stc-smi检测设备状态
stc-smi用于管理和监视NPU设备,包括查看设备信息、资源使用情况等。
命令说明
执行stc-smi --help获取stc-smi命令的使用方法:
$ stc-smi --help
Usage: stc-smi [OPTIONS]
-h, --help Print this help, and exit.
<no arguments> Display a summary of NPU devices connected to the system.
--version Print version number.
-l, --list Display NPU devices list.
DISPLAY OPTIONS:
-q, --query Display all info of all the NPU devices, the following options can be selected.
[plus optional]
-i, --id= Specify the NPU device to be operated.
-c, --cluster= Specify cluster number.
-p, --pci Display NPU device pci info.
--task Display running tasks info.
--query-npu= Query information of the NPU devices, select the option from query list.
[query list optional]
index Zero based index of the NPU.
name The official product name of the NPU.
serial This number matches the serial number physically printed on each board. It is a globally unique immutable alphanumeric value.
power.draw The last measured power draw for the entire board, in watts.
temperature.npu Core NPU temperature. in degrees C.
utilization.npu Percent of time over the past sample period during which one or more kernels was executing on the NPU.The sample period is 1 second.
memory.total Total installed NPU memory.
memory.used Total memory allocated by active contexts.
[mandatory]
--format= Comma separated list of format options:
csv - comma separated values (MANDATORY).
OPERATION OPTIONS:
-s, --set Set the specified parameters of the specified device.
[plus optional]
-i, --id= Specify the NPU device to be operated(MANDATORY).
--vsoc= Specify soc voltage, the effective value is 800~950.
--vmac= Specify mac voltage, the effective value is 550~950.
--freq= Specify NPU soc frequency, only support value 1000, 900(MHZ).
-g, --get Get specified parameter.
[plus optional]
-i, --id= Specify the NPU device to be operated(MANDATORY).
-v, --voltage Display soc and mac voltage.
--freq Display NPU device soc frequency and ddr frequency.
--temperature Display NPU device temperature info.
-r, --reset Reset specified NPU device.
[plus optional]
-i, --id= Specify NPU device.
-m, --monitor Get specified parameter.
[plus optional]
-i, --id= Specify the NPU device to be operated(MANDATORY).
--enable Enable the temperature and voltage monitor.
--disable Disable the temperature and voltage monitor.
--temperature= Temperature alarm value.
--shutdown-threshold= Temperature threshold for shutdown.
--base= Lower limit of voltage alarm value(Must set with -o, --offset).
-o, --offset= Voltage alarm value interval value(Must set with -b, --base).
-S, --save Save local config as default config.
[plus optional]
-i, --id= Specify the NPU device to be operated(MANDATORY).
-u, --upgrade= Upgrade specified NPU ctrl firmware of specified device.This operation requires root rights.
[plus optional]
-i, --id= Specify the NPU device to be operated(MANDATORY).
--mcu-upgrade= Upgrade specified MCU firmware of specified device.This operation requires root rights.
[plus optional]
-i, --id= Specify the NPU device to be operated(MANDATORY).
--startup startup NPU when shutdown by Temperature threshold.
stc-smi命令支持以下选项:
-
获取信息
选项 描述 -h, --help显示stc-smi命令的帮助信息并退出,包括支持的选项以及描述。 no arguments 显示连接到系统的NPU设备的摘要信息,包括设备索引、频率、功耗、内存使用、进程等。 --version显示stc-smi的版本信息。 -l, --list显示NPU设备列表。 -
显示选项
选项 描述 -q, --query显示NPU设备的所有信息,可以与以下选项联合使用: -i, --id=:指定要查看的NPU设备,后跟NPU设备ID。例如,stc-smi -q -i 0查看NPU设备0。-c, --cluster=:指定要查看的NPC Cluster,后跟NPC Cluster ID。例如,stc-smi -q -c 0查看所有NPU设备的NPC Cluster 0。-p, --pci:显示NPU设备的PCI总线相关信息,包括Bus ID、板卡标识符、传输速率等。例如,stc-smi -q -i 0 -p查看NPU设备0的PCI总线相关信息。--task:显示任务信息,例如stc-smi -q -i 0 -c 0 --task查看NPU设备0的NPC Cluster 0上的任务。
--query-npu=查询NPU设备的指定信息,需要同时指定信息项( --query-npu=)和显示格式(--format=)。如果希望查询多项信息,以英文逗号分隔即可,例如stc-smi --query-npu=index,name --format=csv查询NPU设备的索引和产品名称。支持查询的信息项如下:index:NPU设备的索引,从0开始。name:NPU的产品名称。serial:全球唯一的不可变的字母数字编号,与实际印刷在每块板上的序列号相匹配。power.draw:整个板卡的功耗,单位为W。temperature.npu:NPU核心的温度,单位为℃。utilization.npu:在上个采样时间(1秒)内,NPU上执行核函数所占采样时间的百分比。memory.total:NPU全局内存的总大小。memory.used:运行任务的上下文占用的全局内存大小,包括软件栈占用的固定内存、运行代码占用的内存等。
csv:逗号分隔格式。
-
操作选项:
选项 描述 -s, --set设置指定的NPU设备参数,可以与以下选项联合使用: -i, --id=:指定要设置参数的NPU设备,后跟NPU设备ID。--vsoc=:指定soc的电压,有效值为800 ~ 950。--vmac=:指定mac的电压。有效值为550 ~ 950。--freq=:指定NPU soc的频率。只支持1000MHZ、900MHZ。
-g, --get获取指定的参数,可以与以下选项联合使用: -i, --id=:获取指定NPU设备的参数,后跟NPU设备ID。-v,--voltage:显示soc和mac的电压。--freq:显示NPU设备的soc频率和ddr频率。--temperature:显示NPU设备的温度信息。
-r, --reset重置指定的NPU设备,可以与以下选项联合使用: -i, --id=:指定要重置的NPU设备。
-m, --monitor设置监视器相关参数,可以与以下选项联合使用: -i, --id=:指定要监控的NPU设备。--enable:开启温度和电压监视器。--disable:关闭温度和电压监视器。--temperature=:温度告警阈值。--shutdown-threshold=:关卡温度阈值。--base=:电压报警值下限(必须配合-o,--offset设置)。-o, --offset=:电压报警值间隔值(必须配合-b,--base设置)。
-S, --save保存当前监视器配置为默认配置。可以与以下选项联合使用: -i, --id=:指定要保存配置的NPU设备。
-u, --upgrade升级指定设备的NPU ctrl firmware固件,需要有root权限。可以与以下选项联合使用: -i, --id=:指定要升级的NPU设备。
--mcu-upgrade升级指定设备的MCU固件,需要有root权限。可以与以下选项联合使用: -i, --id=:指定要升级的NPU设备。
--startup启动因超过温度阈值自动关卡的NPU设备。可以与以下选项联合使用: -i, --id=:指定要重启的NPU设备。
命令示例
本章节以在HPE V1.9.7、STCP920中stc-smi命令为例演示执行效果。
显示摘要信息
查看运行中目标程序的摘要信息。
$ stc-smi
+------------------------------------------------------------------------------+
| STC-SMI: 1.8.5 Driver Version: 1.9.6 |
+------------------------------------------------------------------------------+
| NPU Name Frequency| Bus-Id | NPU-Util |
| Sta Temp Power| ClusterCount | Memory Used /Total |
+==============================================================================+
| 0 STCP920 1000M| 0:65:00.0 | 25 % |
| N/A 36.6C 33.7W / 160W| 4 | 624.05M /16.00G |
+------------------------------------------------------------------------------+
+------------------------------------------------------------------------------+
| Processes: |
| NPU CLUSTER Pid processName MemoryUsed|
+==============================================================================+
| 0 0 583900 hello_world 45.62K|
+------------------------------------------------------------------------------+
各项信息的描述如下:
| 项目 | 描述 |
|---|---|
| STC-SMI | stc-smi工具的版本信息。 |
| Driver Version | NPU Driver的版本信息。 |
| NPU | NPU设备的索引。 |
| Name | NPU设备的产品名称。 |
| Frequency | NPU设备的频率信息。 |
| Sta | NPU设备板卡状态。 |
| Temp | NPU设备核心的温度信息,合理范围为25℃~90℃。 |
| Power | NPU设备的功耗信息,包括实时功耗/额定功耗。 |
| Bus-Id | NPU设备所使用PCI总线的ID。 |
| NPU-Util | NPU设备的使用率,即使用的NPC占NPU设备内所有NPC的比例。 |
| ClusterCount | NPU设备内NPC Cluster的数量。 |
| Memory Used /Total | NPU设备的内存信息,包括已用内存/总内存的大小。 |
| NPU | 执行中任务所使用NPU设备的ID。 |
| CLUSTER | 执行中任务所使用NPC Cluster的ID。 |
| Pid | 执行中任务的系统进程ID。 |
| processName | 执行中任务的系统进程名称。 |
| MemoryUsed | 执行中任务使用的内存大小。 |
示例摘要信息中,NPU设备的Memory Used为624.05M,其中624M是软件栈固定使用的内存大小,剩下的则是运行目标程序使用的内存,即Processes中的MemoryUsed。
设置soc频率
您可以根据需要设置soc频率:
$ stc-smi -s --freq=900 -i 0
set freq value 900M OK!
您也可以使用--east和--west分别设置芯片东侧和西侧的频率。
$ stc-smi -s --freq=900 --east -i 0
set freq value 900M OK!
$ stc-smi -g --freq -i 0
stc device soc west frequency 1000
stc device soc east frequency 900
stc device ddr frequency 3733
显示设备列表
$ stc-smi --list
NPU: 0
STCP920 BUS-ID: 0:03:00.0 (01PSF60000170610)
示例结果显示检测到一个NPU设备,产品名称为STCP920,所使用PCI总线的ID为0:03:00.0,设备序列号为01PSF60000170610。
获取指定设备的信息
-
您可以根据需要获取设备电压信息。
$ stc-smi -g -v -i 0
stc device voltage info vsoc:840 mv vmac:720 mv -
您可以根据需要获取设备频率。
$ stc-smi -g --freq -i 0
stc device soc west frequency 1000
stc device soc east frequency 1000
stc device ddr frequency 3733 -
您可以根据需要获取设备温度信息。
$ stc-smi -g --temperature -i 0
NPU core temperature 32.78.
PCIE board front tempertaure 24.25.
PCIE board back temperature 28.06. -
您可以根据需要获取指定设备的所有信息,以NPU 0为例:
$ stc-smi -q - i 0
NPU: 0
Product Name: STCP920
Product Brand: STREAMCOMPUTING
Sn: 01PSF60000060709
Chip count: 1
Temperature: 32C
AlertTemperature: 91C
ShutdownTemperature: 95C
Status: on
Power: 27W
Cluster count: 4
Frequency: 1000M
Bus: 0000:03:00.0
Vendor: 23e2 Device: 0100
Current link speed: 16.0 GT/s PCIe
Max link speed: 16.0 GT/s PCIe
Current link width: 16
Max link width: 16
Write bytes: 0B
Read bytes: 0B
HPE version: 1.9.7
Driver: 1.9.6
Chip version: 20200102
MCU firmware: 10.0.13
NPU ctrl firmware: 10.3.7
Cluster 0:
Frequency: 1000M DMA count: 2 Util: 0 % Status: WORK Memory Used / Total: 156.00M / 4.00G
Cluster 1:
Frequency: 1000M DMA count: 2 Util: 0 % Status: WORK Memory Used / Total: 156.00M / 4.00G
Cluster 2:
Frequency: 1000M DMA count: 2 Util: 0 % Status: WORK Memory Used / Total: 156.00M / 4.00G
Cluster 3:
Frequency: 1000M DMA count: 2 Util: 0 % Status: WORK Memory Used / Total: 156.00M / 4.00G -
您可以根据需要获取指定NPC Cluster的所有信息,以NPC Cluster 0为例。
$ stc-smi -q -i 0 -c 0
NPU: 0
Cluster 0:
Frequency: 1000M DMA count: 2 Util: 0 % Status: WORK Memory Used / Total: 156.00M / 4.00G
各项的含义如下:
| 项目 | 描述 |
|---|---|
| Product Name | NPU设备的产品名称。 |
| Product Brand | NPU设备的品牌名称。 |
| Sn | NPU设备的SN。每个NPU设备的SN是唯一的,不会重复。 |
| Chip count | NPU设备的数量。 |
| Temperature | NPU设备核心的温度信息,合理范围为25℃~90℃。 |
| AlertTemperature | NPU设备告警温度。 |
| ShutdownTemperature | NPU设备关机温度。 |
| Status | NPU设备状态。 |
| Power | NPU设备的实时功耗,额定功耗为160W。 |
| Cluster count | NPU设备内NPC Cluster的数量。 |
| Frequency | NPU设备的频率信息。 |
| Bus | NPU设备所使用PCI总线的ID。 |
| Vendor/Device | PCIe厂商的ID。 |
| Current link speed | PCIe设备当前的连接速度,视主机的PCIe插槽而定,可能值包括16GT/S(GEN4)、8GT/S(GEN3)、5GT/S (GEN2)。 |
| Max link speed | PCIe设备支持的最高连接速度,视主机的PCIe插槽而定,可能值包括16GT/S(GEN4)、8GT/S(GEN3)、5GT/S (GEN2)。 |
| Current link width | PCIe设备当前连接的通道数。 |
| Max link width | PCIe设备支持连接的最大通道数。 |
| Write bytes | PCIe设备的写数据大小统计,数值动态变化。 |
| Read bytes | PCIe设备的读数据大小统计,数值动态变化。 |
| HPE version | 当前主机安装HPE异构编程引擎的版本信息。 |
| Driver | NPU Driver的版本信息。 |
| Chip version | 芯片的产品版本信息。 |
| MCU firmware | MCU固件的版本信息。 |
| NPU ctrl firmware | NPU ctrl固件的版本信息。 |
| Cluster | NPC Cluster的ID。 |
| Frequency | NPC Cluster的频率。 |
| DMA count | 当前NPC Cluster中DMA通道的数量。 |
| Util | 当前NPC Cluster的使用率,即使用的NPC占当前NPC Cluster内所有NPC的比例。 |
| Status | 当前NPC Cluster的状态信息,可能值:
|
| Memory Used/Total | 当前NPC Cluster的内存信息,包括已用内存/总内存的大小。 |
查询设备的指定信息
您可以根据需要查看NPU设备的指定信息:
-
查询NPU设备的利用率和已使用内存的大小。
$ stc-smi --query-npu=index,utilization.npu --format=csv -i 0
index, utilization.npu [%]
0, 0 % -
查询NPU已使用内存的大小。
$ stc-smi --query-npu=index,memory.used --format=csv -i 0
index, memory.used [MiB]
0, 765 MiB -
查询NPU设备温度和实时功耗。
$ stc-smi --query-npu=index,temperature.npu --format=csv -i 0
index, temperature.npu
0, 31 -
查询NPU设备的实时功耗
$ stc-smi --query-npu=index,power.draw --format=csv -i 0
index, power.draw [W]
0, 30.43 W
说明:
--query-npu支持指定的信息项,请参见命令说明章节。
也可同时查询多项,使用逗号分隔,回显会按照逗号分隔格式显示查询的信息。
$ stc-smi --query-npu=index,utilization.npu,memory.used,temperature.npu,power.draw --format=csv -i 0
index, utilization.npu [%], memory.used [MiB], temperature.npu, power.draw [W]
0, 0 %, 765 MiB, 31, 30.43 W
各项的含义如下:
| 项目 | 描述 |
|---|---|
| index | NPU设备的索引。 |
| utilization.npu | NPU设备的利用率,即使用的NPC占NPU设备内所有NPC的比例。 |
| memory.used | NPU设备已使用内存的大小。 |
| temperature.npu | NPU设备核心的温度信息。 |
| power.draw | NPU设备的实时功耗。 |
设置关卡温度阈值
为防止板卡长期在超过设计的最高温度下运行,从而影响板卡的使用寿命。您可以设置关卡温度阈值。当板卡的温度达到了关卡温度阈值时,将会清理当前板卡所有任务并设置为关卡状态。
-
温度监控功能默认不开启,需要先开启监控功能。
$ stc-smi -m --enable -i 0 -
设置NPU设备0的关卡温度阈值为90度。
$ stc-smi -m --shutdown-threshold=90 -i 0如果板卡因超过温度阈值自动关卡,在重新使用板卡时您需要手动开卡才能解除关卡状态:
$ stc-smi --startup -i 0 -
保存设置。
$ stc-smi --save -i 0
复位设备
在NPU设备状态异常时,您可以尝试复位设备。复位NPU设备0的命令示例如下:
警告:执行设备复位命令前,请确认设备上没有正在执行的任务。复位是针对整个NPU设备的,而非单个NPC Cluster。
$ stc-smi -r -i 0
说明:复位设备需要root用户权限。
更新固件
您可以分别使用--mcu-upgarde和-u,--upgrade选项升级指定设备的mcu固件和NPU ctrl固件。
说明:升级固件需要root用户权限。
$ stc-smi --mcu-upgrade STC_xxx.sdux -i 0
MCU firmware upgrade finish.
$ stc-smi -u STC_xxx.sdux -i 0
NPU ctrl firmware upgrade finish.
说明:固件更新详细升级步骤说明请参见固件更新指南。
使用stc-gdb调试异构程
stc-gdb是用于调试NPU异构程序。stc-gdb扩展了GDB(GNU Debugger),支持在Linux系统上调试主机端代码,控制运行在NPU上的程序。您可以使用stc-gdb方便地监视程序运行状态,获取和修改程序的中间运行结果,减轻程序开发过程中的调试工作量,提高开发效率。
stc-gdb具有如下特性:
-
完全兼容GDB原生命令。
-
⽀持同时调试主机端和设备端的代码。
-
⽀持调试使用NPU单核和多核的程序。
-
支持对设备端代码进行源码级和指令级的单步调试。
-
支持attach机制直接跟踪运行中的程序,方便定位到设备端代码。
-
支持检查和修改程序所使用核的寄存器、变量或其他内存数据。
说明:stc-gdb会将调试过程中产生的临时文件存储在/tmp目录中,因此请保证登录的用户拥有读写/tmp目录的权限。
stc-gdb支持的命令类别如下:
-
GDB原生命令和选项:命名及使用方式和GDB定义保持一致,例如添加软件断点(break/b)、硬件断点(hbreak/hb)、观察点(watch)等。
-
扩展命令和选项:扩展命令均使用stc作为前缀。
说明:扩展命令仅在异构程序运行在设备端时可用,具体的调试过程请参见调试示例章节。
使用流程
启动
有多种方式启动stc-gdb:
-
使用
stc-gdb命令直接启动stc-gdb,启动stc-gdb后,命令行将一直等待指令输入,直到退出stc-gdb。$ stc-gdb -
stc-gdb也能使用参数和选项启动,用来设定更多的调试环境。
-
启动stc-gdb时指定加载一个可执行程序。示例如下,启动stc-gdb时指定名为hello_world的可执行程序。
说明:hello_world示例源代码及编译方式可以参考代码示例。
$ stc-gdb hello_world -
如果需要在调试程序时,需要指定被调试程序的参数,可以在启动stc-gdb时添加
--args选项。示例如下,启动stc-gdb时指定名为hello_world的可执行程序,并且传入参数arg1和arg2。$ stc-gdb --args hello_world arg1 arg2
-
-
stc-gdb在启动时attach到运行中程序所在的进程。
$ stc-gdb --pid $(pid of process)说明:部分操作系统中需要sudo权限,请按照终端的提示进行提权操作。
调试
stc-gdb工具完全兼容GDB命令,提供大量的调试选项,满足大部分场景中调试主机端和设备端代码的需求。使用stc-gdb工具根据需求调试可执行程序。示例如下:
启动stc-gdb并指定可执行程序,在程序第12行设置断点,然后运行程序开始调试。运行程序开始调试后,可以执行命令控制程序运行、获取相关的信息。
(stc-gdb) b 12
(stc-gdb) run
退出
使用quit命令(简写为q)、exit命令或文件结束字符(通常为Ctrl+d)退出stc-gdb。
(stc-gdb) quit
自定义扩展调试命令
stc focus
stc focus命令用于查看或切换当前聚焦的NPC。通过stc focus命令聚焦到指定的NPC后,该stc-gdb进程的命令只会作用在指定的NPC上,方便您调试多核程序。示例如下:
-
查看当前聚焦调试的NPC,NPC坐标为[device 0, cluster 0, core 0]。
(stc-gdb) stc focus
[Focusing on logical device 0 cluster 0 core 0] -
将聚焦调试的NPC坐标从[device 0, cluster 0, core 0]切换到[device 0, cluster 0, core 2]。
(stc-gdb) stc focus device 0 cluster 0 core 2
[Switch from logical device 0 cluster 0 core 0 to logical device 0 cluster 0 core 2.] -
如果未指定完整的NPC坐标信息,则参照当前使用中NPC的坐标信息补全,例如自动补全device和cluster。
(stc-gdb) stc focus core 3
[Switch from logical device 0 cluster 0 core 2 to logical device 0 cluster 0 core 3.]
说明:NPC(即core)是运行异构程序的最小单元。一张AI推理卡(device)包括多个cluster,每个cluster包括多个NPC。在运行异构程序时可能需要使用多个NPC,为方便灵活操作每个NPC,规定使用[device x, cluster y, core z]的坐标形式标识唯一的NPC。
stc info
stc info命令用于查看当前程序占用核资源及运行状态相关信息,包括cluster列表、NPC列表、NPC状态、当前focus的NPC等。其中,可能的NPC状态包括:
-
BREAKPOINT:命中断点。
-
INTERRUPT:因Ctrl+C等操作中断。
-
SINGLESTEP:执行
n等命令后单步调试。
stc info命令的示例:
(stc-gdb) stc info
device cluster core phy-core pc status focus
0 0 0 0 0x1400180 BREAKPOINT *
0 0 1 1 0x1400180 BREAKPOINT
0 0 2 2 0x1400180 BREAKPOINT
0 0 3 3 0x1400180 BREAKPOINT
# 忽略部分回显
说明:focus列中的星号(*)表示当前使用的NPC为[device 0, cluster 0, core 0]。
调试示例
本章节展示使用stc-gdb工具通过设置断点、查看调用堆栈和focus等信息来调试hello_world的可执行程序的示例。
说明:hello_world程序代码请参考代码示例章节。
-
启动stc-gdb调试hello_world。
-
若hello_world未启动,可直接使用stc-gdb加载hello_world。执行
break(简写为b)命令为设备端代码添加断点,然后执行run(简写为r)开始运行。命中断点后,暂停运行程序。$ stc-gdb hello_world
(stc-gdb) b 12
Breakpoint 1 at 0xc: file hello_world.hc, line 12.
(stc-gdb) r
Breakpoint 1, hello () at hello_world.hc:12
12 printf("hello world from core %d/%d.n", CoreID, CoreNum); -
若hello_world在设备端运行中,查看pid为3296969,执行
attach(简写为at)命令链接hello_world所在的进程。执行break(简写为b)命令为设备端代码添加断点,然后执行continue(简写为c)继续运行。命中断点后,暂停运行程序。$ stc-gdb
(stc-gdb) attach 3296969
(stc-gdb) b 12
Breakpoint 1 at 0xc: file hello_world.hc, line 12.
(stc-gdb) c
Continuing.
Breakpoint 1, hello () at hello_world.hc:12
12 printf("hello world from core %d/%d.n", CoreID, CoreNum);
-
-
执行
backtrace(简写为bt)命令查看调用堆栈。Breakpoint 1, hello () at hello_world.hc:12
12 printf("hello world from core %d/%d.n", CoreID, CoreNum);
(stc-gdb) bt
#0 hello () at hello_world.hc:12 -
此时异构程序已经运行到设备端,可以执行扩展命令
stc focus查看当前使用的NPC,或者使用stc info查看NPC状态等更多信息。(stc-gdb) stc focus
[Focusing on logical device 0 cluster 0 core 0]
(stc-gdb) stc info
device cluster core phy-core pc status focus
0 0 0 0 0x140000c BREAKPOINT *
0 0 1 1 0x140000c BREAKPOINT
0 0 2 2 0x140000c BREAKPOINT
0 0 3 3 0x140000c BREAKPOINT
# 忽略部分回显 -
切换focus获取对应NPC的控制权,然后执行
continue(简写为c)继续运行。(stc-gdb) stc focus device 0 cluster 0 core 2
[Switch from logical device 0 cluster 0 core 0 to logical device 0 cluster 0 core 2.]
(stc-gdb) c
Continuing. -
执行
disassemble(简写为disass)命令查看当前pc附近的汇编指令。(stc-gdb) disass
Dump of assembler code for function hello():
0x01400000 <+0>: addi sp,sp,-16
0x01400002 <+2>: sw ra,12(sp)
0x01400004 <+4>: sw s0,8(sp)
0x01400006 <+6>: addi s0,sp,16
0x01400008 <+8>: j 0x140000c <hello()+12>
=> 0x0140000c <+12>: auipc ra,0x2
0x01400010 <+16>: jalr -946(ra) # 0x1401c5a <core_id_internal>
0x01400014 <+20>: sw a0,-12(s0)
0x01400018 <+24>: auipc ra,0x2
0x0140001c <+28>: jalr -890(ra) # 0x1401c9e <core_num_internal>
0x01400020 <+32>: lw a1,-12(s0)
0x01400024 <+36>: mv a2,a0
0x01400026 <+38>: lui a0,0x1407
0x0140002a <+42>: addi a0,a0,-1578 # 0x14069d6
0x0140002e <+46>: auipc ra,0x0
0x01400032 <+50>: jalr 118(ra) # 0x14000a4 <printf>
0x01400036 <+54>: j 0x140000c <hello()+12>
End of assembler dump. -
执行
info(简写i)命令查看已添加的断点,并执行delete(简写d)删除对应的断点。(stc-gdb) i b
Num Type Disp Enb Address What
1 breakpoint keep y <MULTIPLE>
breakpoint already hit 1 time
1.1 y 0x0140000c in hello() at hello_world.hc:12
1.2 n 0xc000000c in hello() at hello_world.hc:12
(stc-gdb) d 1
(stc-gdb) i b
No breakpoints or watchpoints. -
执行
quit(q)命令退出调试。(stc-gdb) q
A debugging session is active.
Inferior 1 [process 3295156] will be killed.
Quit anyway? (y or n) y
常见问题
在attach已有进程时,建议sudo或root权限启动stc-gdb,否则可能出现以下报错:
Attaching to process 448655
Could not attach to process. Try again as the root user or the sudoers.
ptrace: Operation not permitted.
代码示例
示例异构程序源文件hello_world.hc,代码如下:
/*
* This example uses NPURT API 'printf' to print device message in host
* terminal.
*/
#include <asm_macro.h>
#include <hpe.h>
#include <npurt.h>
#include <stdio.h>
__global__ void hello(void) {
while (1) {
printf("hello world from core %d/%d.n", CoreID, CoreNum);
}
}
#define NCORE 4
int main(void) {
printf("running hello_world......n");
hello<<<NCORE>>>();
stcDeviceSynchronize();
return 0;
}
编译获得含有调试信息的文件。在编译程序时添加-g选项,即可生成含有调试信息的⼆进制⽂件。
$ stcc --rtlib=compiler-rt hello_world.hc -g -o hello_world
使用stc-prof获取性能数据(核函数粒度)
命令说明
执行stc-prof --help获取stc-prof命令的使用方法:
$ stc-prof --help
OVERVIEW: function tracer for stream computing heterogeneous program
Usage: stc-prof [--version] [--help] [COMMAND [OPTION...] [program]]
COMMAND:
record Record target program performance data
OPTION:
--output-dir="dir" Specify output data dir, default is stc-prof.data
--multi-thread profiling multi-thread by thread group id
dump Output Chrome tracer file
OPTION:
--input-dir="dir" Specify input data dir, default is stc-prof.data
summary Output summary of target program performance data
OPTION:
--input-dir="dir" Specify input data dir, default is stc-prof.data
--target-pid="pid" Specify output process id
--target-tid="tid" Specify output thread id
detail Output detail of target program performance data. Multiple sub-module names separated by comma can be supported
OPTION:
--input-dir="dir" Specify input data dir, default is stc-prof.data
--sub-module="DEFAULT" Output detail of target program cycle and cache performance data
--sub-module="VME" Output detail of target program VME performance data
--sub-module="MTE" Output detail of target program MTE performance data
--sub-module="MME" Output detail of target program MME performance data
--sub-module="PAL" Output detail of target program parallel data
--sub-module="MCU" Output detail of target program MCU performance data
--sub-module="MEMORY" Output detail of target program Memory data
--sub-module="MEMORY-COL" Output detail of target program Memory collision data
SUB-OPTION:
--target-pid="pid" Specify output process id when --sub-module assigned
--target-tid="tid" Specify output thread id when --sub-module assigned
stc-prof支持以下命令:
| 命令 | 描述 |
|---|---|
record | 执行目标程序并采集性能数据,采集过程中不会额外打印信息,默认按tid进行采集。采集结果默认保存在stc-prof.data目录中,并最多保存两次执行的采集结果,最近一次的结果存放stc-prof.data目录中,上一次的存放在在stc-prof.data.old目录中。此外,也可用户自行使用参数指定结果保存路径。
|
dump | 基于stc-prof.data目录中的性能数据输出CTF文件,其中包括了HPE Runtime API、stream的信息。CTF(Chrome Tracer File)文件是一类文本文件,使用JSON格式保存,用于描述各类事件发生与结束的时间。您可以使用Chrome Tracer Viewer(chrome://tracing/)打开CTF文件,可视化查看程序执行时间轴。 默认读取stc-prof.data目录中的采集结果,若在采集数据时,自行指定了保存路径,需使用参数指定结果保存的路径。
|
summary | 基于stc-prof.data目录中的性能数据展示概要信息,包括HPE Runtime API调用耗时、核函数执行耗时、sysDMA使用情况、主机端设备端数据搬移情况。支持指定以下选项进行筛选:
|
detail | 基于stc-prof.data目录中的性能数据展示核函数执行过程中指定类型的详细执行信息,支持指定以下选项进行筛选:
|
使用流程
使用stc-prof的分析程序性能的流程如下:
-
通过
record命令采集执行的目标程序的性能数据。目前工具支持HC文件编译后的二进制文件和模型用例。性能数据默认保存在stc-prof.data文件目录中,也可使用--output-dir参数选项指定性能数据输出目录。-
以matrix-multiply的代码HC文件(代码请参考代码示例中matrix-multiply.hc文件)为例,先编译源文件,再通过
record命令采集执行程序的性能数据:$ stcc --rtlib=compiler-rt matrix-multiply.hc -o matrix-multiply
$ stc-prof record --output-dir=data-stc-prof ./matrix-multiply说明:性能数据输出目录路径长度不能大于225个字节,相对路径将展开成绝对路径计算长度。
-
采集模型性能数据,以用例入口为
test_deepfm.py中的test_deepfm接口为例:$ stc-prof record --output-dir=data-stc-prof python3 -m pytest -s test_deepfm.py说明:您可以请自行实现模型用例,或者联系技术支持提供协助。
-
-
通过相关命令展示性能数据。展示性能数据时,默认读取stc-prof.data目录下的性能数据,若在采集性能数据时,指定了存储目录,则需要使用
--input-dir参数选项指定输入目录。-
导出性能数据并转存成CTF文件。生成文件的名字可自定义,这里以perf_events.json为例:
$ stc-prof dump --input-dir=data-stc-prof > perf_events.json -
展示概要信息:
$ stc-prof summary --input-dir=data-stc-prof -
以展示VME指令的详细性能信息为例:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="VME"
-
命令示例
record
采集执行的目标程序的性能数据。以执行matrix-multiply采集性能数据为例:
$ stc-prof record ./matrix-multiply
matrix multiply result:0.0, 10.0, 20.0, 30.0,
$ cd stc-prof.data
$ ls
default.opts stc-addition-2047687.db stc-addition-pid.db
也可使用--output-dir参数选项指定性能数据输出目录。
$ stc-prof record --output-dir=data-stc-prof ./matrix-multiply
matrix multiply result:0.0, 10.0, 20.0, 30.0,
$ cd data-stc-prof
$ ls
default.opts stc-addition-29234.db stc-addition-pid.db
dump
导出性能数据并转存成CTF文件,文件可使用Chrome Tracer Viewer查看程序执行时间轴,示例如下:
-
导出性能数据并转存成CTF文件。
$ stc-prof dump > perf_events.json若在采集目标程序的性能数据时指定了输出性能数据输出目录,需在导出性能数据时设置性能数据输入目录。示例如下:
$ stc-prof dump --input-dir=data-stc-prof > perf_events.json -
打开Perfetto(https://ui.perfetto.dev),单击Open trace file然后选择perf_events.json即可。
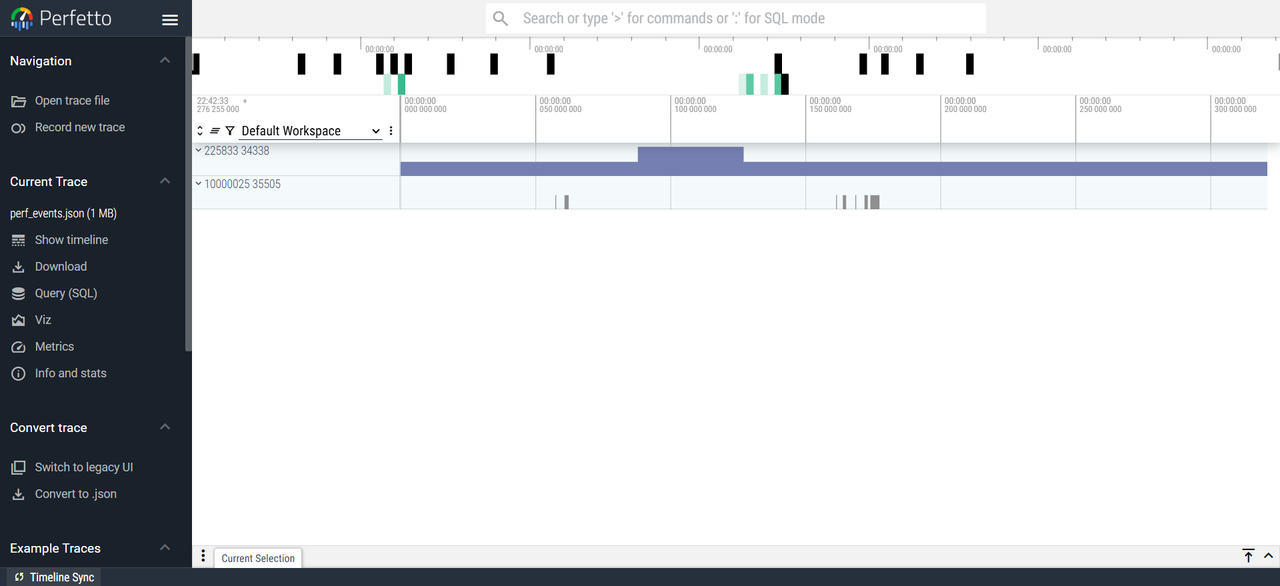
summary
展示摘要信息的示例如下:
说明:当内容大于屏幕的高度或者宽度时,可以通过方向键显示被折叠的内容。
$ stc-prof summary
pid:226044
|
--tid:226044
HPE Runtime API Info:
Pid Total Time Avg Time Total CPU Time Avg CPU Time Calls Function
====== ==================== ==================== ==================== ==================== ====== ================================
226044 2.695 us 2.695 us 2.583 us 2.583 us 1 stcDeviceSynchronize
226044 300.060 us 75.015 us 300.038 us 75.010 us 4 stcMalloc
226044 2.657 us 2.657 us 2.571 us 2.571 us 1 stcMallocHigh
226044 4.284 us 1.428 us 4.208 us 1.403 us 3 stcFree
226044 107.231 us 35.744 us 42.850 us 14.283 us 3 stcMemcpy
226044 2.754 us 2.754 us 2.675 us 2.675 us 1 stcConfigureCall
226044 16601.934 us 16601.934 us 723.381 us 723.381 us 1 stcLaunchKernel
226044 14274.015 us 14274.015 us 653.996 us 653.996 us 1 stcModuleLoadData
226044 25.512 us 25.512 us 25.431 us 25.431 us 1 stcRegisterFatBinary
226044 0.808 us 0.808 us 0.696 us 0.696 us 1 stcUnregisterFatBinary
226044 4.114 us 4.114 us 3.585 us 3.585 us 1 stcRuntimeGetVersion
------ -------------------- -------------------- -------------------- -------------------- ------ --------------------------------
Kernel Functions:
Kernel-Function Duration MCU MTE MME VME-CU VME-VEC TID
======================================== ================ ======== ======== ======== ======== ======== ========
matmul_kernel (8) 294.456 us 90582 65 28 11 0 226044
---------------------------------------- ---------------- -------- -------- -------- -------- -------- --------
Kernel Functions Memory(SysDMA):
Kernel-Function DMA-ID C0 (DDR -> LLB) C1 (LLB -> DDR) TID
======================================== ======== ========================= ========================= ========
matmul_kernel sysdma_0 0 B ( 0.0000 GB/s) 0 B ( 0.0000 GB/s) 226044
matmul_kernel sysdma_1 0 B ( 0.0000 GB/s) 16 B ( 0.2388 GB/s) 226044
---------------------------------------- -------- ------------------------- ------------------------- --------
DEVICE_TO_HOST size: 16 B speed: 0.0011 GB/s
HOST_TO_DEVICE size: 29.14 KB speed: 0.2947 GB/s
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需在展示摘要信息时设置性能数据输入目录。示例如下:
$ stc-prof summary --input-dir=data-stc-prof
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| pid | 执行程序所在的进程ID。 |
| tid | 执行程序所在的线程ID。 |
| HPE Runtime API Info | HPE Runtime API调用耗时,包括以下项目:
|
| Kernel Functions | 在NPC执行核函数的性能数据信息:
|
| Kernel Functions Memory | sysDMA使用情况,包括以下项目:
|
| DEVICE_TO_HOST | 设备端向主机端搬运的数据量和带宽。 |
| HOST_TO_DEVICE | 主机端向设备端搬运的数据量和带宽。 |
detail
DEFAULT
输出多个模块汇总性能信息的示例如下:
$ stc-prof detail --sub-module="DEFAULT"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
NPC-CORE MCU-CYCLE MTE MME VME-CU VME-VEC DCACHE MISS ICACHE MISS
========== ============ ======== ======== ======== ======== ============ ============
NPC_00 59996 84 24 11 0 31 169
NPC_01 24434 84 24 11 0 8 87
NPC_02 24034 68 24 11 0 8 87
NPC_03 24034 68 24 11 0 8 87
---------- ------------ -------- -------- -------- -------- ------------ ------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="DEFAULT"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| MCU-CYCLE | MCU指令耗费的cycle数。 |
| MTE | MTE指令耗费的cycle数。 |
| MME | MME指令耗费的cycle数。 |
| VME-CU | 自定义向量运算指令耗费的cycle数。 |
| VME-VEC | RISC-V原生向量运算指令耗费的cycle数。 |
| DCACHE-MISS | DCACHE MISS计数。 |
| ICACHE-MISS | ICACHE MISS计数。 |
VME
输出VME指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="VME"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
NPC-CORE VME-CU VME-CU INST VME-VEC VME-VEC INST VME VME-MME VME-MTE VME-MME-MTE
========== ======== ============= ======== ============= ======================================
NPC_00 11 1 0 0 9.2% 0.0% 0.0% 0.0%
NPC_01 11 1 0 0 9.2% 0.0% 0.0% 0.0%
NPC_02 11 1 0 0 10.7% 0.0% 0.0% 0.0%
NPC_03 11 1 0 0 10.7% 0.0% 0.0% 0.0%
---------- -------- ------------- -------- ------------- --------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="VME"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| VME-CU | 自定义向量运算指令耗费的cycle数。 |
| VME-CU INST | 自定义向量运算指令的数量。 |
| VME-VEC | RISC-V原生向量运算指令耗费的cycle数。 |
| VME-VEC INST | RISC-V原生向量运算指令的数量。 |
| VME | 执行VME指令占wall-clock time的百分比。 |
| VME-MME | 并行执行VME、MME指令的并行度,即占wall-clock time的百分比。 |
| VME-MTE | 并行执行VME、MTE指令的并行度,即占wall-clock time的百分比。 |
| VME-MME-MTE | 并行执行VME、MME、MTE指令的并行度,即占wall-clock time的百分比。 |
MTE
输出MTE指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="MTE"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
NPC-CORE MTE MTE INST MTE MTE-MME MTE-VME MTE-MME-VME
========== ======== ========== ======================================
NPC_00 84 1 70.6% 0.0% 0.0% 0.0%
NPC_01 84 1 70.6% 0.0% 0.0% 0.0%
NPC_02 68 1 66.0% 0.0% 0.0% 0.0%
NPC_03 68 1 66.0% 0.0% 0.0% 0.0%
---------- -------- ---------- --------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MTE"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| MTE | MTE指令耗费的cycle数。 |
| MTE INST | MTE指令的数量。 |
| MTE | 执行MTE指令占wall-clock time的百分比。 |
| MTE-MME | 并行执行MTE、MME指令的并行度,即占wall-clock time的百分比。 |
| MTE-VME | 并行执行MTE、VME指令的并行度,即占wall-clock time的百分比。 |
| MTE-MME-VME | 并行执行MTE、MME、VME指令的并行度,即占wall-clock time的百分比。 |
MME
输出MME指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="MME"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
NPC-CORE MME MME INST MME MME-VME MME-MTE MME-VME-MTE
========== ======== ========== ======================================
NPC_00 24 1 20.2% 0.0% 0.0% 0.0%
NPC_01 24 1 20.2% 0.0% 0.0% 0.0%
NPC_02 24 1 23.3% 0.0% 0.0% 0.0%
NPC_03 24 1 23.3% 0.0% 0.0% 0.0%
---------- -------- ---------- --------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MME"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| MME | 自定义MME指令的cycle数。 |
| MME INST | 自定义MME指令的数量。 |
| MME | 执行MME指令占wall-clock time的百分比。 |
| MME-VME | 并行执行MME、VME指令的并行度,即占wall-clock time的百分比。 |
| MME-MTE | 并行执行MME、MTE指令的并行度,即占wall-clock time的百分比。 |
| MME-VME-MTE | 并行执行MME、VME、MTE指令的并行度,即占wall-clock time的百分比。 |
PAL
输出并行度相关性能信息的示例如下:
$ stc-prof detail --sub-module="PAL"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
NPC-CORE PAL(ALL) PAL(MTE/MME) PAL(MTE/VME) PAL(VME/MME)
========== ================ ================ ================ ================
NPC_00 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_01 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_02 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
NPC_03 0(0.000%) 0(0.000%) 0(0.000%) 0(0.000%)
---------- ---------------- ---------------- ---------------- ----------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="PAL"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| PAL(ALL) | 并行执行MTE、MME、VME指令的并行度,即占wall-clock time的百分比。 |
| PAL(MTE/MME) | 并行执行MTE、MME指令的并行度,即占wall-clock time的百分比。 |
| PAL(MTE/VME) | 并行执行MTE、VME指令的并行度,即占wall-clock time的百分比。 |
| PAL(VME/MME) | 并行执行VME、MME指令的并行度,即占wall-clock time的百分比。 |
MCU
输出MCU指令相关性能信息的示例如下:
$ stc-prof detail --sub-module="MCU"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
NPC-CORE MCU INST MCU CYCLE DCACHE MISS ICACHE MISS
========== ============ ============ ============ ============
NPC_00 2511 59996 31 169
NPC_01 1074 24434 8 87
NPC_02 1074 24034 8 87
NPC_03 1074 24034 8 87
---------- ------------ ------------ ------------ ------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MCU"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| MCU INST | MCU指令的数量。 |
| MCU CYCLE | MCU指令耗费的cycle数。 |
| DCACHE MISS | DCACHE MISS计数。 |
| ICACHE MISS | ICACHE MISS计数。 |
说明:指定MCU可能比指定DEFAULT统计出的MCU CYCLE数量偏大。由于指定MCU时统计对象为non-stopable的第三方寄存器,而指定DEFAULT时会在核函数执行结束后立即停止计数。
MEMORY
输出DDR/LLB/L1相关性能信息的示例如下:
$ stc-prof detail --sub-module="MEMORY"
matmul_kernel: (cluster_0 tid:2047687) duration: 332.722 us
SYSDMA-ID C0 (DDR -> LLB) C1 (LLB -> DDR)
======================================================================================================
sysdma_0 0 B (0.000 GB/s) 0 B (0.000 GB/s)
sysdma_1 0 B (0.000 GB/s) 8 B (0.119 GB/s)
******************************************************************************************************
NPC-CORE ICMOV PLD L1 -> LLB LLB -> L1
======================================================================================================
NPC_00 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.025 GB/s) 0 B (0 GB/s)
NPC_01 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.025 GB/s) 0 B (0 GB/s)
NPC_02 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.031 GB/s) 0 B (0 GB/s)
NPC_03 0 B (0 GB/s) 0 B (0 GB/s) 2 B (0.031 GB/s) 0 B (0 GB/s)
------------------------------------------------------------------------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MEMORY"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| SYSDMA-ID | 核函数使用的DMA控制器的ID。 |
| C0 (DDR -> LLB) | DMA控制器Channel 0,执行程序时从DDR向LLB搬运的数据量和带宽。 |
| C1 (LLB -> DDR) | DMA控制器Channel 1,执行程序时从LLB向DDR搬运的数据量和带宽。 |
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| ICMOV | MTE icmov指令相关的数据量与带宽。 |
| PLD | MTE pld指令相关的数据量与带宽。 |
| L1 -> LLB | MTE mov.llb.l1指令相关的数据量与带宽。 |
| LLB -> L1 | MTE mov.l1.llb指令相关的数据量与带宽。 |
MEMORY-COL
输出DDR/LLB/L1冲突相关信息的示例如下:
$ stc-prof detail --sub-module="MEMORY-COL"
matmul_kernel: (cluster_0,tid:2047687) duration: 332.722 us
SYSDMA-ID LLB COLLISION
======================================================================================================
sysdma_0 0
sysdma_1 0
******************************************************************************************************
NPC-CORE L1 COLLISION TYPE L1 COLLISION VAL IM COLLISION TYPE IM COLLISION VAL
======================================================================================================
NPC_00 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_01 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_02 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
NPC_03 L1_COLS_TO_MEM 0 IM_COLS_TO_MEM 0
------------------------------------------------------------------------------------------------------
若在采集目标程序的性能数据时指定了输出性能数据输出目录,需设置性能数据输入目录。示例如下:
$ stc-prof detail --input-dir=data-stc-prof --sub-module="MEMORY-COL"
各列输出信息描述如下:
| 项目 | 描述 |
|---|---|
| SYSDMA-ID | 核函数使用的DMA控制器的ID。 |
| LLB COLLISION | 在同一时刻访问了LLB上的同一块内存,记录产生冲突的次数。 |
| NPC-CORE | 核函数使用的NPC Core的ID。 |
| L1 COLLISION TYPE | 在同一时刻访问了L1上的同一块内存,产生冲突,类型标记为L1_COLS_TO_MEM。 |
| L1 COLLISION VAL | 访问L1时产生冲突的次数。 |
| IM COLLISION TYPE | 在同一时刻访问了IM(Intermediate Buffer)上的同一块内存,产生冲突,类型标记为IM_COLS_TO_MEM。 |
| IM COLLISION VAL | 访问IM时产生冲突的次数。 |
代码示例
示例异构程序源文件matrix-multiply.hc,代码如下:
/*
* This example uses internal instructions to do matrix multiply.
*/
#include <asm_macro.h>
#include <hpe.h>
#include <npurt.h>
#include <stdio.h>
// number of left matrix's col and right matrix's row
#define LCOL_RROW 4
// local_left * local_right = local_out
__device__ void matmul(__fp16 *local_out, __fp16 *local_left,
__fp16 *local_right) {
int shape1, shape2;
// do matrix multiply and result must be stored in IM buffer
shape1 = DEFINE_SHAPE(LCOL_RROW, 1);
shape2 = DEFINE_SHAPE(1, LCOL_RROW);
CONFIG_VE_BC_CSR(shape1, shape2, 0, 0);
memul_mm((__fp16 *)IM_BUFFER_START, local_left, local_right);
// move result from IM buffer to local memory
shape1 = DEFINE_SHAPE(1, 1);
shape2 = 0;
CONFIG_VE_CSR(shape1, shape2, 0, 0);
mov_m(local_out, (__fp16 *)IM_BUFFER_START);
}
__global__ void matmul_kernel(__fp16 *global_out, __fp16 *global_left,
__fp16 *global_right) {
__local__ __fp16 local_left[LCOL_RROW];
__local__ __fp16 local_right[LCOL_RROW];
__local__ __fp16 local_out;
__shared__ __fp16 share_out[CoreNum];
// copy right matrix to each core
memcpy(local_right, global_right, LCOL_RROW * sizeof(__fp16));
// copy a row of left matrix for each core
memcpy(local_left, global_left + CoreID * LCOL_RROW,
LCOL_RROW * sizeof(__fp16));
// matrix multiply
matmul(&local_out, local_left, local_right);
// copy result in local memory of each core to shared memory
memcpy(share_out + CoreID, &local_out, sizeof(__fp16));
// sync to wait each of the core compute share_out data filled
sync();
if (CoreID == 0) {
// copy result in share memory of each core to global memory
memcpy(global_out, share_out, CoreNum * sizeof(__fp16));
}
}
#define NCORE 8
int main(void) {
__fp16 *dev_left, *dev_right, *dev_out;
// left matrix data for 4 cores
__fp16 host_left[4 * LCOL_RROW] = {
0.0, 0.0, 0.0, 0.0, // row1
1.0, 1.0, 1.0, 1.0, // row2
2.0, 2.0, 2.0, 2.0, // row3
3.0, 3.0, 3.0, 3.0, // row4
};
// right matrix data
__fp16 host_right[LCOL_RROW] = {1.0, 2.0, 3.0, 4.0};
// copy left matrix to device
int mat_size_left = NCORE * LCOL_RROW * sizeof(__fp16);
stcMalloc((void **)&dev_left, mat_size_left);
stcMemcpy(dev_left, host_left, mat_size_left, stcMemcpyHostToDevice);
// copy right matrix to device
int mat_size_right = LCOL_RROW * sizeof(__fp16);
stcMalloc((void **)&dev_right, mat_size_right);
stcMemcpy(dev_right, host_right, mat_size_right, stcMemcpyHostToDevice);
// allocate result buffer in device
int mat_size_out = NCORE * sizeof(__fp16);
__fp16 host_out[NCORE];
stcMalloc((void **)&dev_out, mat_size_out);
matmul_kernel<<<NCORE>>>(dev_out, dev_left, dev_right);
stcDeviceSynchronize();
// copy result from device to host
stcMemcpy(host_out, dev_out, mat_size_out, stcMemcpyDeviceToHost);
printf("matrix multiply result:");
for (int i = 0; i < NCORE; i++)
printf("%.1f, ", (float)(host_out[i]));
printf("n");
stcFree(dev_left);
stcFree(dev_right);
stcFree(dev_out);
return 0;
}
使用stc-vprof可视化查看性能数据
stc-vprof是可视化性能分析工具,可用于加载本地或远程服务器的目标程序获取性能分析结果,查看程序各阶段的耗时以及包含的指令等,并支持查看多个阶段的汇总数据、核函数数据等信息。此外,工具还支持hc文件代码编辑、管理性能分析资源、多语言切换等功能。
前提条件
stc-vprof的可视化依赖JDK,请确保安装JDK 11或以上版本。
启动stc-vprof
-
登录服务器,stc-vprof支持显示图形界面,可使用远程连接的方式登录,例如可通过MobaXterm登录。
-
前往stc-vprof可执行文件所在的目录。
$ cd /usr/local/hpe/bin -
启动stc-vprof。
$ stc-vprof
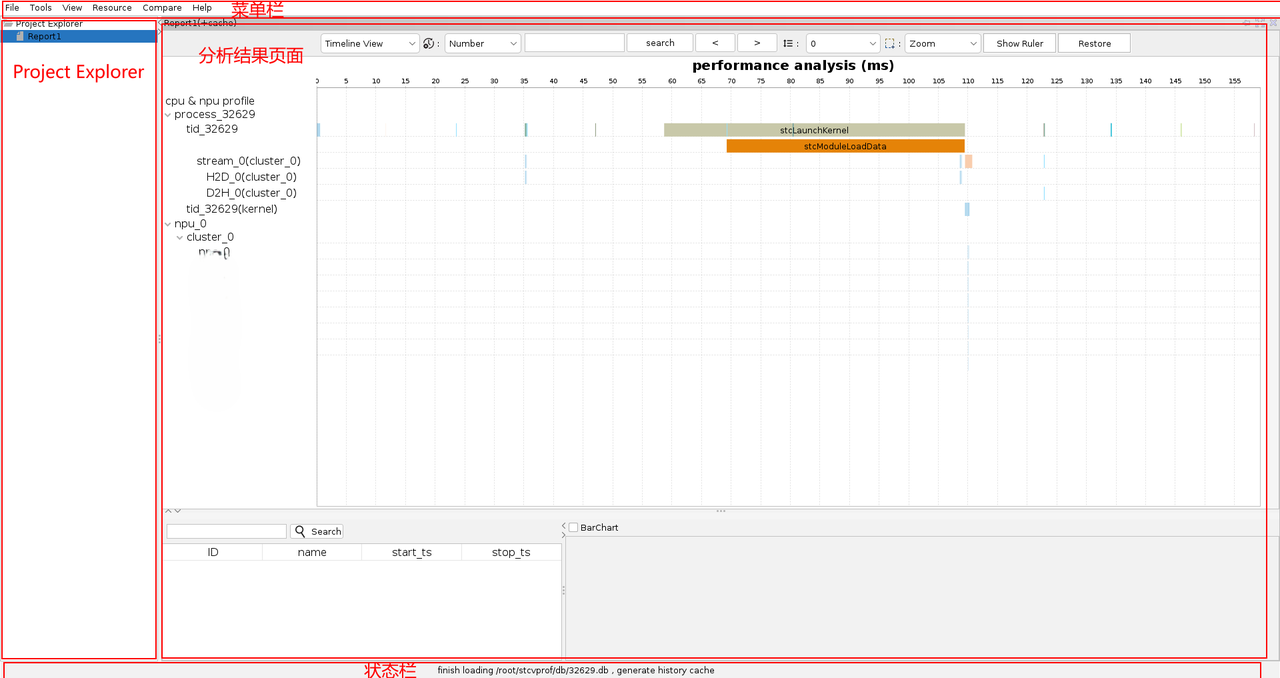
stc-vprof工具用户界面主要分为四部分:菜单栏、Project Explorer、分析结果页面和状态栏。
管理项目和分析结果
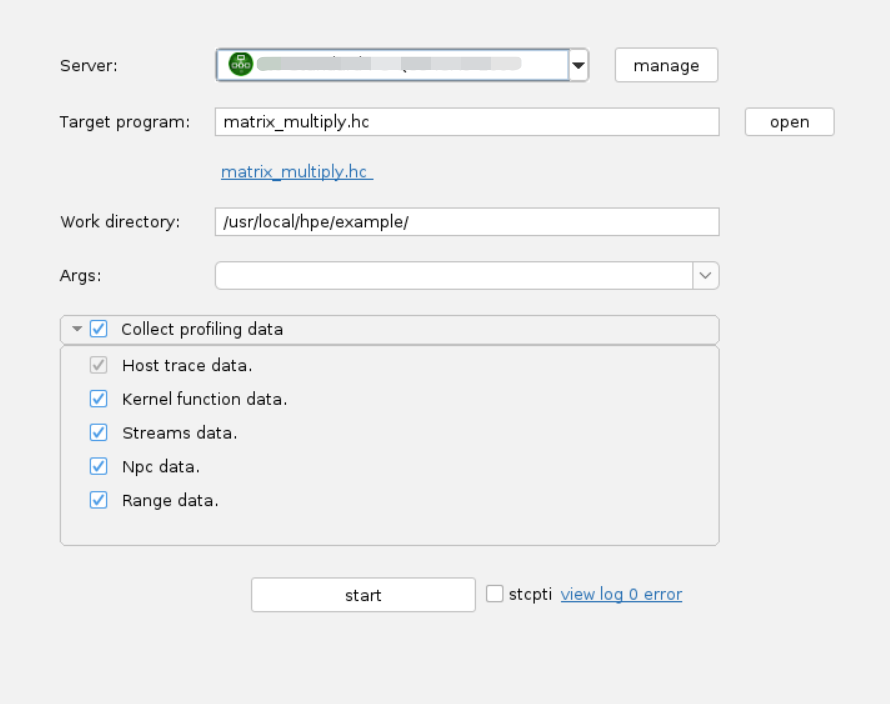
新建项目并采集数据
-
菜单栏选择File > New Project,或左侧Project Explorer空白处右击并选择New Project。
-
选择新建本地项目还是远程项目。
-
若单击Local Project新建本地项目。
-
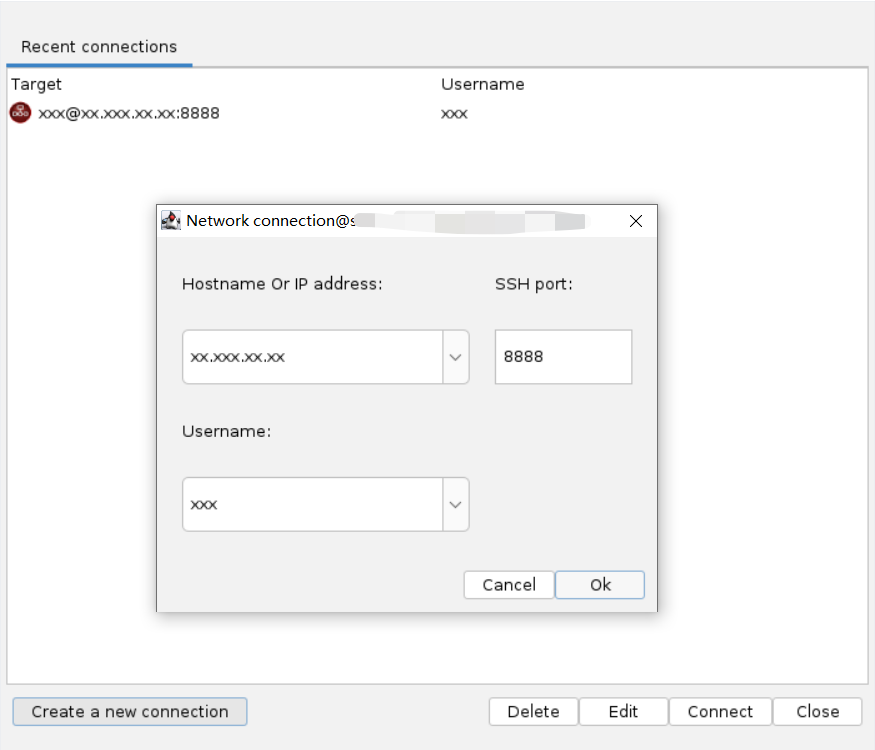
若单击Remote Project新建远程项目,在Server下拉框选择远程服务器。选择SSH connections下的已添加的远程服务器,单击右侧Connect连接服务器,输入密码完成验证,图标变为绿色表示连接成功。此外,单击右侧Manage管理最近连接的远程服务器。在弹窗内,可对远程服务器连接进行新建、删除、编辑、连接服务器等操作。单击Create a new connection,填入远程服务器的hostname或ip地址、端口和用户名,新建新连接。
-
-
单击open,选择目标程序。目前工具支持c、cpp、hc文件、hc编译后的二进制elf文件。

说明:若选择的目标程序为c、c++、hc文件时,单击下方出现的目标程序链接,将弹出一个代码编辑器。详细介绍可参考更多功能中的代码编辑器章节。
-
根据需求在Args右侧选择执行程序的参数。
-
根据需求在Model右侧填入模型参数。
-
根据需求在Collect profiling data下拉菜单选择分析结果页面展示的数据类型。
说明:其中可选择Host trace data(默认必选项,trace数据)、Kernel function data(核函数数据)、Streams data(流数据)、Npc data(npc数据)、Range data(自定义埋点)。
-
单击start,执行目标程序,采集并显示性能分析结果。采集时,项目文件、分析结果、日志文件都会存到本地。状态栏中显示文件路径及是否使用缓存的提示语。
-
单击view log,查看运行日志和报错。
打开项目或分析结果
左侧Project Explorer面板中选中最近打开的文件项目(Project)或分析结果(Report),右键并单击Open,再次打开项目或分析结果。

删除项目或分析结果
左侧Project Explorer面板中选中一个或多个最近打开的文件项目(Project)或分析结果(Report),右键并单击Remove,删除项目或分析结果。
-
标签栏中选中项目(Project)或分析结果(Report),单击关闭按钮。
-
菜单栏单击File > Close 编辑器当前页面名。
-
标签页中右键单击项目(Project)或分析结果(Report):
-
单击Close,可关闭当前项目(Project)或分析结果(Report)。
-
单击Close All Tabs,可关闭所有打开的项目(Project)或分析结果(Report)。
-
单击Close Other Tabs,只保留右键对应页面,其他的项目(Project)或分析结果(Report)关闭。
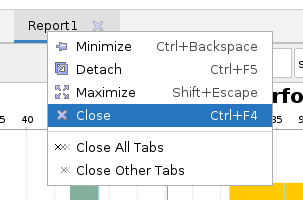
-
导入项目或分析结果
导入项目或分析结果时:
-
菜单栏单击File > Import Report。选择需要导入的一个或多个文件。
-
菜单栏单击File > Import Recent。选择最近导入过的文件。
说明:目前只记录通过Import Report导入的资源文件路径,最多记录5条,且记录顺序按导入时间从近到远进行排序。
-
菜单栏单击File > Download & Import Remote Report。下载导入远程服务器上的文件。在弹出对话框中填写远程服务器地址、用户名和密码后,单击open连接远程服务器。连接成功后,选择需要导入的一个或多个文件。
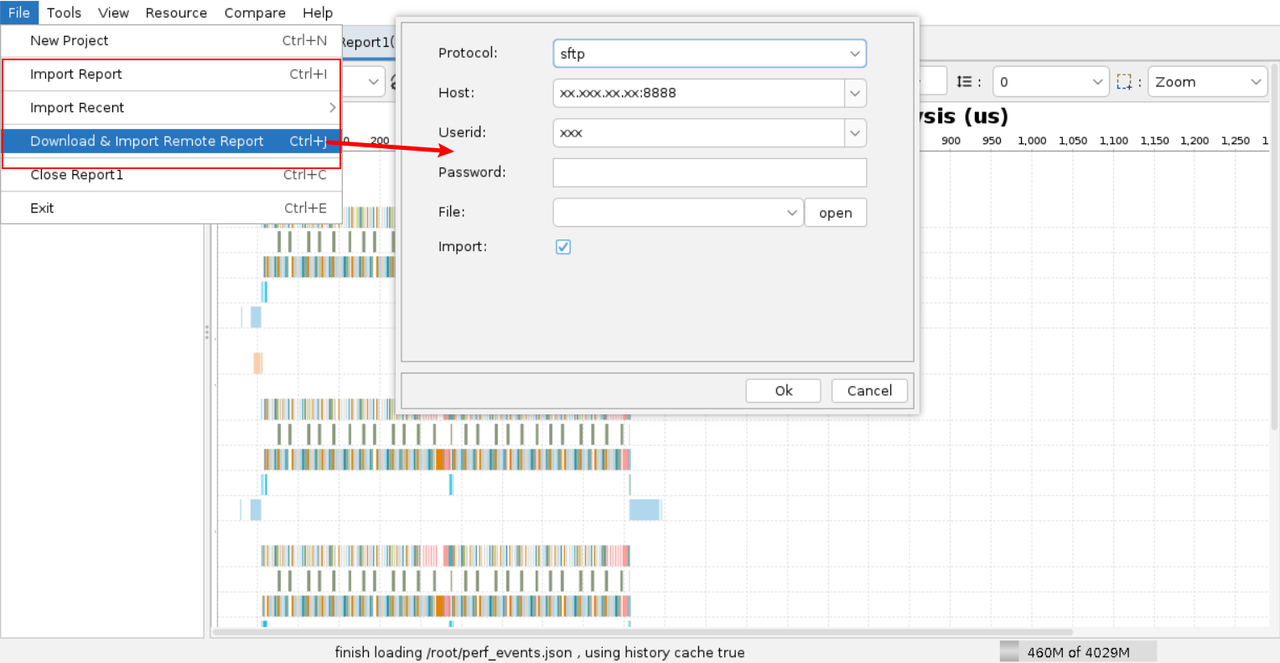
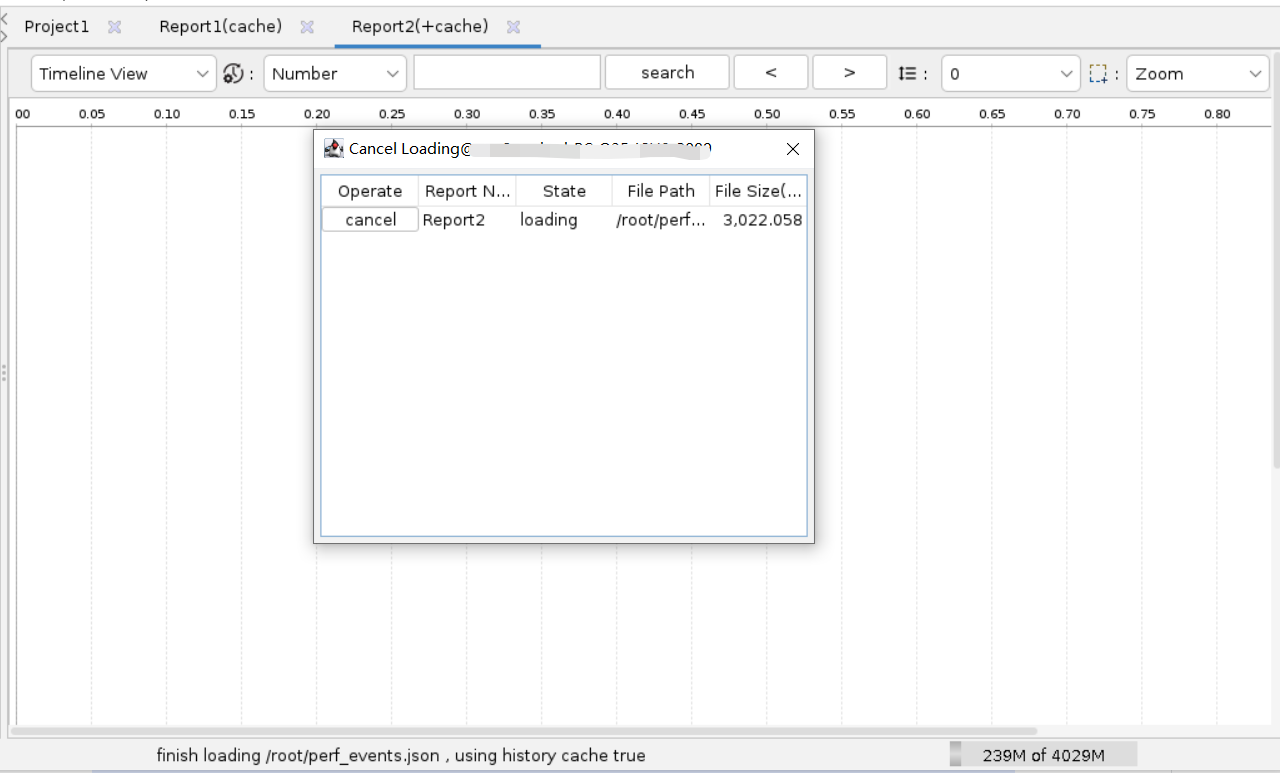
导入过程中,单击cancel,可中断导入进程,结果页面将会显示已加载的内容。
管理性能分析资源
性能分析资源的包括数据库文件(DB)、日志文件(Logs)、缓存文件(Cache)、项目文件(Project)和Json文件。单击Resource > 对应类型的性能分析资源,可对相应类型的资源进行导入和删除操作。此外,缓存文件(Cache)还支持合并操作。
说明: 日志文件(Logs)不支持导入操作。
工具还支持管理远程服务器上的相关性能分析资源。单击Resource > Remote,连接远程服务后,对相应类型的资源的操作与本地性能分析资源步骤类似。
导入性能分析资源
下面以数据库文件(DB)为例,介绍导入操作。
-
菜单栏单击Resource > DB,显示本地所有的DB文件。
-
选中需要导入的DB文件。您还可以进行以下的操作:
-
上方文本框输入字符,显示匹配到关键字的资源名称。
-
右侧查看DB文件的总数量和已选DB文件的数量。
-
右侧选中Only Show Selected,仅显示已选中的DB文件。
-
右侧单击Selected All快速全选,或单击UnSelected All取消全选。
-
-
单击import,导入选中的文件。
-
导入成功后,状态栏中显示文件路径及是否使用缓存的提示语。
说明:仅支持导入系统内部生成的文件,一般为显示
/<user_dir>/stcvprof/文件夹下对应的类型的文件。
清理性能分析资源
下面以数据库文件(DB)为例,介绍删除操作。
-
菜单栏单击Resource > DB,显示本地所有的DB文件。
-
选中需要删除的DB文件。您还可以进行以下的操作:
-
上方文本框输入字符,显示匹配到关键字的资源名称。
-
右侧查看DB文件的总数量和已选DB文件的数量。
-
右侧选中Only Show Selected,仅显示已选中的DB文件。
-
-
单击delete,删除选中的文件。
说明:仅支持导入系统内部生成的文件,一般为显示
/<user_dir>/stcvprof/文件夹下对应的类型的文件。
开启缓存配置
针对文件较大的情况,可通过配置项选择开启缓存机制,当再次打开文件时,可自行选择是否从历史缓存中获取。
-
配置项页面中的General CFG中选中cache,并设置缓存开启阈值。阈值默认值为500MB。启动配置文件中设置为BUFFER_THRESHOLD=500。
-
文件导入加载时,触发缓存机制后生成缓存,并在标签页上文件名后增加
+cache标识。
说明:若导入的文件为json文件或log文件,可在弹出的对话框内自行选择数据的起止时间以及是否从缓存中加载。
选中is from history cache,工具从缓存中加载对应的结果文件导入,在标签页上文件名后会增加
cache标识。不选中is from history cache,工具直接加载文件,同时生成缓存。在标签页上文件名后增加
+cache标识。
合并缓存文件
工具提供合并两个相同类型(log文件、json文件)的缓存文件的功能。
-
菜单栏单击Resource > Caches,显示本地所有的缓存文件。
-
选中两个相同类型文件。
-
单击merge按钮,合并两个缓存文件。合并成功后,状态栏中显示文件合并完成。
说明:合并后的新文件是以第一个目录名称+“&”+第二个目录名称来命名的,例如:perf-1.log&perf-2.log。
查看性能分析结果
分析结果页面简述
性能分析结果页面中包含了工具栏、设备列表、时间轴图表、属性列表,如下所示:
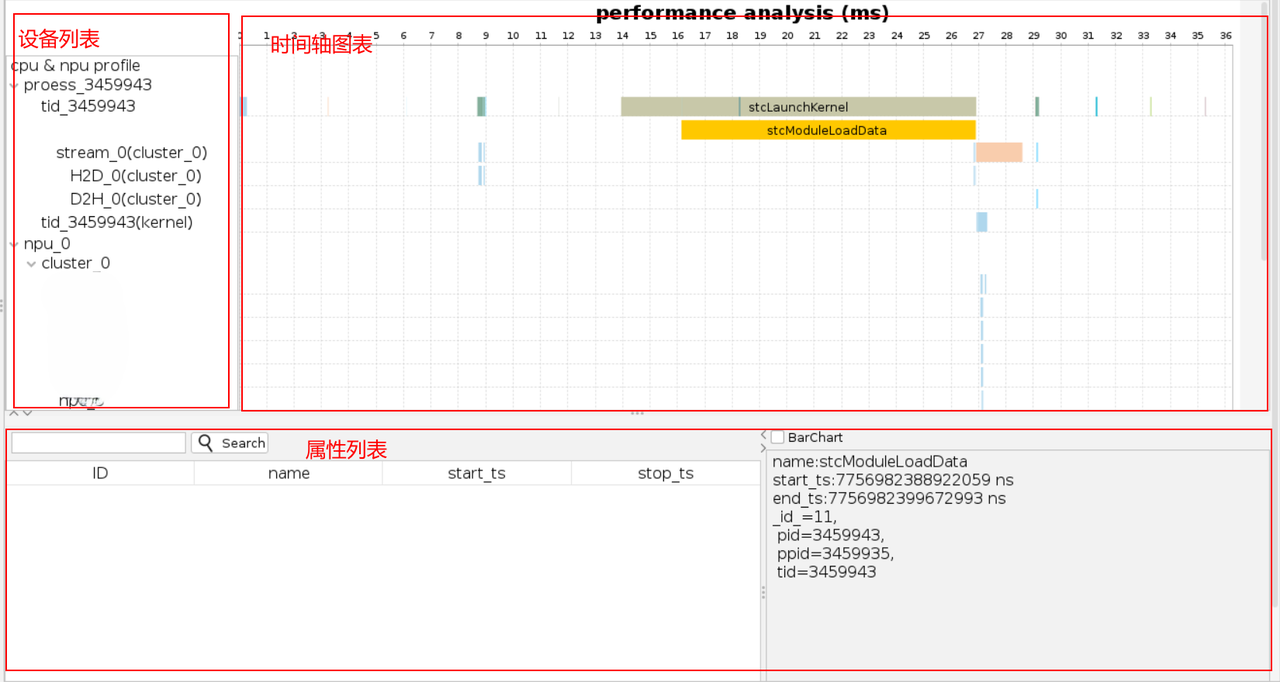
以查看tid_3459943(kernel)为例:
-
在设备列表区域,选择cpu&npu profile > proess_3459943 > tid_3459943(kernel)。
-
在时间轴图表区域,自动同步以浅蓝色高亮显示tid_3459943(kernel)的时间轴,方便查看各阶段的耗时。支持高亮显示已选中的阶段、放大缩小时间轴范围等操作,以便更直观清晰地查看相关信息。以选中其中一个matmul操作为例:
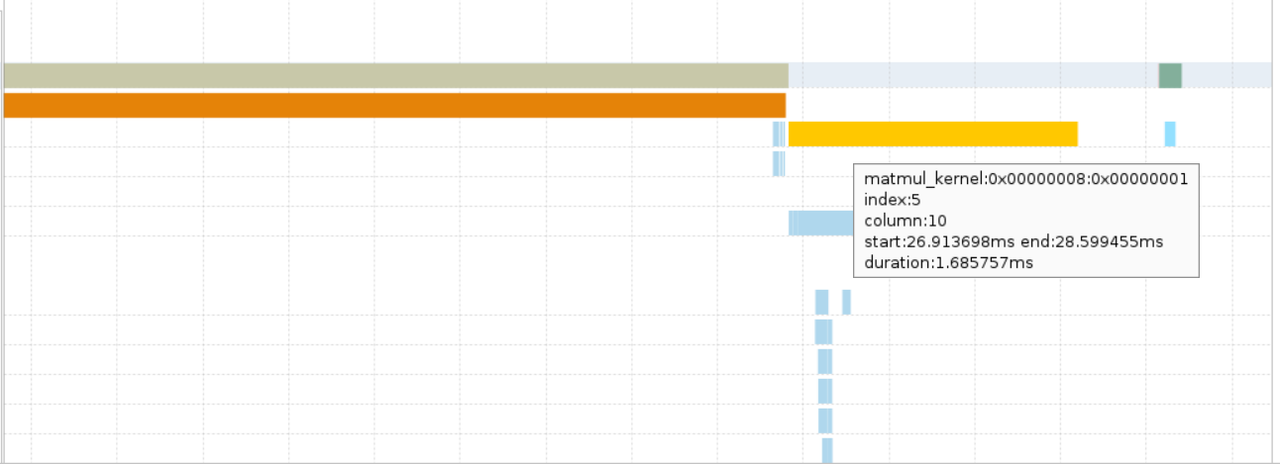
- 属性列表区域,自动同步显示已选中操作的各项属性,包括起始时间、结束时间、资源、指令等。
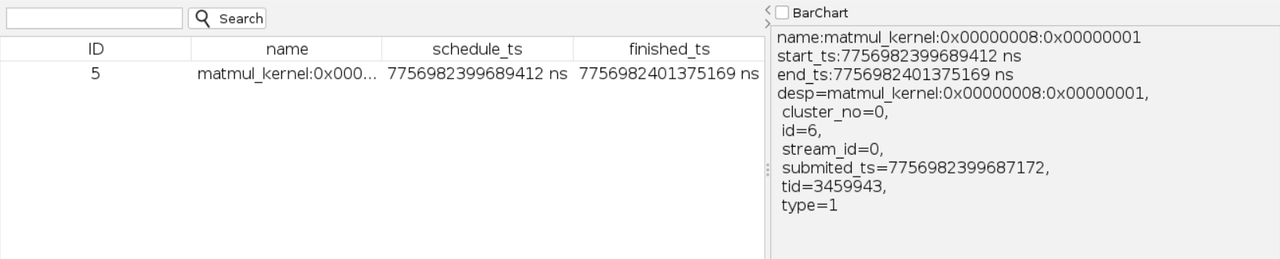
- 单击tid_3459943(kernel) 父节点proess_3459943,则收起其包含的节点,时间轴图表自动同步以浅蓝色高亮显示proess_3459943的时间轴。
调整分析结果页面尺寸
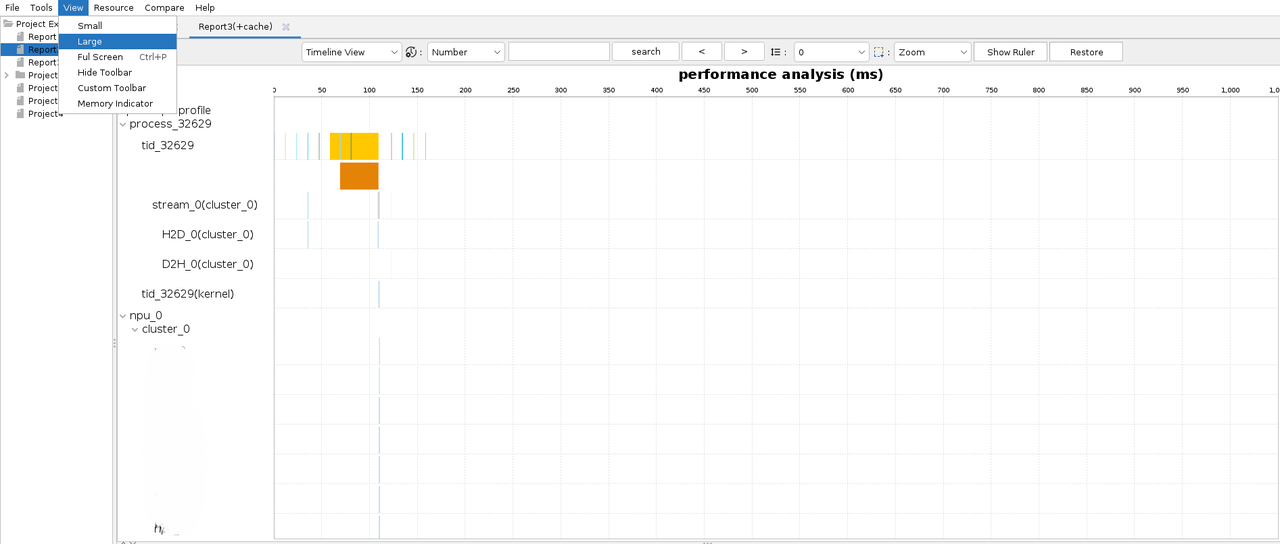
菜单栏中,选择View > Small或View > Large可以调整分析结果页面尺寸:
-
Small视图:左侧设备列表及右侧时间轴图表的高度为24像素。
-
Large视图:左侧设备列表及右侧时间轴图表的高度为44像素。
说明:分析结果页面的尺寸默认为Small视图。
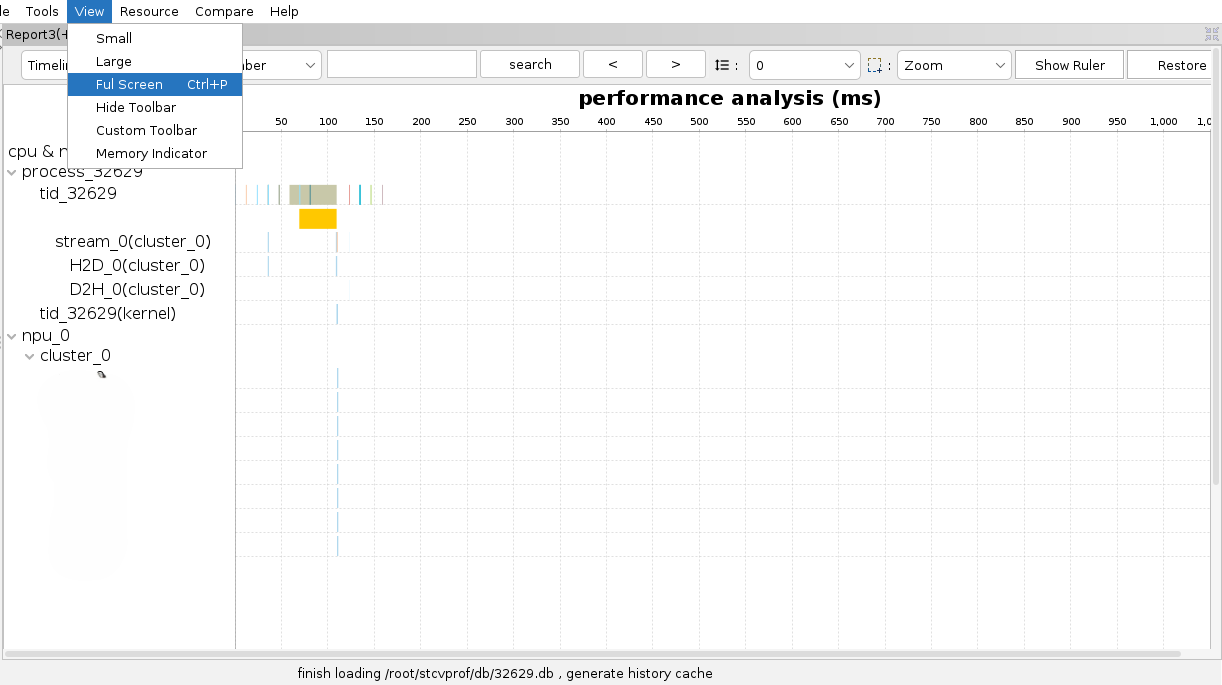
全屏模式
菜单栏中选择View > Full Screen进入全屏模式,全屏模式下收起左侧的Project Explorer面板并且仅保留当前的标签页,分析结果显示的区域更大。再单击页面右上角的缩小按钮即可返回常规模式。
设备列表
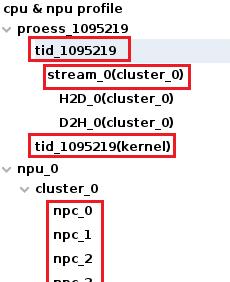
设备列表中列出了运行程序时的进程和设备信息。您可以选择节点,然后在时间轴图表、属性列表中查看相应的分析结果。
以下图为例,设备列表所包含节点的含义为:
-
tid_1095219:主机端Host CPU Trace。
-
stream_0(cluster_0):执行核函数时所在的流。
-
tid_1095219(kernel):核函数。
-
npc_x:在设备端使用的NPC。
时间轴图表
时间轴图表中显示了运行程序时各阶段的耗时等信息。您可以选择图形bar查看详细信息,同时支持放缩图形bar、多选、查看核函数并行度等操作。选择图形后会以橘黄色高亮显示该阶段,并在属性列表中显示其属性信息。
缩放条形图
工具支持针对单个条形图和多个条形图进行操作,缩放条形图后可以拖动下方滚动条查看各时间范围内的条形图。
-
针对单个条形图,将鼠标悬浮在待放缩的图形上,滚轮上滚放大图形,滚轮下滚缩小图形,时间轴会同步按比例放缩。
-
针对多个条形图,拖动鼠标框选多个条形图即可同时放大范围内的条形图。
此外,工具还支持键盘快捷键进行缩放。英文输入模式下,按压键盘A时间轴往左滑动,按压键盘D时间轴往右滑动,按压键盘W时间轴放大,按压键盘S时间轴缩小。
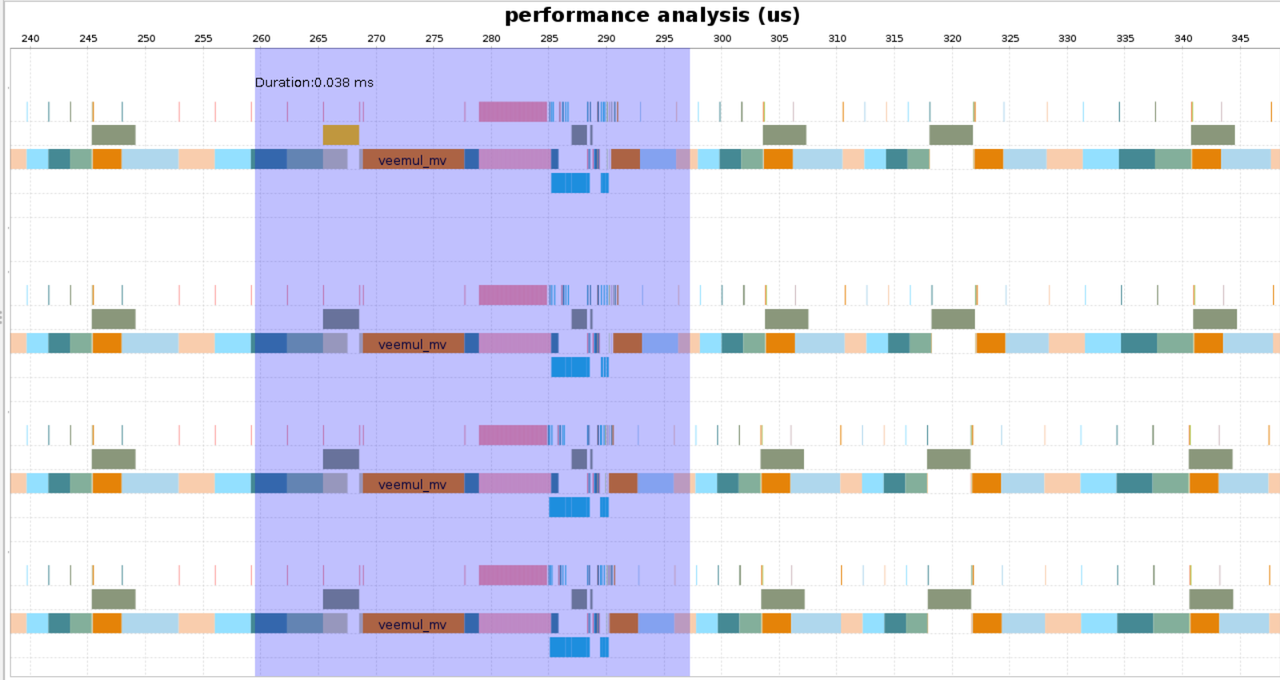
查看核函数并行度
工具支持查看核函数的并行度,核函数并行有利于加快处理效率。
-
图表里,右击选中核函数线程所在行。
-
单击NPC PAL,查看并行度柱形图。柱形图中列出了每个NPC上计算的并行度,并支持切换以下模式:
-
PAL(ALL):并行执行MTE、MME、VME指令的并行度,即wall-clock time的占百分比。
-
PAL(MTE/MME):并行执行MTE、MME指令的并行度,即wall-clock time的占百分比。
-
PAL(MTE/VME):并行执行MTE、VME指令的并行度,即wall-clock time的占百分比。
-
PAL(VME/MME):并行执行MME、VME指令的并行度,即wall-clock time的占百分比。
-
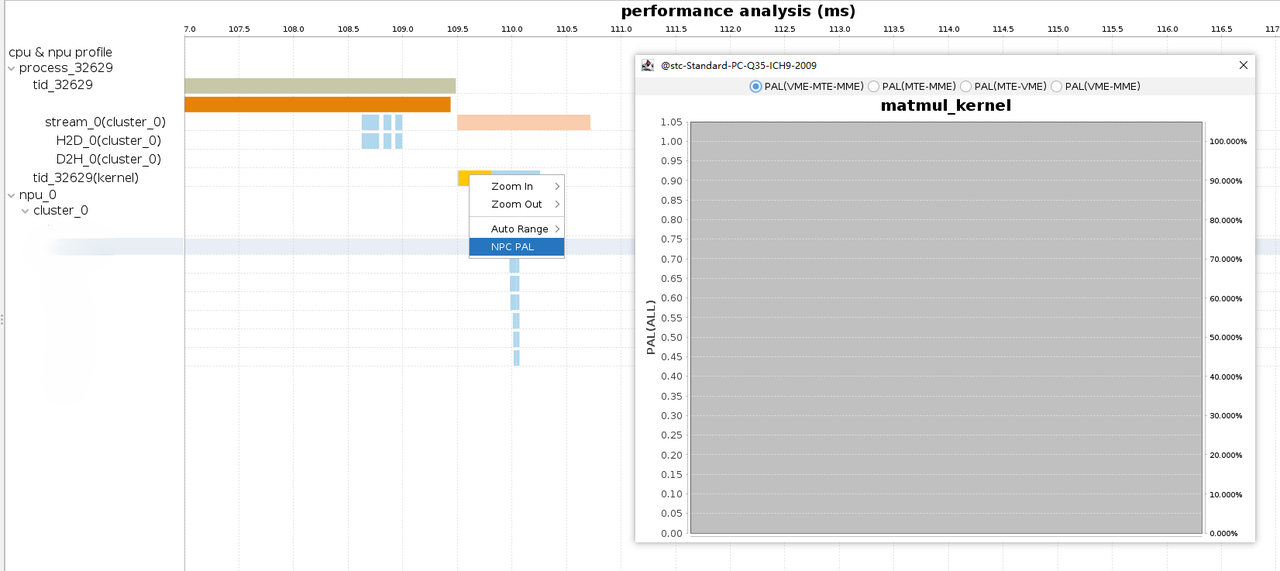
对比核函数时间轴数据
当多文件对比时,工具支持核函数执行数据锚点时间轴上下对齐,提供两个report的Timeline数据对比功能,方便对比时间轴图表。
-
生成两个用于对比的报告页面,拖动其中一个报告页面,使其上下分屏放置。
-
在菜单栏单击Compare > Show ComparePanel,页面底部出现ComparePanel, 最左是 < 按钮,中间是滑动面板,最右是 > 按钮。
-
单击底部的ComparePanel两侧按钮后,分屏时间轴自动根据上分屏对齐,并左右移动。ComparePanel滑动面板左右拖动时,上下分屏对齐左右移动报告视图。
-
单击菜单栏Compare > Hide ComparePanel后底部ComparePanel操作图标隐藏显示。
对比核函数数据(npc/cycle)
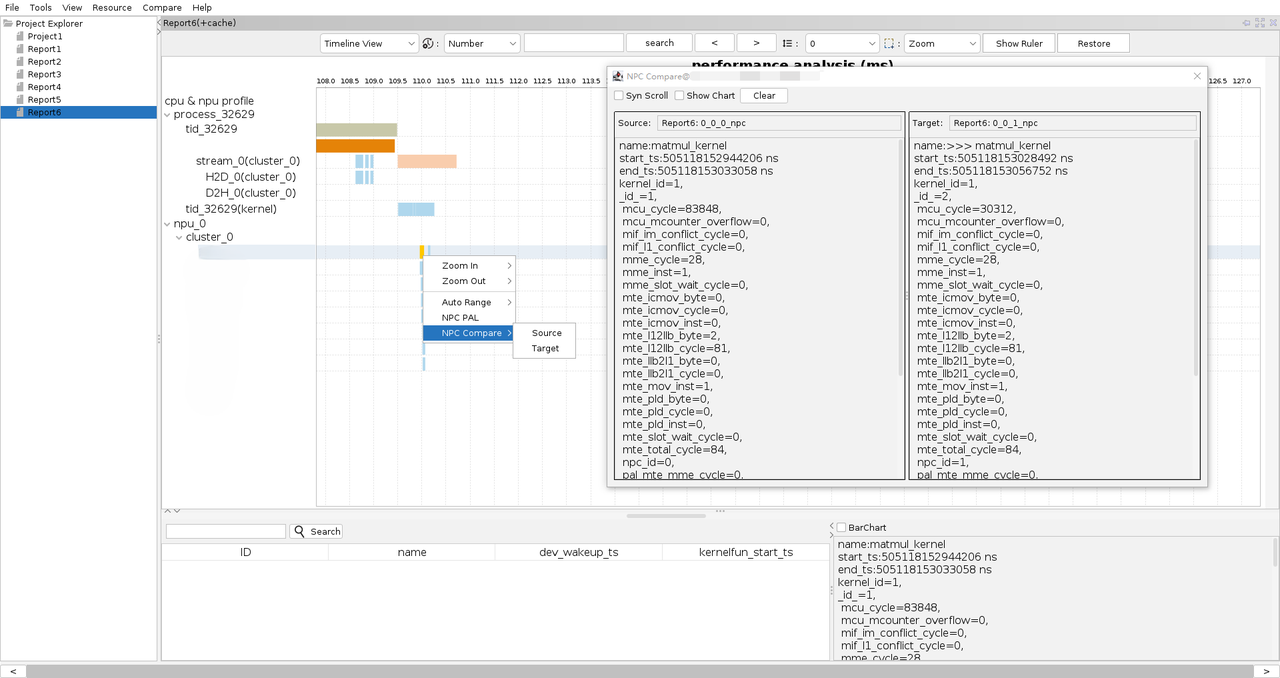
工具支持核函数数据(npc/cycle)对比,提供核函数运行参数的对比功能。
-
鼠标框选模式在Pan以外的任意模式中,右键单击选中的npu核函数,显示NPC Compare菜单及其子菜单Source、Target。
-
单击Source,设定选中的核函数为Source内容,左侧显示对应核函数信息。
-
再选择其他NPC的核函数块右键单击NPC Compare > Target,设定为Target内容,右侧显示对应核函数信息。
-
设置Source和Target对应的npu核函数后,弹窗中选中Syn Scroll复选框后,滑动左侧框中内容,右侧框中的内容会同步滑动。不选中Syn Scroll复选框时,可分别单独滑动查看左右两侧框中的内容,左右两边内容不联动。
属性列表
属性列表中列出了所选bar中包括的操作。属性列表中,您可执行以下任一操作:
-
属性列表中,单击某个操作,右侧会显示各项属性,包括起始时间、结束时间、资源、指令等。若单击的是某个核函数块,选中BarChart复选框,可切换条形图显示。
-
属性列表中,右键某个操作,单击Show current on timeline,反向定位到图表中。
-
搜索框中关键字,单击Search,检索到的数据高亮显示在列表中,单击上下箭头可以切换选中搜索结果。单击圆形图标可在时间轴图表中高亮所有搜索结果。
工具栏
切换信息显示
选择工具栏中的下拉框,然后执行以下任一操作:
-
如果查看分析结果的甘特图,请选择Timeline View。
-
如果查看项目信息(summary,local envirment,stop reason),请选择Summary。
-
如果查看项目日志信息,请选择Log。
说明:若导入非.properties(如:db文件、json文件),只有能查看分析结果的甘特图。

检索关键字
-
工具栏的搜索框中输入关键字,单击search。
-
高亮显示检索到的行或bar,时间轴图表和属性列表也会同步显示其信息。
-
单击
<或>切换至其他下一个搜索结果。
说明:关键字大小写敏感,支持模糊查询和正则表字符串。
![]()
调节行间距
选择工具栏中Vertical spacing的下拉框,选择行间距。

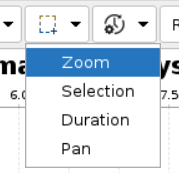
切换鼠标框选模式
选择工具栏中Marquee的下拉框,然后执行以下任一操作:
-
选择Selection:拖动鼠标框选多个bar,查看多个bar的汇总信息。
说明:当所选过多时,在等待统计过程中边框底部进度条显示当前统计进度。
-
选择Zoom:拖动鼠标框选图表内容,选取的内容被放大。
-
选择Pan:按住左右键,鼠标图标变成一个小手模样后,可对图表进行左右的拖动。
-
选择Duration:冻结图表窗口框选的范围,并显示所选范围时间长度。
说明:释放鼠标后除非用WS快捷键否则不会改变图表时间轴的开始结束范围。
切换时间轴展示方式
选择工具栏中Format的下拉框,然后执行以下任一操作:
-
选择Number:时间轴刻度展示单位为ms,向上滚动鼠标滚轮可以放大时间轴刻度,时间轴刻度单位会依次变为ms/us/ns。
-
选择Time:时间轴刻度单位为mm:ss,向上滚动鼠标滚轮可以放大时间轴刻度,时间轴刻度单位会变为mm:ss:sss。继续放大时间轴刻度,时间轴刻度单位会变成ms/us/ns。

垂直标尺参考线
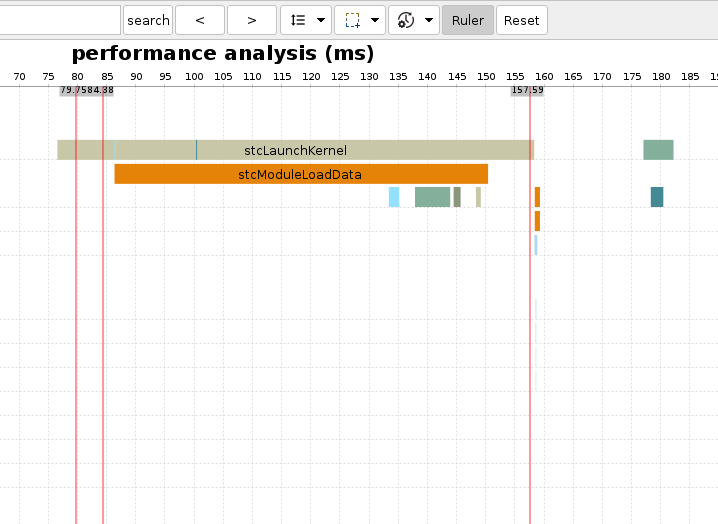
-
单击Show Ruler为选中状态时,鼠标移动到图表中,将会出现一条移动的垂直标尺参考线,时刻跟随鼠标。
-
单击图表后,创建一条红色垂直标尺的参考线A,参考线顶部显示所对应的时间轴值。
-
再次单击图表的其它地方,出现另一条红色垂直标尺的参考线B。若再次单击时,将会创建一条新的红色垂直标尺的参考线C,而参考线A将会消失。
恢复默认状态
单击Reset,时间轴图表恢复到默认状态。
显示或隐藏工具栏
选择菜单栏中View,然后执行以下任一操作:
-
如果隐藏工具栏,请选择Hide Toolbar。
-
如果显示工具栏,请选择Show Toolbar。
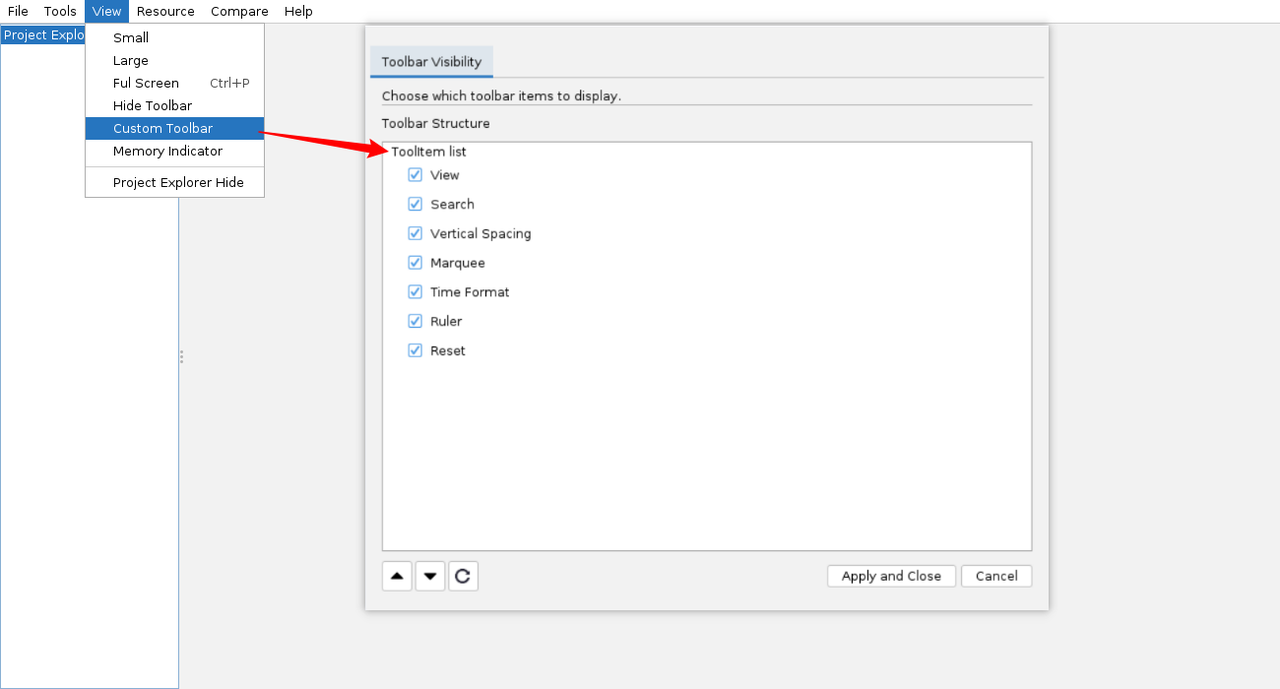
定制工具栏
-
菜单栏中选择View > Custom Toolbar。
-
打开工具栏配置窗口,您可执行以下操作:
-
选中需要显示或隐藏的工具栏条目。
-
单击上下按钮,对工具栏条目进行位置顺序移动。单击重置按钮,恢复工具栏条目的默认顺序和全选状态。
-
-
单击Apply and Close,对定制后的工具栏进行保存及应用。
更多功能
更改新建项目页面布局
新建项目页面中:
-
单击居中布局,布局会切换为居中布局。
-
单击左右布局,布局会切换为左右布局,左侧显示项目选项栏,右侧显示开始按钮。

代码编辑器
当目标程序为hc文件时,工具提供了一个hc文件代码编辑器。您可以使用该编辑器对源文件代码进行编辑、编译、运行等操作。代码编辑器包括以下操作:
| 操作 | 描述 |
|---|---|
| File > save | 保存当前代码文件。 |
| Search > Find | 搜索字符串,其中包括大小写匹配、正则匹配和全词匹配三种匹配模式;正序、逆序和循环查找三种查找顺序模式;标记匹配结果功能;输入框支持保留历史记录等功能。 |
| Search > Replace | 搜索并替换字符串,支持单个替换和全部替换。 |
| Search > Go To Line | 输入行号,快速定位到指定行。 |
| View | 编辑器代码配置。 |
| Style | 编辑器皮肤风格。 |
| Setting > Language Server | 添加语言服务。配置Clangd语言服务,指定Clangd的路径后,可在代码编辑器内使用代码提示,代码校验、代码补全等功能。 |
| Setting > Compile Prefer | 打开首选项编译配置界面,支持自定义配置编译命令行,可对编译命令进行修改、重置、保存。 |
| Help > Shortcut Key | 查看快捷键。 |
| Help > About RSyntaxTextArea | 查看RSyntaxTextArea控件license。 |
| compile | 编译当前hc文件,编译结果显示在输出窗口。 |
| profiler | 运行当前hc文件, 成功后在分析结果页面显示性能分析结果。 |
说明:对于本地的hc文件,支持源代码编辑和Clangd语言服务功能,而远程服务器上的hc文件,只支持代码编辑功能。
您在使用过程中,编辑器的相关提示信息会出现在下方的控制台里,右键单击Clear,清除控制台内信息。
工具皮肤
菜单栏中选择Tools > Options > LookFeel,根据您的喜好选择工具皮肤,目前支持Light(默认)、Dark、Metal、System。下图为Dark皮肤示例:
内存监控
菜单栏中选择View > Memory Indicator,工具界面的右下角状态栏中会出现内存指示器,显示工具使用的内存与JVM内存情况。

多语言切换
菜单栏中选择Tools > Options > Language,可自行切换工具显示语言。目前工具默认语言为英文。

导出核函数的运行数据
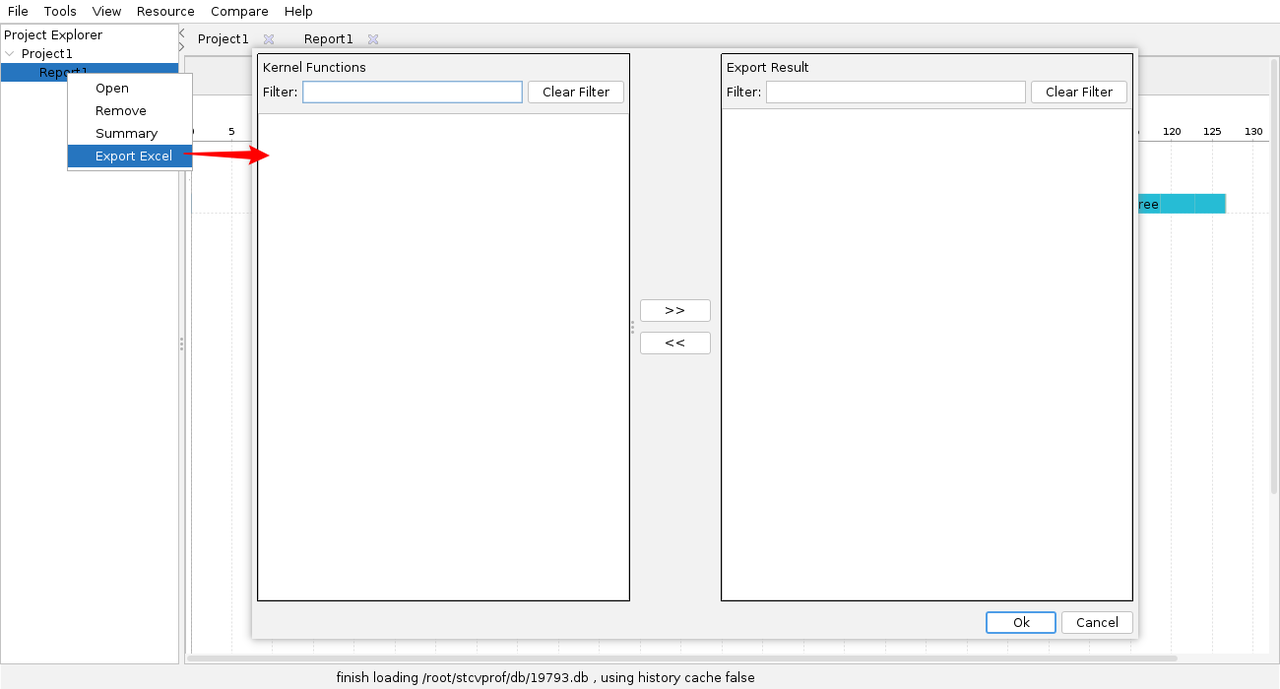
-
Project Explorer中选中导出数据所属的Report,右键单击Export Excel。
-
对话框的左侧Kernel Functions中,显示Report中包含的NPC核函数实例。
-
选取需要导出的核函数实例,单击 > > ,放到右侧Export Result中。单击< < ,选取的核函数重新放回左侧Kernel Functions栏中。
说明:工具还支持在Filter输入框中输入特定字符筛选包含该字符串的核函数实例。单击Clear Filter,所有核函数重新显示。
-
单击OK,选择保存csv文件的地址和文件名。
-
单击Save,导出核函数的运行数据。
配置项说明
菜单栏中单击Tools > Default Settings,打开可视化配置项页面。其中包括通用配置、渲染配置、SSH配置、字体配置和路径配置。
-
通用配置(General CFG)中配置项有LOAD_DATA_MODE、CACHE、CHECKSUM和SHOW_TIME_SCOPE,各项详细介绍请参考启动配置的各项说明。
-
渲染配置(Render CFG)中配置项有GAP、HW_ACCELS、TID_RENDER_SAMPLES和PRE_COUNT,各项详细介绍请参考启动配置的各项说明。
-
远程配置(SSH CFG)中主要包括所有的远程连接列表。
-
字体配置(Font CFG)中主要配置项是Timeline View、Summary和Log显示的字体和字号。
-
路径配置(Path CFG)中主要配置项是生成文件存储路径,主要包括DB文件、远端连接下载的文件、日志文件、临时缓存文件、json文件的储存路径。默认存放在
/<user_dir>/stcvprof/下对应的文件夹里。
说明:选择的储存路径权限受限时,输入框出现红边提示。
配置项各项说明如下:
| 配置项 | 说明 |
|---|---|
| LOAD_DATA_MODE |
|
| CACHE |
|
| CHECKSUM |
|
| GAP |
|
| HW_ACCELS |
|
| TID_RENDER_SAMPLES | 渲染时间轴图表时使用的数据采样率,采样率越大渲染出的图形越精细,在甘特图长度很短时也能正常显示。默认为500,对应启动配置文件的TID_RENDER_SAMPLES=500。目前采样率支持500、600、700、800、900、1000。 |
| PRE_COUNT | Timeline渲染时时间轴预渲染长度。默认值为5,取值范围为5-50。 |
| HOSTS | 远程主机连接信息,多台主机中间用逗号隔开。例如:HOSTS= xxxxxxx@x.x.x.x,xxxxxxx@x.x.x.1 |
| ACTIVE_THEME | 当前使用中的主题编号,0-Light、1-Dark、2-Metal、3-System。例如:ACTIVE_THEME=0 |
| TOOLBAR | 当前Report界面显示的工具条中的工具项、1-显示、0-隐藏,多个工具项中间用逗号隔开,其中排列顺序从左到右对应工具栏配置页面的从上到下。例如:TOOLBAR=view:1,search:1,vertical spacing:1,marquee:1,format:1,restore:1 |
| SHOW_TIME_SCOPE |
|
保存可视化配置页面中修改的配置项,自动会更新到配置文件中,配置文件为在/<user_dir>/stcvprof/conf/stc-vprof.properties。也可自行修改配置文件,重新打开stc-vprof工具配置项生效。
若删除配置文件,再次打开stc-vprof工具时,在原位置新建默认启动配置文件,工具的配置页面中的配置项也会被初始化。其中默认启动配置如下:
# 0:单窗口式,1:标准模式
LOAD_DATA_MODE=1
# 0:手动调节GAP,1:自动调节GAP
AUTO_DATA_GAP=1
# 0:没有开启缓存,1:开启缓存
STARTUP_CACHE=0
# 0:没有开启硬件加速,1:开启硬件加速
HW_ACCELS=0
# 500~1000,每个tid的最大采样渲染数量
TID_RENDER_SAMPLES=500
常见问题
-
目前stc-vprof工具还提供查看用户手册功能,目前该功能属于试用功能,可保证基本功能但是没有经过完整测试,如有兴趣请联系技术支持获取详细使用说明。
-
单台服务器同时只允许启动一个界面。如果已启动了stc-vprof,再次尝试启动时会出现以下报错。
-
如果文件类型不匹配,例如新建项目时选择并执行分析结果文件(.db、.json),则出现以下报错。分析结果文件(.db、.json)应该通过导入项目的形式打开,新建项目时需要选择可执行的目标程序,例如Python脚本、C++执行程序等。