STC_LLM使用指南
STC_LLM概述
本文档将演示如何基于希姆计算软硬件部署LLM,提供推理服务、处理推理任务并监控推理过程中的指标。
主流的开源LLM往往基于HuggingFace等格式,权重保存为bin或者safetensors,为更高效地完成LLM推理任务,希姆计算面向LLM自研了推理框架STC_LLM。STC_LLM在AI编译器、手写算子的基础上对LLM的推理过程进行了封装,您可以方便地导入、替换LLM并完成推理任务,简化了LLM的部署和使用过程。
STC_LLM面向LLM支持以下特性:
-
编译阶段:支持权重转换、量化预处理、Tensor并行处理超大规模的权重等。
-
服务阶段:支持动态batch管理优化端到端吞吐。
-
推理阶段:支持kernel级别的优化、KV Cache优化等。
基于STC_LLM的典型推理流程如下图所示:
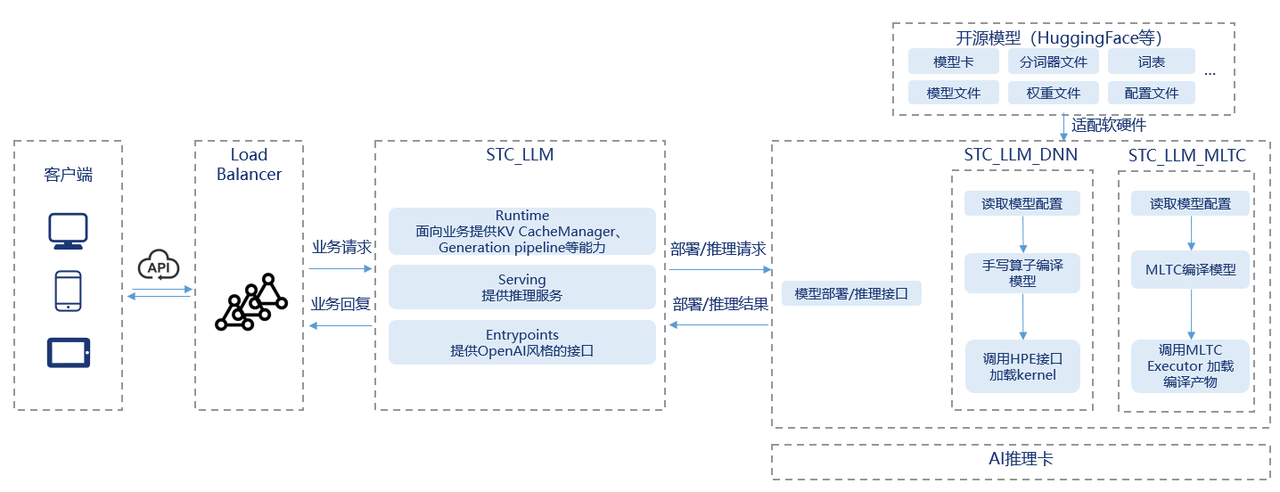
STC_LLM_DNN是大模型通过手写算子等特殊处理编译后部署LLM的框架。STC_LLM_MLTC是大模型通过MLTC编译器编译后部署LLM的框架。目前,采用STC_LLM_DNN框架进行编译部署的大模型,在推理环节展现出更优的性能表现。
前提条件
-
确保服务器的内存满足模型的要求,大模型的HuggingFace项目文件都很大,在转换权重时还会创建副本,因此需要配备尽量大的内存。
-
确保能访问HuggingFace等渠道,且可以下载带有LFS标记的文件。
-
准备LLM推理环境,安装HPE、Python V3.10、HPE Python、STC_LLM。
-
部署手写大模型时,确保已安装STC_LLM_DNN。
-
通过MLTC编译器编译和部署大模型时,确保已安装好STC_LLM_MLTC和MLTC。
-
说明:各项软件的具体操作,请参见STCRP安装指南。
提供推理服务
STC_LLM中封装了OpenAI风格的接口,服务端可以提供推理服务并处理推理请求,客户端通过Python脚本、curl命令等方式和LLM交互。我们支持手写大模型和通过MLTC编译器编译大模型,以Qwen2-7B-Instruct为例演示STC_LLM提供推理服务步骤。
说明:目前支持的LLM列表,请参见模型支持说明。
服务端启动推理服务
准备模型
-
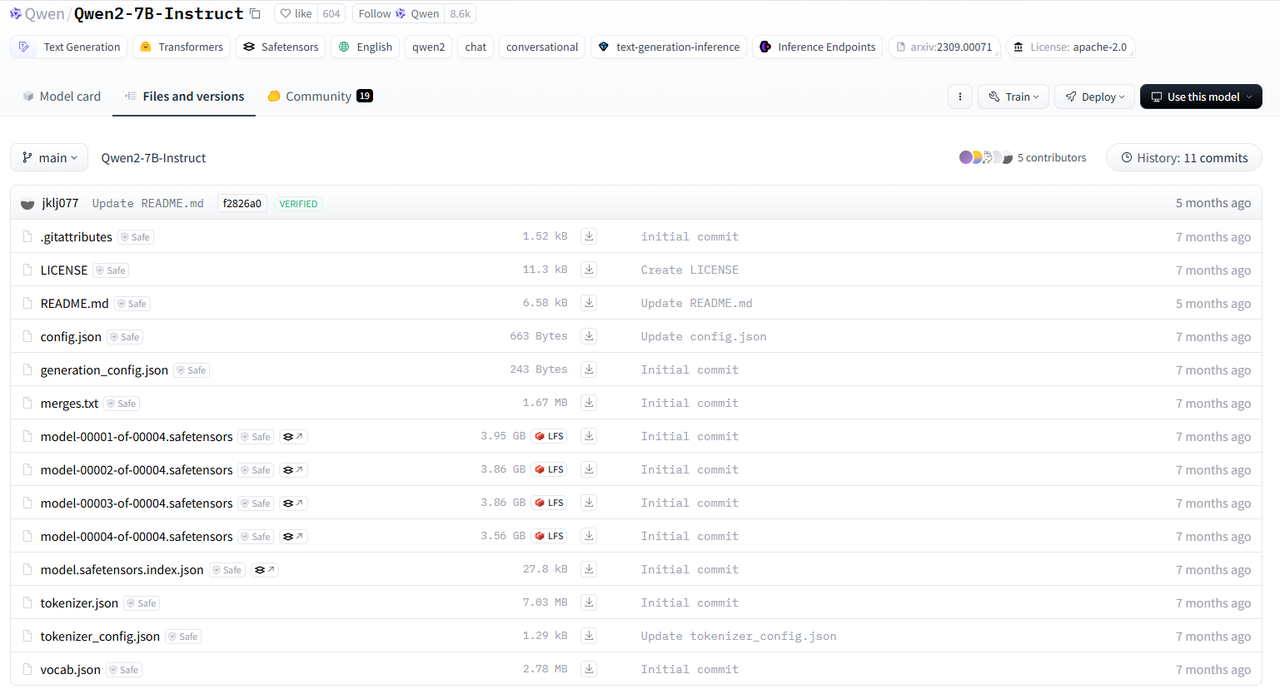
从HuggingFace等渠道获取Qwen2-7B-Instruct文件,包括模型文件、权重文件、分词器文件、词表等,并复制到目标服务器。
-
(可选)使用SNC量化工具生成量化系数。详细步骤请参见生成量化模型章节。
-
(可选)在本地验证大模型的可行性,支持本地验证手写大模型和通过MLTC编译器编译大模型,详细步骤请参见本地验证模型章节。
启动推理服务
我们支持手写大模型和MLTC编译大模型,在服务端启动推理服务时可以指定编译部署方式。
-
手写大模型示例:
-
手动转换权重并启动推理服务。
-
手动转换权重。
$ python -m stc_llm_dnn.tools.convert_weight \
-m Qwen/Qwen2-7B-Instruct \
-p /model/Qwen2-7b-Instruct/Qwen2-7B-Instruct \
-o /model/Qwen2-7b-Instruct/Qwen2-7B-Instruct_2npu_dataset \
-n 2配置选项说明:
参数选项 描述 是否必选 -m 模型在HuggingFace上的ID。 是 -p 原始权重所在的本地路径。 是 -o 转换后的NPU权重的导出路径。 是 -n 指定转换后的NPU权重适配的目标NPU数量,即原始权重将被拆分的份数。为特定数量NPU(如4NPU)转换的权重,无法直接用于不同数量(如2NPU)的 NPU。 是 -
启动推理服务。
$ python -m stc_llm.entrypoints.openai.api_server \
--model_name Qwen/Qwen2-7B-Instruct \
--tok_dir /model/qwen2-7b-instruct/Qwen2-7B-Instruct \
--weight_dir /model/qwen2-7b-instruct/Qwen2-7B-Instruct/2npu/ \
--max_tasks 256 \
--custom_parameters \
--temperature 0.5 \
--top_p 0.2 \
--top_k 1 \
--max_output_len 4096 \
--port 8080 \
--device 0 1
-
-
自动转换权重并启动推理服务,使用
--original_weight_dir原始权重。$ python -m stc_llm.entrypoints.openai.api_server \
--model_name Qwen/Qwen2-7B-Instruct \
--tok_dir /model/qwen2-7b-instruct/Qwen2-7B-Instruct \
--original_weight_dir=/model/qwen2-7b-instruct/Qwen2-7B-Instruct \
--max_tasks 256 \
--custom_parameters \
--temperature 0.5 \
--top_p 0.2 \
--top_k 1 \
--max_output_len 4096 \
--port 8080 \
--device 0 1
-
-
MLTC编译大模型并启动推理服务:
$ python -m stc_llm.entrypoints.openai.api_server \
--model_name Qwen/Qwen2-7B-Instruct \
--tok_dir /model/qwen2-7b-instruct \
--mltc_weight_dir /model/qwen2-7b-instruct-weight/qwen2-7b-32heads-mask-28layers \
--devices 0 1 \
--compiler mltc
# 忽略部分回显
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:18000 (Press CTRL+C to quit)
大模型也可使用投机采样方式提高性能。投机采样是一种高效的大模型推理优化策略,通过让同一系列的小模型预先生成多个token,再有大模型批量验证的方式。它巧妙地融合了小模型快速生成token的优势以及大模型精准评估token的能力,从而在提升自回归语言模型推理速度的同时,确保了生成结果的高质量。具体示例可参见投机采样示例章节。
配置项说明
| 配置项 | 是否必填 | 数据类型 | 描述 |
|---|---|---|---|
| model_name | 是 | str | 待部署模型的名称,建议与HuggingFace等渠道中的名称保持一致。 |
| devices | 是 | list | 模型推理时占用NPU设备的ID列表,STC_LLM会根据NPU设备的数量将原始权重自动切分为匹配的份数。 |
| tok_dir | 是 | str | 加载模型的分词器(tokenizer)文件的路径。 |
| compiler | 是 | str | mltc:采用MLTC编译器编译。stc_llm_dnn:默认值,采用手写方式编译。 |
| embed_on_host | 否 | bool | - True:启用host侧word_embedding计算。 - False:默认值。禁用host侧word_embedding计算。 |
| output_on_host | 否 | bool | - True:启用host侧logits计算。 - False:默认值。禁用host侧logits计算。 |
| original_weight_dir | 否 | str | 加载模型的原始权重文件的路径。如果您没有在目标服务器上转换过权重,则至少需要从原始权重转换一次,这时original_weight_dir为必填项。 |
| weight_dir | 否 | str | 从原始权重转换后可以在NPU设备上使用的权重的路径。 - 如果 weight_dir指向的路径存在权重文件,则使用这些权重。- 如果 weight_dir指向的路径不存在权重文件,则STC_LLM尝试从original_weight_dir获取原始权重进行转换,并将转换后的权重放到weight_dir指向的路径。 |
| mltc_weight_dir | 是 说明:当采用MLTC编译方式时为必填。 | str | 采用MLTC编译方式时的权重路径。 |
| mltc_ht_file | 否 | str | 采用MLTC编译方式时,vmfb文件存放的路径。 |
| engine_dir | 否 | str | 临时路径,存放生成的模型代码(cpp)文件。STC_LLM会基于模型代码文件生成NPU设备上的可执行文件,您可以查看模型代码文件了解代码逻辑或者进行模型调试。默认值为.cache/stc_llm。 |
| slot_number_per_segment | 否 | int | 每个segment占用的slot的数量,对应一组token所需的KV Cache空间。默认值为256。 |
| max_tasks | 否 | int | 支持同时执行的最大task数量,每个task分配一个stream完成一轮对话。默认值为256。 |
| custom_parameters | 否 | bool | - True:允许task自定义temperature、top_p、top_k、logprobs、top_logprobs。 - False:默认值。禁止task自定义temperature、top_p、top_k、logprobs、top_logprobs。 |
| temperature | 否 | float | 超参数之一,控制生成输出的随机性,值越低保证更多的确定性,值越高引入更多的随机性。需要将custom_parameters配置为True才可以修改,默认值为0.5,数值范围为[0.0, 2.0]。 |
| top_p | 否 | float | 超参数之一,在生成输出抽样时排除累积概率低于该值的token。需要将custom_parameters配置为True才可以修改,默认值为0.2,数值范围为(0.0, 1.0]。 |
| top_k | 否 | int | 超参数之一,在生成输出抽样时只在概率top k个token中进行。需要将custom_parameters配置为True才可以修改,默认值为20,数值范围为[1, 词表长度]。 |
| dma_preload | 否 | bool | - True:默认值。启用DMA预取,通过拷贝权重、矩阵计算等并行操作加速推理。 - False:禁用DMA预取。 |
| render_cpp | 否 | bool | - True:默认值。部署模型时重新生成并覆盖当前的模型代码(cpp)文件。 - False:部署模型时使用当前的模型代码(cpp)文件,不重新生成。 |
| quant_type | 否 | str | 指定是否通过量化节省内存空间。 - fp16:默认值,不启用压缩和量化。 - w8a8:启用量化。 - w8a16:启用压缩。 |
| compress_factor | 否 | int | 压缩倍数,仅在quant_type为w8a16时生效,支持的压缩倍数包括128、64、32、16、8、1、-1,压缩倍数越高,能节省的内存空间越多。压缩倍数为-1时对应per-channel方式。 |
客户端发起推理请求
发起推理请求
在客户端调用completions或者chat_completions接口发起推理请求。
-
补全文本示例,向LLM提供起始文本,LLM自动将起始文本补全为一段话、文章等形式。
-
curl方式:
# 调用completions接口示例
$ curl http://172.16.xx.xxx:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2-7B-Instruct",
"prompt": "你是一个写作小助手,请帮忙写一篇描述江南春天长度不少于1024个token的小作文,要求其中必须涉及到描述朦胧的烟雨,蜿蜒的石板小路等景物,同时既要描写出阳光明媚、风和日丽的场景,也要描述出烟雨绵绵、云气氤氲的场景。然后文章中需要包含排比、比喻、对偶、拟人等修辞手法,必要时可以引用一些符合文章主题语境的古诗词中的句子以增加文采。",
"max_tokens": 256,
}'
{"model":"Qwen/Qwen2-7B-Instruct","object":"text_completion","created":1736219436,"choices":[{"index":0,"text":"江南的春天,如同一位羞涩的少女,轻启朱唇,吐露着温柔的气息。她以一种难以言喻的美,缓缓铺展开一幅幅细腻的画卷,让人心醉神迷。在这片土地上,春天的长度仿佛被时间的笔触拉长,每一刻都充满了诗意与生机。\n\n烟雨是江南春天的魂魄,它轻柔地拂过每一寸土地,为大地披上了一层薄薄的轻纱。那烟雨,如同细丝般缠绕在古老的石板小路上,蜿蜒曲折,仿佛是大自然的笔触,勾勒出一幅幅水墨画。雨滴落在青石板上,发出清脆的响声,如同古琴的低吟,悠扬而深邃。这烟雨,是江南春天的序曲,它以一种朦胧而神秘的方式,唤醒了沉睡的大地,让万物在湿润中苏醒。\n\n阳光明媚的日子,江南的春天则展现出另一番景象。阳光如同金色的丝线,温柔地洒在大地上,将万物染上了一层金黄的光泽。微风轻拂,带着花香与泥土的芬芳,让人感到心旷","finish_reason":"stop"}]} -
Python脚本方式:
# 调用completions接口示例
$ pip3 install openai
$ cat test_qwen2-7b-instruct-completions.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://172.16.xxx.xxx:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
completion = client.completions.create(model="Qwen/Qwen2-7B-Instruct", prompt="San Francisco is a", max_tokens=50)
$ python3 test_qwen2-7b-instruct-completions.py
Completion result: Completion(id=None, choices=[CompletionChoice(finish_reason='stop', index=0, logprobs=None, text='San Francisco is a city located in the northern part of California, United States. It is known for its iconic landmarks such as the Golden Gate Bridge, Alcatraz Island, and the hilly landscape. San Francisco is also famous for its diverse culture')], created=1736235685, model='Qwen/Qwen2-7B-Instruct', object='text_completion', system_fingerprint=None, usage=None) -
发起聊天示例,向LLM提供系统角色信息以及聊天输入,LLM理解输入并按其系统角色回复用户。
-
curl方式:
# 调用chat_completions接口示例
$ curl http:/localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2-7B-Instruct",
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."}
]
}'
{"model":"Qwen/Qwen2-7B-Instruct","object":"chat.completion","choices":[{"index":0,"message":{"role":"assistant","content":"Sure, here's a classic joke:\n\nWhy did the tomato turn red?\n\nBecause it saw the salad dressing!","function_call":null},"finish_reason":"stop","logprobs":{"content":null}}],"created":1736235856} -
Python脚本示例:
# 调用completions接口示例
$ pip3 install openai
$ cat test_qwen2-7b-instruct-chat-completions.py
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://172.16.xxx.xxx:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
chat_response = client.chat.completions.create(
model="Qwen/Qwen2-7B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Tell me a joke."},
],
max_tokens=256
)
print("Chat response:", chat_response)
$ python3 test_qwen2-7b-instruct-chat-completions.py
Chat response: ChatCompletion(id=None, choices=[Choice(finish_reason='stop', index=0, logprobs=ChoiceLogprobs(content=None, refusal=None), message=ChatCompletionMessage(content="Sure, here's a classic joke:\n\nWhy did the tomato turn red?\n\nBecause it saw the salad dressing!", refusal=None, role='assistant', audio=None, function_call=None, tool_calls=None))], created=1736236505, model='Qwen/Qwen2-7B-Instruct', object='chat.completion', service_tier=None, system_fingerprint=None, usage=None)
-
-
completions参数
| 参数名 | 是否必填 | 数据类型 | 描述 |
|---|---|---|---|
| model | 是 | str | 待调用模型的名称,一般为启动推理服务时所运行的模型名称。 |
| prompt | 是 | str | 描述要求模型完成的任务,例如补全文本、回答问题。 |
| temperature | 否 | float | 超参数之一,控制生成输出的随机性,值越低保证更多的确定性,值越高引入更多的随机性。需要在部署模型时将custom_parameters配置为True才可以修改,数值范围为[0.0, 2.0]。 |
| top_p | 否 | float | 超参数之一,在生成输出抽样时排除累积概率低于该值的token。需要在部署模型时将custom_parameters配置为True才可以修改,数值范围为(0.0, 1.0]。 |
| top_k | 否 | int | 超参数之一,在生成输出抽样时只在概率top k个token中进行。需要在部署模型时将custom_parameters配置为True才可以修改,数值范围为[1, 词表长度]。 |
| max_tokens | 否 | int | 最长返回的token数量。数值范围为[1, 模型支持上下文长度]。 |
| logprobs | 否 | bool | 需要在部署模型时将custom_parameters配置为True才可以修改。 - true:启用返回生成输出token的对数概率。 - false:默认值,禁用返回生成输出token的对数概率。 |
| top_logprobs | 否 | int | 指定在每个生成输出token时一并返回最有可能的token数量,每个token都带有对数概率。需要将logprobs开关设置为true方可生效,数值范围为[0, 5]。 |
| stream | 否 | bool | - true:启用流式传输,当模型生成一定数量的token后,立即将token传输给客户端,而不是等所有token生成完毕后,从而减少用户的等待时间。 - false:默认值,禁用流式传输,等所有token生成完毕后,再将所有token传输给客户端。 |
chat_completions参数
| 参数名 | 是否必填 | 数据类型 | 描述 |
|---|---|---|---|
| model | 是 | str | 待调用模型的名称,一般为启动推理服务时所运行的模型名称。 |
| messages | 是 | dict | 传给模型的消息对象,您可以通过字段组合控制模型行为,获得预期的输出。 - role字段:用于设置角色,例如system(系统角色)、user(用户角色)。 - content字段:用于描述要求,例如通过system描述助手扮演的系统角色,通过user描述用户要求助手完成创作文章、回答问题等任务。 |
| temperature | 否 | float | 超参数之一,控制生成输出的随机性,值越低保证更多的确定性,值越高引入更多的随机性。需要在部署模型时将custom_parameters配置为True才可以修改,数值范围为[0.0, 2.0]。 |
| top_p | 否 | float | 超参数之一,在生成输出抽样时排除累积概率低于该值的token。需要在部署模型时将custom_parameters配置为True才可以修改,数值范围为(0.0, 1.0]。 |
| top_k | 否 | int | 超参数之一,在生成输出抽样时只在概率top k个token中进行。需要在部署模型时将custom_parameters配置为True才可以修改,数值范围为[1, 词表长度]。 |
| max_tokens | 否 | int | 最长返回的token数量。数值范围为[1, 模型支持上下文长度]。 |
| logprobs | 否 | bool | 需要在部署模型时将custom_parameters配置为True才可以修改。 - true:启用返回生成输出token的对数概率。 - false:默认值,禁用返回生成输出token的对数概率。 |
| top_logprobs | 否 | int | 指定在每个生成输出token时一并返回最有可能的token数量,每个token都带有对数概率。需要将logprobs开关设置为true方可生效,数值范围为[0, 5]。 |
| stream | 否 | bool | - true:启用流式传输,当模型生成一定数量的token后,立即将token传输给客户端,而不是等所有token生成完毕后,从而减少用户的等待时间。 - false:默认值,禁用流式传输,等所有token生成完毕后,再将所有token传输给客户端。 |
监控推理指标
前提条件
- 已在服务端启动推理服务。
指标类型
STC_LLM基于Prometheus、Grafana生态实现了监控功能,遵循Prometheus expression语法添加需要监控的推理指标即可。支持的推理指标包括:
| 推理指标 | 推理指标含义 | Prometheus expression示例 |
|---|---|---|
| prompt处理吞吐 | 每秒处理输入prompt token的吞吐量 | stc_llm:avg_prompt_throughput_toks_per_s{model_name="THUDM/chatglm3-6b"} |
| generation处理吞吐 | 每秒输出token的吞吐量 | stc_llm:avg_generation_throughput_toks_per_s{model_name="THUDM/chatglm3-6b"} |
| 推理次数 | 启动推理服务后完成推理的次数 | stc_llm:time_to_inference_count{model_name="THUDM/chatglm3-6b"} |
| 首token时延 | 输出首字token花费的时间 | stc_llm:first_token_time{model_name="THUDM/chatglm3-6b"} |
| 任务推理总时延 | 完成单轮输出花费的时间 | stc_llm:task_duration{model_name="THUDM/chatglm3-6b"} |
| 任务decoder时延 | 从输出首字token开始,到完成单轮输出所花费的时间 | stc_llm:task_decoder_latency{model_name="THUDM/chatglm3-6b"} |
| avg generation latency | 输出单位token所花费的时间 | stc_llm:avg_generation_latency{model_name="THUDM/chatglm3-6b"} |
| running tasks count | 进行中的对话任务数量 | stc_llm:num_requests_running{model_name="THUDM/chatglm3-6b"} |
| swapped tasks count | 因故停止的对话任务数量 | stc_llm:num_requests_swapped{model_name="THUDM/chatglm3-6b"} |
| waiting tasks count | 等待中的对话任务数量 | stc_llm:num_requests_waiting{model_name="THUDM/chatglm3-6b"} |
| prompt tokens total count | 输入prompt token的总数量 | stc_llm:prompt_tokens_total{model_name="THUDM/chatglm3-6b"} |
| generation tokens total count | 输出token的总数量 | stc_llm:generation_tokens_total{model_name="THUDM/chatglm3-6b"} |
服务端操作
您需要在服务端安装Prometheus、Grafana并确保相关服务正常运行。
-
安装Prometheus。请根据服务器情况选择合适的安装方式,例如APT源、离线安装包等,相关说明可以参见Prometheus官方开源项目。
-
修改Prometheus配置,默认配置文件为
/etc/prometheus/prometheus.yml。-
提供Prometheus服务的地址,默认端口号为9090。
- job_name: "prometheus"
static_configs:
- targets: ["localhost:9090"] -
监控推理服务的地址,在对应job(即通过stc_llm.entrypoints.openai.api_server启动的推理服务)的
scrape_configs字段下添加IP地址和端口号即可。- job_name: "openai_api"
scrape_interval: 5s
static_configs:
- targets: ["localhost:18000"]
-
-
启动Prometheus服务并确认服务状态。
$ sudo systemctl start prometheus
$ sudo systemctl status prometheus
prometheus.service - Prometheus
Loaded: loaded (/etc/systemd/system/prometheus.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2024-08-19 16:24:11 CST; 1h 6min ago
Main PID: 3112690 (prometheus)
Tasks: 53 (limit: 629145)
Memory: 48.4M
CGroup: /system.slice/prometheus.service
└─3112690 /usr/local/bin/prometheus --config.file /etc/prometheus/prometheus.yml --storage.tsdb.path /var/lib/prometheus/ --web.console.templates=/etc/prometheus/consoles --web.console.libra> -
安装Grafana。请根据服务器情况选择合适的安装方式,例如APT源、离线安装包等,相关说明可以参见Grafana官方开源项目。
-
修改Grafana配置,默认配置文件为
/etc/grafana/grafana.ini。-
提供Grafana服务的地址,默认端口号为3000。
-
登录Grafana Web端的用户名和密码。
http_port = 3000
admin_user = admin
admin_password = 123.com
-
-
启动Grafana服务并确认服务状态。
$ sudo systemctl start grafana-server
$ sudo systemctl status grafana-server
grafana-server.service - Grafana instance
Loaded: loaded (/lib/systemd/system/grafana-server.service; disabled; vendor preset: enabled)
Active: active (running) since Mon 2024-08-19 10:01:25 CST; 7h ago
Docs: http://docs.grafana.org
Main PID: 2970010 (grafana)
Tasks: 38 (limit: 629145)
Memory: 53.8M
CGroup: /system.slice/grafana-server.service
└─2970010 /usr/share/grafana/bin/grafana server --config=/etc/grafana/grafana.ini --pidfile=/run/grafana/grafana-server.pid --packaging=deb cfg:default.paths.logs=/var/log/grafana cfg:defaul>
Web端操作(Prometheus)
Prometheus提供了指标收集和告警等监控功能,您可以登录Prometheus的Web页面管理需要监控的推理指标。
-
访问Prometheus Web页面。如果Prometheus服务使用了默认端口,则Web页面地址为
http://{server_ip}:9090。 -
单击Add Panel添加指标面板。
-
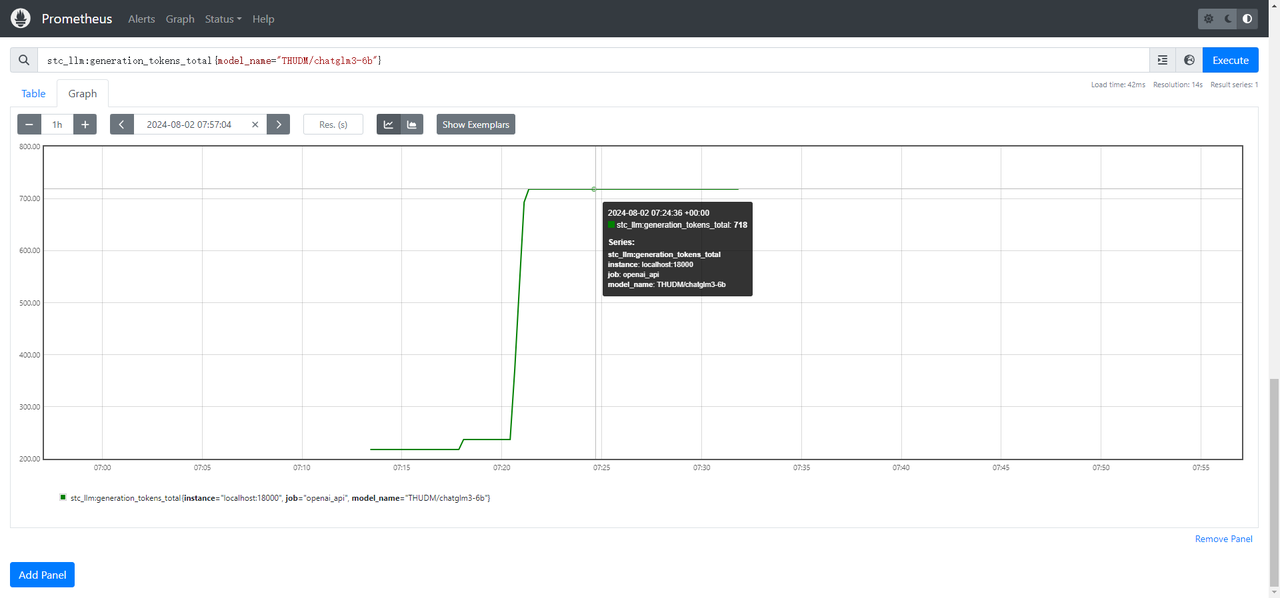
在输入框中填写Prometheus expression,以监控THUDM/chatglm3-6b模型的generation吞吐量为例,填写
stc_llm:avg_generation_throughput_toks_per_s{model_name="THUDM/chatglm3-6b"}。 -
单击Execute完成指标添加。
-
单击Graph,调整时间范围至执行了推理任务的时间段,即可查看到对应的推理指标。
Web端操作(Grafana)
Grafana提供了丰富和美观的可视化功能,使用时将Prometheus添加为数据源并创建Dashboard汇总Panel,即可一站式多维度展示推理指标。
登录Grafana
-
访问Grafana Web页面。如果Grafana服务使用了默认端口,则Web页面地址为
http://{server_ip}:3000。 -
输入配置的用户名和密码。
添加Prometheus数据源
-
在左侧导航栏,单击Connections > Data sources。
-
单击Add datasource。
-
选择Prometheus。
-
在Settings页面,完成Name、Prometheus server URL等配置,然后单击Save & Test。提示
Successfully queried the Prometheus API.,即代表数据源添加成功。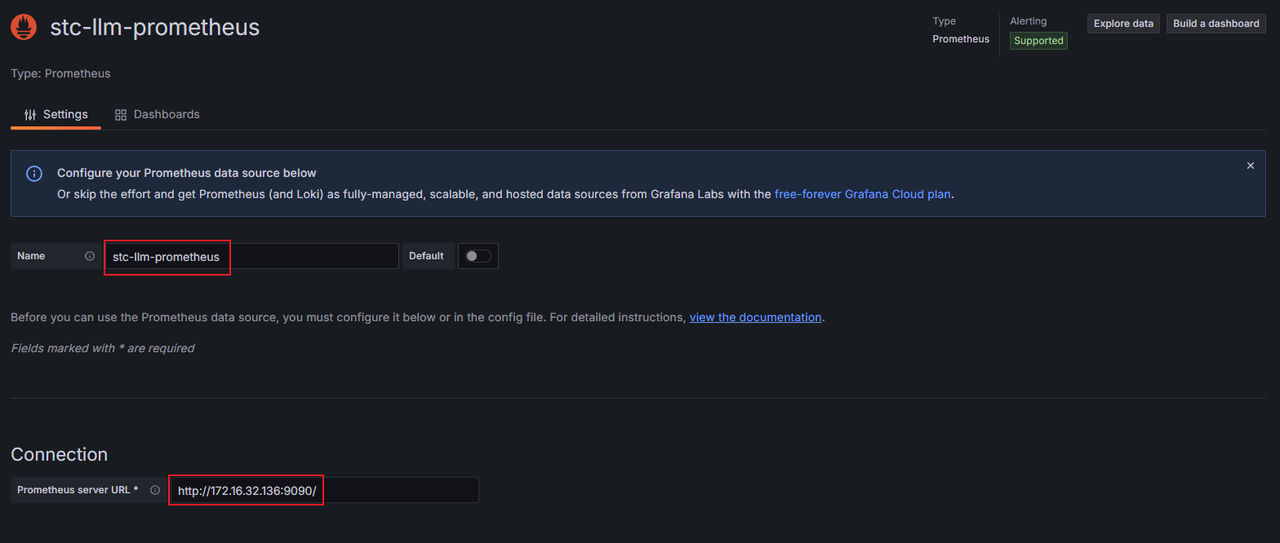
创建STC_LLM Dashboard
-
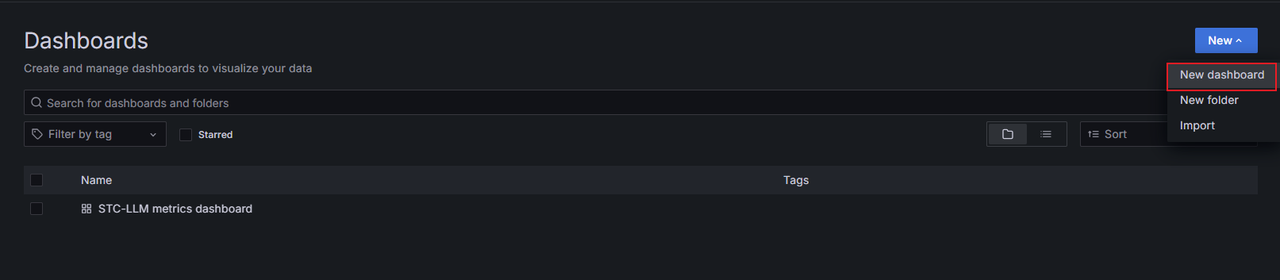
在左侧导航栏,单击Dashboards。
-
单击New > New dashboard。
-
单击Add visualization。
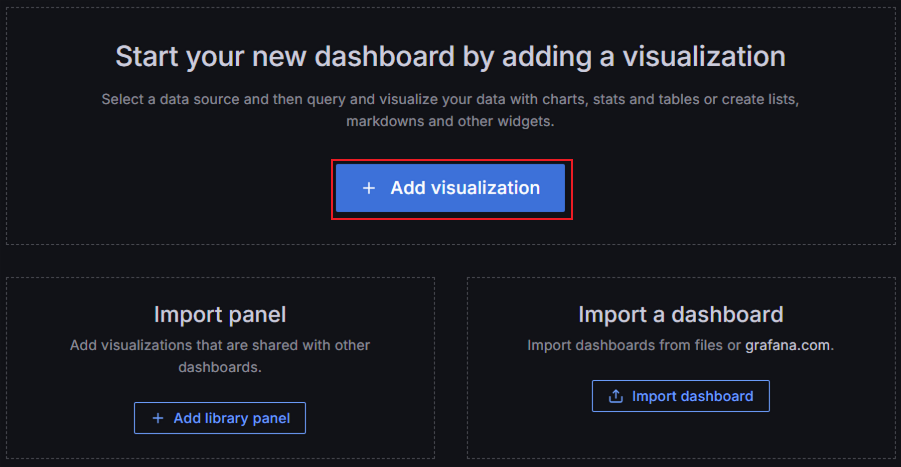
-
选择已添加的Prometheus数据源。
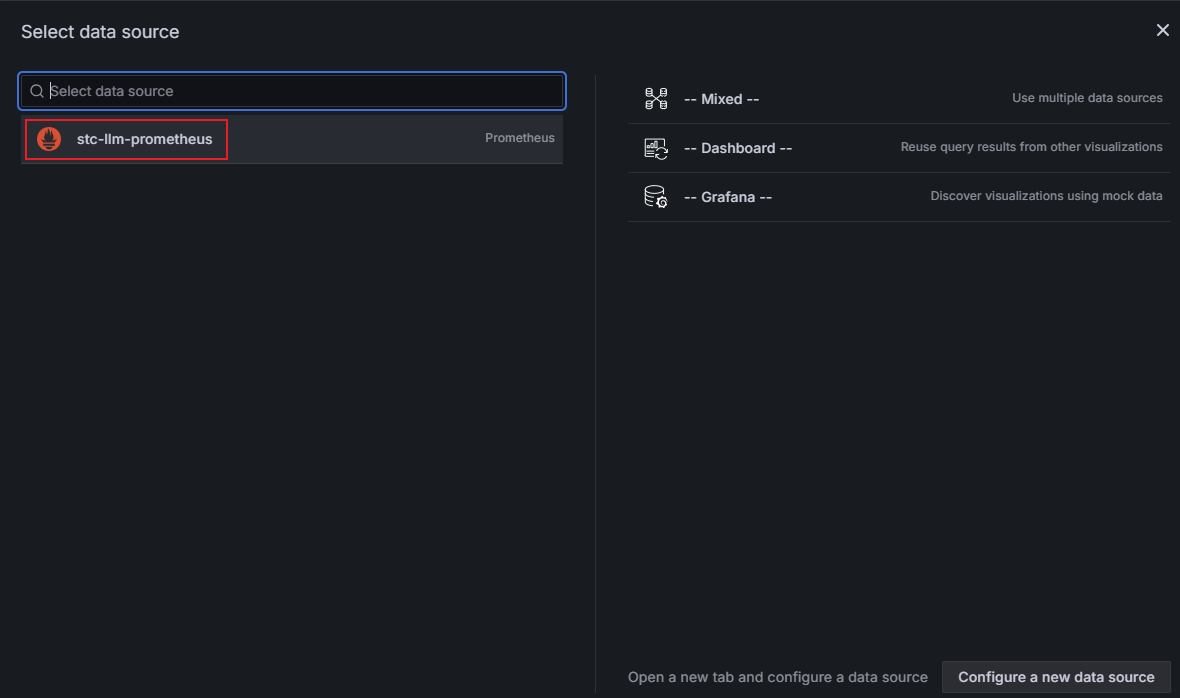
-
添加Panel。切换到Code模式,在输入框中填写Prometheus expression,以监控THUDM/chatglm3-6b模型的推理次数为例,填写
stc_llm:time_to_inference_count{model_name="THUDM/chatglm3-6b"},单击Run queries查看效果,然后单击Save。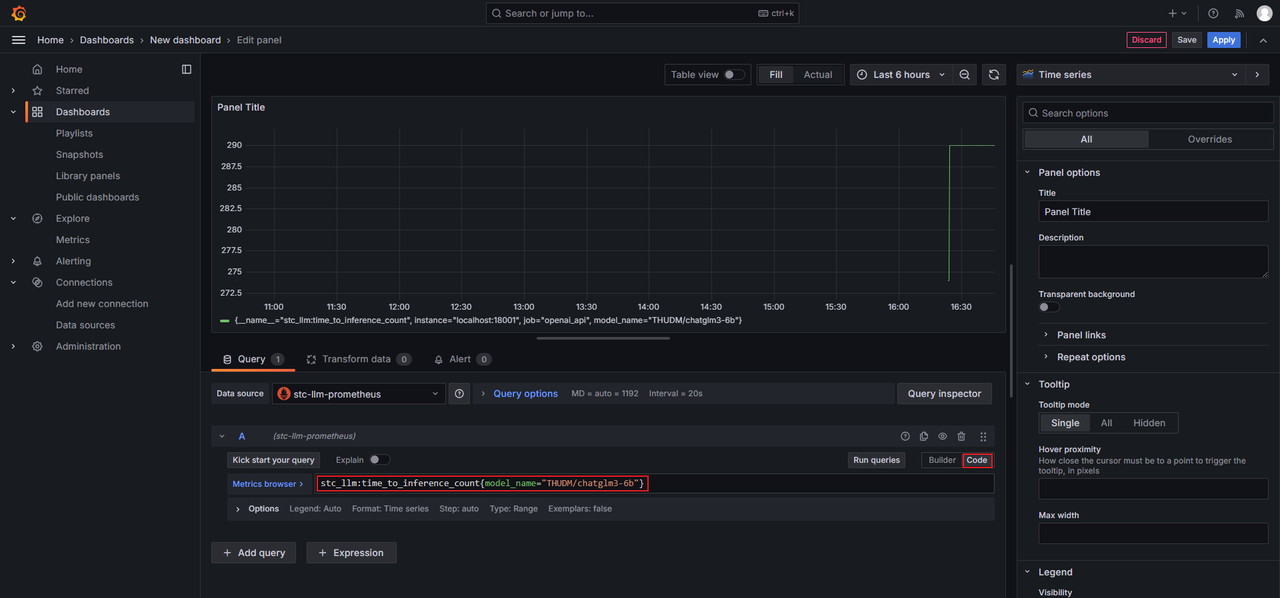
-
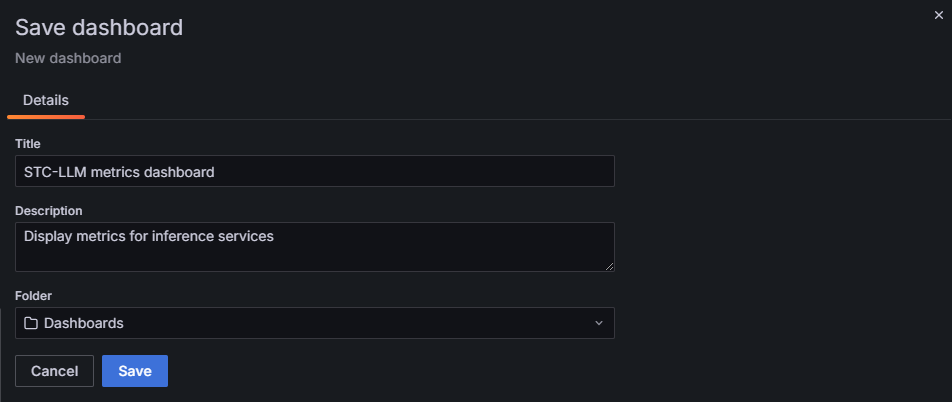
按提示填入信息,然后单击Save。
-
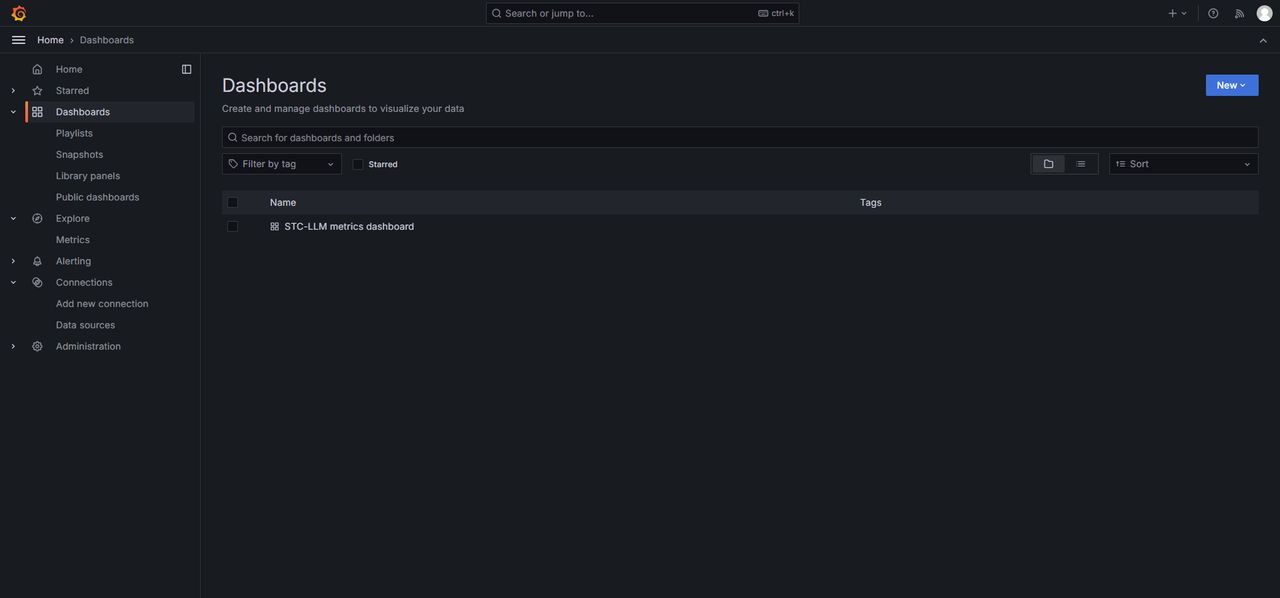
在Dashboards页面即可看到新添加的STC_LLM Dashboard。
-
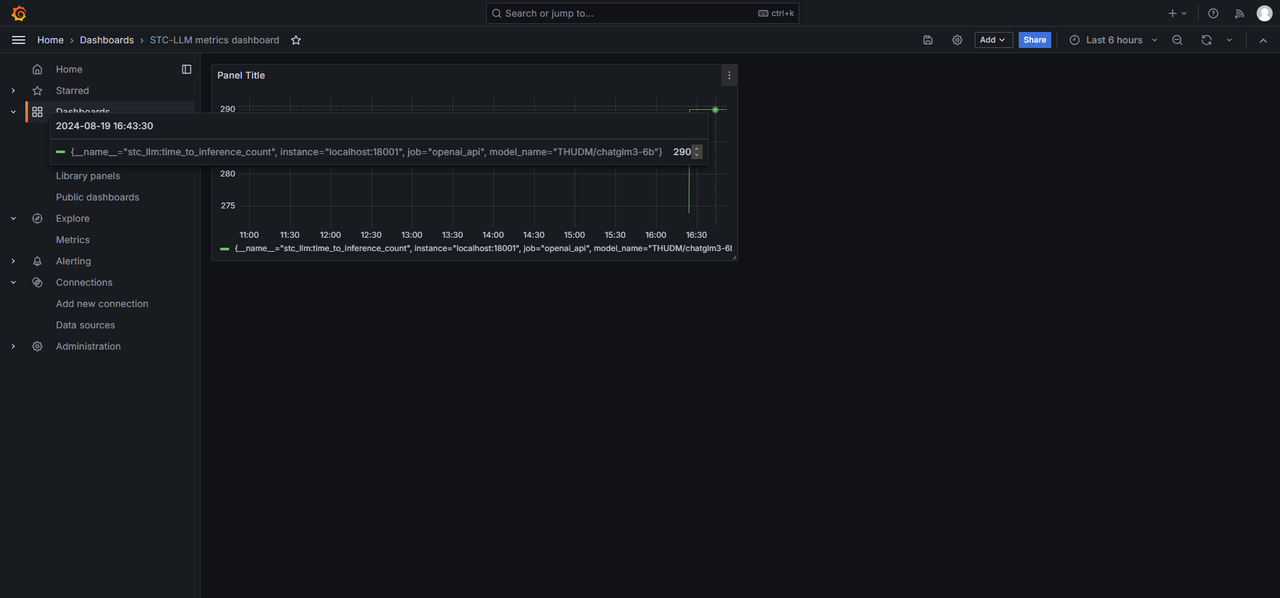
进入STC_LLM Dashboard,即可查看已添加的Panel。
编辑Dashboard中的Panel
-
在左侧导航栏,单击Dashboards。
-
单击STC_LLM Dashboard。
-
在待修改Panel右上角,单击Menu图标 > Edit。
-
按需修改Panel信息,例如将Title修改为推理次数,然后单击Save。
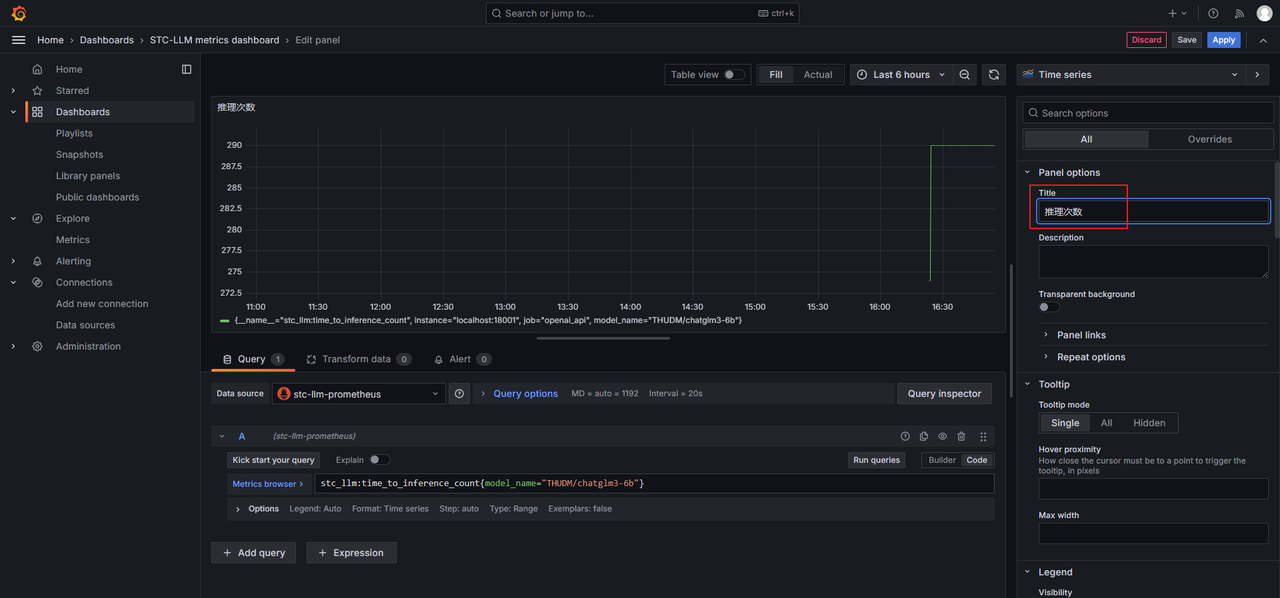
-
按需填写信息,然后单击Save。
为Dashboard添加新Panel
-
在左侧导航栏,单击Dashboards。
-
单击STC_LLM Dashboard。
-
在Dashboard中单击Add > Visualization。
-
添加Panel。切换到Code模式,在输入框中填写Prometheus expression,以监控THUDM/chatglm3-6b模型的prompt处理吞吐和generation处理吞吐为例,分别填写
stc_llm:avg_prompt_throughput_toks_per_s{model_name="THUDM/chatglm3-6b"}和stc_llm:avg_generation_throughput_toks_per_s{model_name="THUDM/chatglm3-6b"},单击Run queries查看效果,然后单击Save。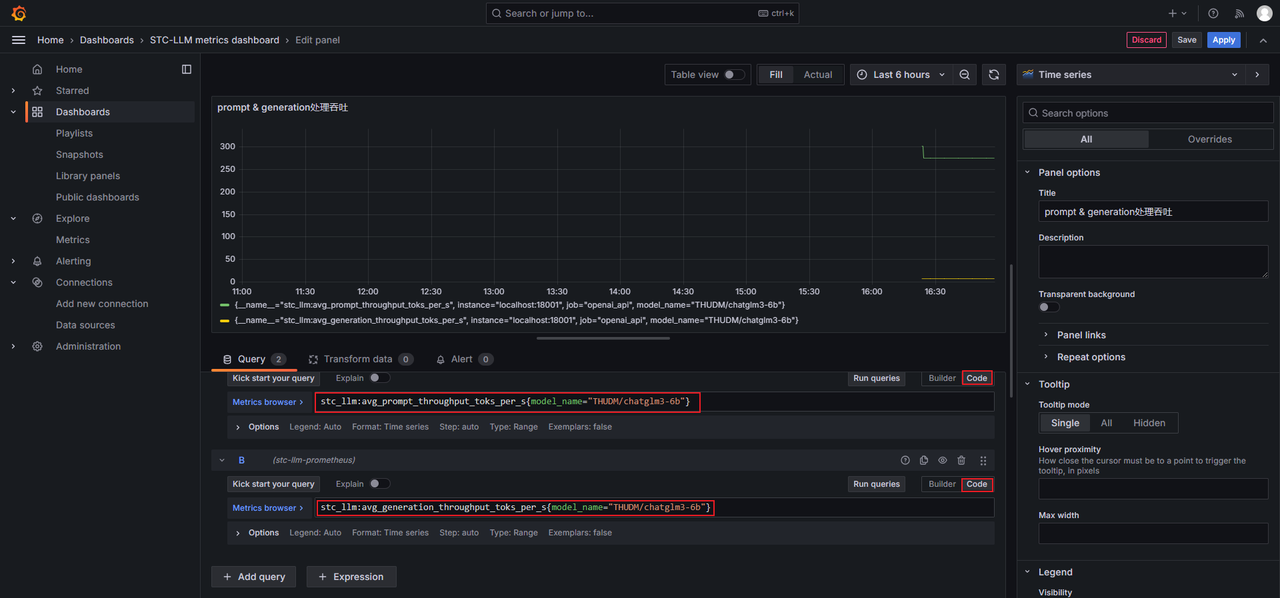
-
按要求填入信息,然后单击Save。
-
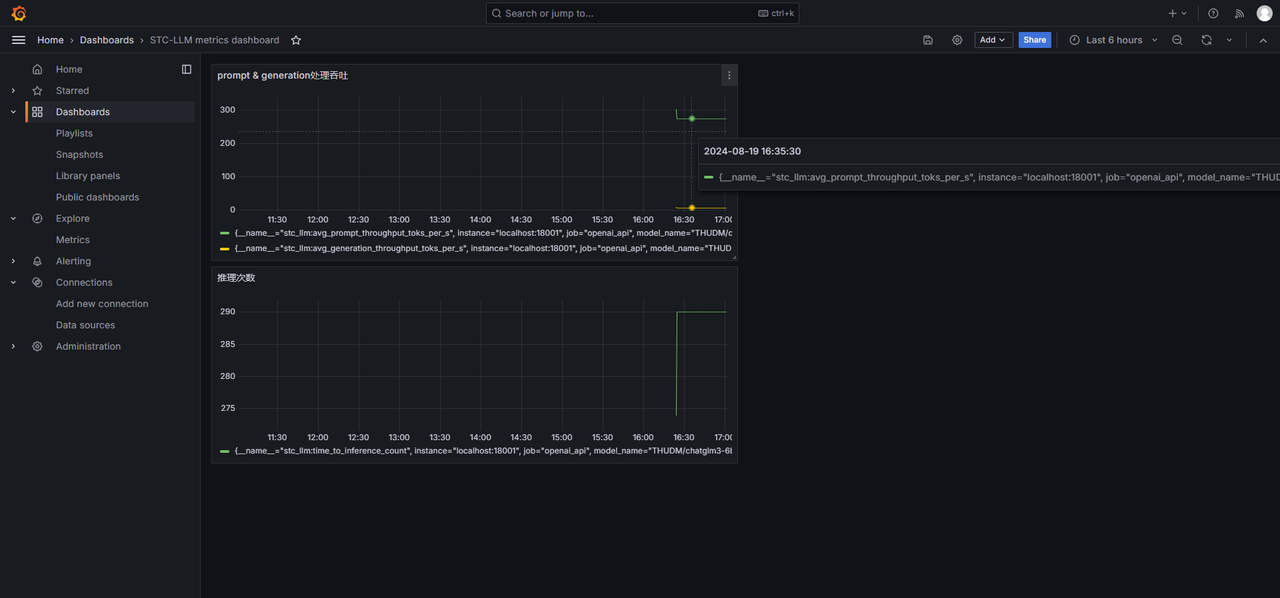
进入进入STC_LLM Dashboard,即可查看展示效果。
生成量化系数
SNC量化工具是基于英特尔的Neural Compressor构建,支持PyTorch大模型量化。Neural Compressor是一个开源的Python库,它支持在主流深度学习框架上应用流行的模型压缩技术,包括量化、剪枝(稀疏性)、蒸馏和神经架构搜索。SNC量化工具支持仅使用CPU进行模型量化。
说明:若有ONNX小模型量化需求,可选择使用SNQ模型量化工具,详情可参见MLTC使用指南。
以Qwen2-7B-Instruct为例演示执行步骤:
-
准备好数据集和模型文件。
-
从HuggingFace等渠道获取Qwen2-7B-Instruct的文件,包括模型文件、权重文件、分词器文件、词表等,并复制到目标服务器。
-
将准备好的数据集复制到目标服务器。
-
-
配置YAML文件。
# 用于拉平激活值与权重的超参数列表
alpha_list: [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
# 数据集位置路径
data_path: "./ceval-exam/val"
# 模型位置路径
model_path : "qwen2-7b-instruct"
#每个数据集子集取多少个数据进行量化
calib_size : 1
# 运行设备,支持CPU和GPU,取值分别为cpu和cuda。
device : "cpu"
# 层数
layers: 28
# attention中有同一输入的linear层名,可以在model.safetensors.index.json中查看,
qkv: ["model.layers.{}.self_attn.q_proj", "model.layers.{}.self_attn.k_proj", "model.layers.{}.self_attn.v_proj"]
# MLP中有同一输入的linear层名
up_gate: ["model.layers.{}.mlp.up_proj", "model.layers.{}.mlp.gate_proj"]
# 保存scale路径,这里需要完整的绝对路径,路径中不可使用‘~’
scale_path: "/root/snc/qwen2_7b_zwt"Qwen2-7B-Instruct模型的层数、qkv和up_gate对应值可以模型的配置文件中查询。
-
layers对应的是模型层数。
-
qkv对应的是attention中有同一输入的linear层名。这些名称是基于
model.safetensors.index.json文件中的节点名称进行转换的。转换过程包括将节点名称中的层编号替换为占位符{},并省略掉o_proj、down_proj、bias、weight等后缀。例如,如果原始节点名称是model.layers.0.self_attn.k_proj.bias,那么在qkv参数中对应的名称就会是model.layers.{}.self_attn.k_proj。 -
up_gate对应的是MLP中有同一输入的linear层名,但不包括down_proj组件。这个名称是根据
model.safetensors.index.json文件中的节点名称转换而来的。转换规则是将节点名称中的层编号替换为占位符{},并移除名称中的weight部分。例如,如果原始节点名称是model.layers.0.mlp.gate_proj.weight,那么up_gate对应的名称将变为model.layers.{}.mlp.gate_proj。
-
-
设置环境变量,使用SQEX设置YAML文件的存放目录。路径必须为绝对路径。
$ export SQEX=/root/snc/sqex.yaml -
启动量化工具脚本。
$ run_quant_no_eval在设置的scale路径下会生成对应超参数的所有候选的量化缩放系数。文件名由
sq+超参数组合,sq是smooth quant的简称。smooth quant是一种拉平激活值来减少精度损失的算法。$ cd /root/snc/qwen2_7b_zwt
$ tree
.
├── sq_0.1
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.2
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.3
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.4
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.5
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.6
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.7
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
├── sq_0.8
│ ├── act_scale_mlp_up_gate_v_w.npy
│ ├── act_scale_mlp_up_gate_w.npy
│ ├── act_scale_qkv_v_w.npy
│ └── act_scale_qkv_w.npy
└── sq_0.9
├── act_scale_mlp_up_gate_v_w.npy
├── act_scale_mlp_up_gate_w.npy
├── act_scale_qkv_v_w.npy
└── act_scale_qkv_w.npy其中文件名后缀为
_v_w的文件中存放着对应超参数的激活层的smooth_quant系数,_w的文件中存放着对应超参数的每层pertensor系数。 -
后续可参考本地验证模型章节中的示例,对同一个模型应用不同的量化系数分析精度,从中选出精度最优的量化缩放系数。将scale目录下的量化系数文件放模型配置中original_weight_dir参数指定的目录下,同时quant_type配置设为
w8a8。
本地验证模型
我们支持手写大模型和MLTC编译大模型,您可先在本地部署验证模型。
手写大模型
以chatglm3-6b为例演示部署手写大模型步骤:
-
设置环境变量。
$ export RISCV=/usr/local/hpe -
从HuggingFace等渠道获取chatglm3-6b的文件,包括模型文件、权重文件、分词器文件、词表等,并复制到目标服务器。
-
编写Python脚本部署并验证模型。脚本示例中主要包括以下步骤:
-
准备模型配置,支持的配置项请参见模型配置章节。
-
调用
AsyncGeneration接口部署模型。 -
发送messages验证LLM的对话效果。
$ cat test_chatglm3-6b.py
import asyncio
from stc_llm_dnn.runtime import AsyncGeneration
async def print_stream(gen, model, gen_name, prompt):
async for task in gen:
print("[{}] prompt = {}, gen = {}".format(gen_name, prompt, model.decode_token_ids(task.gen_tokens)))
async def test_async_generation():
# 配置信息
config = {
"model_name": "THUDM/chatglm3-6b", # 模型名称
"devices": [0, 1], # 使用的 npu id 列表
"tok_dir": "./chatglm3-6b", # tokenizer 目录
"original_weight_dir": "./chatglm3-6b", # 原始权重路径
"weight_dir": "chatglm2-6b-2npu-dataset", # 转换后权重路径
"max_tasks": 256,
"custom_parameters": True,
"quant_type": "fp16",
"compress_factor": 1,
}
# 创建 generation
generation = AsyncGeneration(config)
# 运行测试
messages = [
{"role": "system", "content": "你是资深的技术支持专家,可以为用户提供软硬件产品的技术支持,解答用户使用产品时的疑问。"},
{"role": "user", "content": "你好,你是谁啊?"},
]
task = await generation.create_task(messages=messages, temperature=0.5, top_p=0.2, top_k=20, max_output_len=256)
gen = generation.generate_stream(task)
user_task = asyncio.create_task(print_stream(gen, generation.model, f"gen", "你好"))
await user_task
await generation.shutdown()
if __name__ == "__main__":
asyncio.run(test_async_generation())
$ python3 test_chatglm3-6b.py
# 忽略部分回显
---------------------------- Model Info Begin ----------------------------
model name: THUDM/chatglm3-6b
npus: [0, 1]
total slot number: 157053
slot number per segment: 256
total segment number: 613
bytes per slot: 14336
temporary cpp dir: /home/superadmin/.cache/stc_llm_dnn/THUDM/chatglm3-6b
tokenizer dir: ./chatglm3-6b
weight dir: chatglm2-6b-2npu-dataset
embedding on host: False
output on host: False
dma preload: True
max sequence length: 8192
compress_factor: 1
quant_type: fp16
---------------------------- Model Info End ----------------------------
# 忽略部分回显
[gen] prompt = 你好, gen =
你好,我是资深技术支持专家,很高兴为您提供技术支持。请问有什么软硬件产品需要我帮助您解答疑问吗?
-
MLTC编译大模型
-
设置环境变量。
$ export RISCV=/usr/local/hpe -
从HuggingFace等渠道获取Qwen2-7B-Instruct的文件,包括包括模型文件、权重文件、分词器文件、词表等,并复制到目标服务器。
-
编写Python脚本部署并验证模型。脚本示例中主要包括以下步骤:
-
准备模型配置,支持的配置项请参见模型配置章节。
-
调用
AsyncGeneration接口部署模型。 -
发送messages验证LLM的对话效果。
$ cat test_qwen2-7b-instruct.py
import asyncio
from stc_llm_mltc.runtime import AsyncGeneration
async def test_run():
config = {
"model_name": "Qwen/Qwen2-7B-Instruct",
"devices": [0, 1],
"tok_dir": "/model/qwen2-7b-instruct/",
"mltc_weight_dir": "/model/qwen2-7b-instruct-weight/qwen2-7b-32heads-mask-28layers",
}
prompt = "你是一个写作小助手,请帮忙写一篇描述江南春天长度不少于1024个token的小作文,要求其中必须涉及到描述朦胧的烟雨,蜿蜒的石板小路等景物,同时既要描写出阳光明媚、风和日丽的场景,也要描述出烟雨绵绵、云气氤氲的场景。然后文章中需要包含排比、比喻、对偶、拟人等修辞手法,必要时可以引用一些符合文章主题语境的古诗词中的句子以增加文采。"
generation = AsyncGeneration(config)
task = await generation.create_task(prompt=prompt, max_output_len=5)
async for _ in generation.generate_stream(task):
toks = task.gen_tokens[task.return_offset :]
task.return_offset += len(toks)
if len(toks) == 0:
continue
text = generation.tokenizer.decode(toks)
print(text, end=" ", flush=True)
asyncio.run(test_run())
$ python3 test_qwen2-7b-instruct.py
# 忽略部分回显
To enable the following instructions: AVX2 FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
江南的春天,如同一位羞涩的少女,轻启朱唇,吐露着温柔的气息。她以一种难以言喻的美,缓缓铺展开一幅幅细腻的画卷,让人心醉神迷。在这片土地上,春天的长度仿佛被时间的笔触拉长,每一刻都充满了诗意与生机。
烟雨是江南春天的魂魄,它轻柔地拂过每一寸土地,为大地披上了一层薄薄的轻纱。那烟雨,如同细丝般缠绕在古老的石板小路上,蜿蜒曲折,仿佛是大自然的笔触,勾勒出一幅幅水墨画。雨滴落在青石板上,发出清脆的响声,如同古琴的低吟,悠扬而深邃。这烟雨,是江南春天的序曲,它以一种朦胧而神秘的方式,唤醒了沉睡的大地,让万物在湿润中苏醒。
阳光明媚的日子,江南的春天则展现出另一番景象。阳光如同金色的丝线,穿透云层,洒在大地上,给万物披上了一层金色的外衣。微风轻拂,带着花香与泥土的芬芳,让人感到心旷神怡。在这温暖的阳光下,小溪潺潺,柳树轻摇,仿佛在诉说着春天的故事。这阳光,是江南春天的主旋律,它以一种明亮而温暖的方式,照亮了大地,让世界充满了生机与活力。
在这片土地上,春天的美是多维度的,既有烟雨的朦胧,也有阳光的明媚。它们交织在一起,如同一幅动人的画卷,让人沉醉其中。正如唐代诗人杜甫所言:“好雨知时节,当春乃发生。随风潜入夜,润物细无声。”这正是江南春天的写照,它在不经意间,以一种润物细无声的方式,将美与希望播撒在大地上。
江南的春天,是一首诗,是一幅画,更是一段旅程。在这段旅程中,每一处景致都充满了诗意与哲思,让人在欣赏之余,也能感受到生命的美好与希望。春天的江南,以其独特的魅力,吸引着无数人前来探寻,感受那份属于春天的温柔与力量。 <|im_end|> -
模型配置
| 配置项 | 是否必填 | 数据类型 | 描述 |
|---|---|---|---|
| model_name | 是 | str | 待部署模型的名称,建议与HuggingFace等渠道中的名称保持一致。 |
| devices | 是 | list | 模型推理时占用NPU设备的ID列表,STC_LLM会根据NPU设备的数量将原始权重自动切分为匹配的份数。 |
| tok_dir | 是 | str | 加载模型的分词器(tokenizer)文件的路径。 |
| original_weight_dir | 否 | str | 加载模型的原始权重文件的路径。如果您没有在目标服务器上转换过权重,则至少需要从原始权重转换一次,这时original_weight_dir为必填项。 |
| weight_dir | 否 | str | 从原始权重转换后可以在NPU设备上使用的权重的路径。 - 如果 weight_dir指向的路径存在权重文件,则使用这些权重。- 如果 weight_dir指向的路径不存在权重文件,则STC_LLM尝试从original_weight_dir获取原始权重进行转换,并将转换后的权重放到weight_dir指向的路径。 |
| mltc_weight_dir | 是 说明:当采用MLTC编译方式时为必填。 | str | 采用MLTC编译方式的权重路径。 |
| mltc_ht_file | 否 | str | 采用MLTC编译方式时,vmfb文件存放的路径。 |
| compile_args | 否 | str | 采用MLTC编译方式时传入的编译参数,具体编译参数可参见Python API中的MLTC API。 |
| max_tasks | 否 | int | 支持同时执行的最大task数量,每个task分配一个stream完成一轮对话。默认值为256。 |
| custom_parameters | 否 | bool | - True:允许task自定义temperature、top_p、top_k、logprobs、top_logprobs。 - False:默认值。禁止task自定义temperature、top_p、top_k、logprobs、top_logprobs。 |
| temperature | 否 | float | 超参数之一,控制生成输出的随机性,值越低保证更多的确定性,值越高引入更多的随机性。需要将custom_parameters配置为True才可以修改,默认值为0.5,数值范围为[0.0, 2.0]。 |
| top_p | 否 | float | 超参数之一,在生成输出抽样时排除累积概率低于该值的token。需要将custom_parameters配置为True才可以修改,默认值为0.2,数值范围为(0.0, 1.0]。 |
| top_k | 否 | int | 超参数之一,在生成输出抽样时只在概率top k个token中进行。需要将custom_parameters配置为True才可以修改,默认值为20,数值范围为[1, 词表长度]。 |
| quant_type | 否 | str | 指定是否通过量化节省内存空间。 - fp16:默认值,不启用压缩。 - w8a8:启用量化。 - w8a16:启用压缩。 |
| compress_factor | 否 | int | 压缩倍数,仅在quant_type为w8a16时生效,支持的压缩倍数包括128、64、32、16、8、1、-1,压缩倍数越高,能节省的内存空间越多。压缩倍数为-1时对应per-channel方式。 |
问题排查
未设置RISC-V环境变量
-
问题现象:执行脚本示例时报错
RuntimeError("Can't find RISCV environment variable")。 -
解决方式:必须设置RISC-V环境变量。
$ export RISCV=/usr/local/hpe
可用内存不足
-
问题现象:执行脚本示例时报错
run weight convert ... Killed。 -
解决方式:查看可用内存是否足以放下模型、权重等文件。
$ free -h
投机采样示例
-
从HuggingFace等渠道获取Qwen2-7B-Instruct和Qwen2-0.5B-Instruct文件,包括模型文件、权重文件、分词器文件、词表等,并复制到目标服务器。
-
编写Python脚本部署并验证模型。脚本示例中主要包括以下步骤:
-
分别准备大小模型配置,支持的配置项请参见模型配置章节。
-
调用
ManualAsyncGeneration接口部署模型。 -
发送messages验证LLM的对话效果。
$ cat test_speculative_decoding.py
import asyncio
import os
from stc_llm_dnn.runtime import ManualAsyncGeneration
async def print_stream(gen, tokenizer, gen_name, prompt):
async for aa in gen:
print("[{}] prompt = {}, gen = {}".format(gen_name, prompt, tokenizer.decode(aa)))
async def test_async_generation():
# 配置信息
config = {
"model_name": "Qwen/Qwen2-7B-Instruct",
"tok_dir": "./qwen2-7b-instruct/Qwen2-7B-Instruct/",
"original_weight_dir": "./qwen2-7b-instruct/Qwen2-7B-Instruct",
"weight_dir": "./qwen2-7b-instruct/Qwen2-7B-Instruct/2npu",
"devices": [0,1],
"engine_dir": "./tmp_engine1",
"embed_on_host": False,
"output_on_host": False,
"slot_number_per_segment": 256,
"max_output_len": 25600,
"max_tasks": 256,
"custom_parameters": True,
}
async_generation = ManualAsyncGeneration(config)
assistant_config = {
"model_name": "Qwen/Qwen2-0.5B-Instruct",
"tok_dir": "./qwen2-0.5b-instruct-weight/Qwen2-0.5B-Instruct/",
"original_weight_dir": "./qwen2-0.5b-instruct/Qwen2-0.5B-Instruct",
"weight_dir": "./qwen2-0.5b-instruct/Qwen2-0.5B-Instruct/1npu",
"devices": [2],
"engine_dir": "./tmp_engine2",
"embed_on_host": False,
"output_on_host": False,
"slot_number_per_segment": 256,
"max_output_len": 25600,
"max_tasks": 256,
"custom_parameters": True
}
assistant_generation = ManualAsyncGeneration(assistant_config)
messages_easy_test = [
{"role": "user", "content": "介绍一下自己"},
]
user_tasks = []
for i in range(1):
task_id, gen = await async_generation.generate(
messages = messages_easy_test,
temperature=0.5,
top_p=0.2,
top_k=1,
max_output_len=1024,
assistant_generation=assistant_generation,
assistant_len = 3,
)
user_task = asyncio.create_task(print_stream(gen, async_generation.tokenizer, f"gen{i}", messages_easy_test))
user_tasks.append(user_task)
for user_task in user_tasks:
await user_task
await async_generation.shutdown()
if __name__ == "__main__":
asyncio.run(test_async_generation())
$ python3 test_chatglm3-6b.py
---------------------------- Model Info Begin ----------------------------
model name: Qwen/Qwen2-7B-Instruct
npus: [0, 1]
total slot number: 122082
slot number per segment: 256
total segment number: 476
bytes per slot: 14336
temporary cpp dir: ./tmp_engine1
weight dir: ./qwen2-7b-instruct/Qwen2-7B-Instruct/2npu
embedding on host: False
output on host: False
dma preload: True
max sequence length: 131072
compress_factor: 1
quant_type: fp16
---------------------------- Model Info End ----------------------------
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
---------------------------- Model Info Begin ----------------------------
model name: Qwen/Qwen2-0.5B-Instruct
npus: [2]
total slot number: 488260
slot number per segment: 256
total segment number: 1907
bytes per slot: 6144
temporary cpp dir: ./tmp_engine2
weight dir: ./qwen2-0.5b-instruct/Qwen2-0.5B-Instruct/1npu
embedding on host: False
output on host: False
dma preload: True
max sequence length: 32768
compress_factor: 1
quant_type: fp16
---------------------------- Model Info End ----------------------------
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen =
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 你好!
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 我是一个
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 大模型,
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 全名叫
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 通义千问
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 。
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 作为一个AI助手,
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 我的
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 主要
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 功能是
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 帮助用户
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 解答问题、提供
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 信息、
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 进行
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 对话
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 等。我被
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 训练
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 了
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 在
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 各种
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 主题上提供
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 知识和
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 见解,包括但不限于
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 科技、
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 文化、历史、
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 教育、生活
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 等领域。
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 无论
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 你需要
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 学习新知识、
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 完成
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 某个任务,还是
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 只是想
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 聊天
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 解闷,我
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 都会
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 尽力提供帮助。
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 请随时
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 向我提问,
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 我会尽力
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 给出
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 准确
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 、有用
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 的回答。
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 如果你有任何
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 需要
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 或者
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 好奇的问题,欢迎
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 随时
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen = 告诉我!
[gen0] prompt = [{'role': 'user', 'content': '介绍一下自己'}], gen =
-
问题排查
可用内存不足
-
问题现象:执行脚本示例时报错
Bus error。 -
解决方式:使用
free -h查看可用内存是否足以放下模型、权重等文件。在转换权重时还会创建副本,因此需要配备尽量大的内存,也可直接使用weight_dir设置转换后的权重。