希姆计算TensorTurbo使用说明
版本历史
| 版本 | 作者 | 日期 | 说明 |
|---|---|---|---|
| V1.4.0 | 希姆计算 | 2022-04-29 | - 整篇编辑优化。 - 基本概念单独成篇。 - 补充量化参数说明。 - 更新支持自动图优化的模型。 - 更新手动图调度示意图和示例。 |
| V1.3.0 | 希姆计算 | 2022-03-31 | 更新编译模型章节内容。 支持的OP列表单独成篇。 |
| V1.2.0 | 希姆计算 | 2022-03-01 | 新增支持logical_not、not_equal、less_equal算子。 |
| V1.2.0.RC1 | 希姆计算 | 2022-02-24 | 初始对外版本。 |
TensorTurbo概述
TensorTurbo是基于TVM二次开发的AI编译器,用于将主流框架下的预训练模型编译为STCP920上可执行文件。
在使用TensorTurbo时,您只需要导入模型并按需设置编译参数。TensorTurbo会自动将不同框架下的模型转换为统一的TensorTurbo IR Module,最终得到可执行的二进制文件,简化推理过程。在编译过程中会进行定制性优化,例如通过子图划分、子图并发调度、子图内循环优化、子图内向量化等手段提高硬件资源的利用率,提升模型在STCP920上的推理性能。
说明:希姆计算软硬件产品相关的基本概念,请参见希姆计算基本概念。
TensorTurbo优势
简洁的编译接口,方便您快速编译来自主流框架的模型。
自动的图优化和算子优化,最大限度提升模型在STCP920上运行的性能。
灵活的手动图调度接口,进一步满足自行优化的需求。
安装TensorTurbo
TensorTurbo依赖HPE和Python,我们提供.whl文件形式的TensorTurbo安装包,详细的安装步骤,请参见希姆计算STCP920快速安装指南。
说明:如果需要进行容器化部署,请联系希姆计算的销售人员获取Docker image或Dockerfile。
编译模型
编译流程
编译模型时,支持直接导入基于TensorFlow、PyTorch、MXNet、ONNX、Keras框架的模型以及模型的TVM Relay IR。使用TensorTurbo编译模型时包括以下步骤:
导入模型,不同格式的模型文件会转换为统一的TensorTurbo IR Module。
获取、修改模型信息。
启动编译,支持指定丰富的配置参数。
TensorTurbo为上述步骤提供了Python接口。以ResNet50 V2、模型框架TensorFlow(.pb文件)为例,使用TensorTurbo编译模型输出二进制文件的示例代码如下:
# 加载Python接口相关的模块
import tensorturbo
import tb
# 减少tf warning log的输出
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '3'
if __name__ == '__main__':
inputs = ["input_tensor"]
outputs = ["softmax_tensor_fp16"]
model_path = './resnet-50_v2.pb'
out_path = './resnet-50_v2.stcobj'
# 导入模型
resnet50_v2 = tensorturbo.model.from_tensorflow(model_path, inputs, outputs)
# 获取、修改模型信息
print(resnet50_v2.get_input_info())
print(resnet50_v2.get_output_info())
resnet50_v2.set_input_shape({"input_tensor": [16, 224, 224, 3]})
# Case1:编译模型(指定自行实现的手动图调度方案)
resnet50_v2.compile(
output_file=out_path,
schedule=tb.kernel.schedule.resnet50_schedule,
required_pass=["FuseConvAddBnRelu"]
)
# Case2:编译模型(schedule=None,默认使用自动图优化方案)
resnet50_v2.compile(
output_file=out_path,
schedule=None,
required_pass=[]
)
导入模型接口
导入TensorFlow模型(.pb文件)
接口描述:导入TensorFlow模型(.pb文件)并转换为统一的TensorTurbo IR Module。
接口定义:
tensorturbo.model.from_tensorflow(pb_path, inputs=None, outputs=None)
参数说明:
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| pb_path | str | 是 | TensorFlow模型(.pb文件)的路径。 |
| inputs | list(str) | 否 | 需要导入模型的一部分时,指定输入节点的名称列表。如果不设置本参数,则默认使用整个模型的输入节点。 |
| outputs | list(str) | 否 | 需要导入模型的一部分时,指定输出节点的名称列表。如果不设置本参数,则默认使用整个模型的输出节点。 |
返回值:
tensorturbo.model.Model实例调用示例:
# 指定TensorFlow模型的输入和输出 inputs = ["input_tensor"] outputs = ["softmax_tensor_fp16"] # 指定.pb文件的路径 model_path = "/path/to/resnet-50_v2.pb" # 导入模型 resnet50_v2 = tensorturbo.model.from_tensorflow(model_path, inputs, outputs)
导入ONNX模型(.onnx文件)
接口描述:导入ONNX模型(.onnx文件)并转换为统一的TensorTurbo IR Module。
接口定义:
tensorturbo.model.from_onnx(path, shape=None)
参数说明:
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| path | str | 是 | ONNX模型(.onnx文件)的路径。 |
| shape | dict{str: list(int)} | 否 | 输入tensor的shape信息。如果模型中已有输入shape,可以不指定本参数;如果模型中没有输入Shape,则必须指定本参数。 |
返回值:
tensorturbo.model.Model实例调用示例:
model = tensorturbo.model.from_onnx("/path/to/model.onnx")
导入MXNet模型(文件名前缀)
接口描述:导入MXNet模型(文件名前缀)并转换为统一的TensorTurbo IR Module。
接口定义:
tensorturbo.model.from_mxnet(prefix, epoch, shape=None)
参数说明:
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| prefix | str | 是 | MXNet模型文件的前缀,同时导入前缀对应的.json、.params等多个文件。 |
| epoch | int | 是 | epoch数量,用来匹配对应的.params文件。 |
| shape | dict{str: list(int)} | 否 | 输入tensor的shape信息。如果模型中已有输入shape,可以不指定本参数;如果模型中没有输入Shape,则必须指定本参数。 |
返回值:
tensorturbo.model.Model实例调用示例:
model = tensorturbo.model.from_mxnet("model", 10)
导入Keras模型(.h5文件)
接口描述:导入Keras模型(.h5文件)并转换为统一的TensorTurbo IR Module。
接口定义:
tensorturbo.model.from_keras(path, shape=None)
参数说明:
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| path | str | 是 | Keras模型(.h5文件)的路径。 |
| shape | dict{str: list(int)} | 否 | 输入tensor的shape信息。如果模型中已有输入shape,可以不指定本参数;如果模型中没有输入Shape,则必须指定本参数。 |
返回值:
tensorturbo.model.Model实例调用示例:
model = tensorturbo.model.from_keras("/path/to/model.h5")
导入模型的TVM Relay IR(.relay文件)
接口描述:导入模型的TVM Relay IR(.relay文件)。
接口定义:
tensorturbo.model.from_relay(relay_file, **args)
参数说明:
| 名称 | 类型 | 是否必选 | 描述 |
|---|---|---|---|
| path | str | 是 | 模型的TVM Relay IR(.relay文件)的路径。 |
| **args | dict | 否 | 其他模型参数。例如指定BATCH=8,则导入过程中Relay文本文件中出现的所有BATCH将会被替换为8。 |
返回值:
tensorturbo.model.Model实例调用示例:
model = tensorturbo.model.from_relay("/path/to/model.relay", BATCH=8)
管理模型信息接口
获取模型输入数据的信息
接口描述:导入模型生成对应的实例后,您可以调用
get_input_info查看输入数据的信息。接口定义:
tensorturbo.model.Model.get_input_info()
参数说明:
无
返回值:
dict: {str: {"shape" : list(int), "dtype", str}}
调用示例:
# 打印输入数据的信息 print(resnet50_v2.get_input_info()) # 打印结果 {"input_tensor": {"shape": [16, 224, 224, 3], "dtype": "float32"}}
获取模型输出数据的信息
接口描述:导入模型生成对应的实例后,您可以调用
get_output_info查看输出数据的信息。接口定义:
tensorturbo.model.Model.get_output_info()
参数说明:
无
返回值:
dict: {str: {"shape" : list(int), "dtype", str}}
调用示例:
# 打印输出数据的信息 print(resnet50_v2.get_output_info()) # 打印结果 {'softmax_tensor_fp16': {'shape': [16, 1001], 'dtype': 'float16'}}
修改模型输入数据的信息
接口描述:导入模型生成对应的实例后,您可以调用
set_input_shape更改输入数据的信息,例如更改batch size。编译器会根据新的信息重新推导整个模型的静态类型,用于更改batch size。接口定义:
tensorturbo.model.Model.set_input_shape(input_shape)
参数说明
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| input_shape | dict:{str: list(int)} | 是 | 指定每个输入的shape。 |
返回值
无
调用示例
resnet50_v2.set_input_shape({"input_tensor": [16, 224, 224, 3]})
启动编译接口
接口说明
接口描述:导入模型并按需调整输入数据后,即可启动编译,编译完成后得到包含Runtime Module的二进制文件(文件名后缀为.stcobj),您可以继续调用相关的接口调试该二进制文件。
接口定义:
tensorturbo.model.compile(output_file, kernel="NPUKernel", schedule=tb.relay.graph_schedule.AutoSchedule, **config)
参数说明
| 名称 | 类型 | 是否必选 | 说明 |
|---|---|---|---|
| output_file | str | 是 | 指定输出.stcobj文件的路径。 |
| kernel | str | 否 | 指定核函数类型,目前仅支持NPUKernel。= |
| schedule | function | 否 | 图层调度函数。如果指定手动图调度函数,则使用对应的手动调度方案;如果不指定本参数,则使用基于启发式算法的自动图优化方案,您也可以通过配置参数指定自动图优化的级别。 |
| **config | dict | 否 | 配置参数,方便您根据模型特点和自身需求控制编译动作。 |
返回值
TensorTurbo的Module
调用示例
# 目前tb的schedule里提供resnet50_schedule和bert_schedule的手动图调度方案。 # 如果不设置,则默认使用自动图优化方案,此时应required_pass=[]。 out_path = './resnet-50_v2.stcobj' resnet50_v2.compile( output_file=out_path, kernel="NPUKernel", schedule=tb.kernel.schedule.resnet50_schedule, required_pass=["FuseConvAddBnRelu"], )
配置参数(**config)
compile接口支持指定丰富的配置参数,您可以根据模型特点和自身需求进行配置,例如是否dump文件、是否启用某些Pass、是否做量化等。
说明:Pass相关概念和配置的详细介绍,请参见tvm Pass Infrastructure。
| 名称 | 类型 | 默认值 | 说明 |
|---|---|---|---|
| ncore | int | 8 | 参与计算的NPU核数,取值范围为{1, 2, 4, 8} 。建议采用默认值8,核数变少可能造成性能下降或者运行不稳定。 |
| graph_schedule_level | int | 3 | 自动图优化的级别,仅在schedule取值为None时生效,取值范围为{0, 1, 2 , 3, 4}。数值越大,优化级别越高,理论性能越好。各级别的含义如下: - 0:算子库加速。 - 1:尽量使数据常驻LLB。 - 2:尽量使数据常驻L1。 - 3:进行调整计算顺序、算子拆分、算子合并等操作,基于启发式算法尽量得到最优计算顺序并使数据常驻L1。 |
| dump_file | str | None | 如果指定了文件名,则将编译模型时生成的C++代码保存为.cc文件。 |
| graph_dump_file | str | None | 如果指定了文件名,则将编译模型时图层调度后生成的中间代码保存为.relay文件。 |
| required_pass | list(str) | None | 手动启用的Pass列表,建议采用默认值。 |
| disabled_pass | list(str) | None | 手动关闭的Pass列表,建议采用默认值。 |
| unpack_graph_ops | bool | True | 是否展开粗粒度算子,例如layer_norm、gelu。 |
| fifo | bool | False | 是否生成FIFO模式的Kernel函数。 |
| dmaadd_sch | bool | True | 是否启用DMA add语句调度。 |
| insn_schedule | bool | True | 是否启用NPU指令调度。 |
| post_insn_schedule | bool | True | 是否启用存储分配后的指令调度。 |
| dma_load_unroll | int | 100 | 展开包含DMA load的循环。 |
| csrw_elim | bool | True | 是否消除冗余的csrw指令。 |
| quant_config | dict | None | 模型量化相关的参数,将模型量化为INT8可以加速推理过程,但会损失精度。如果不指定量化参数则不做量化,详细的量化参数说明,请参见量化参数(quant_config )章节。 |
量化参数(quant_config)
需要设置的量化参数和获取scale的方式有关:
基于模型和量化参数计算scale:设置
cpu_target、calibrate_mode、calibrat``ion``_set参数,由TensorTurbo自动计算出input_scale和weight_``scale。
| 名称 | 类型 | 说明 |
|---|---|---|
| cpu_target | str | 请根据主机的CPU类型填写,默认为llvm。您也可以为扩展功能自行约定取值,例如为支持AVX指令集的CPU约定启用向量化指令的取值。 |
| calibrate_mode | str | 指定量化时的校准模式,提高性能的同时尽量减少精度损失,默认为percentile。支持以下取值:- percentile:基于百分比校准input,保留一定比例中心的数据分布范围,剔除极端数据,然后再计算scale。- kl_divergence:基于KL散度校准input,对比量化前后结果的差异程度,取差异最小的结果对应的数据分布范围,然后再计算scale。 |
| calibrate_set | list(dict) | 用于量化的校准数据集,即从全量数据集中选取的一部分代表性样本。格式为[{"input_name": input}],其中input_name为模型输入Tensor的名称,input为校准数据。 |
手动指定scale:设置
preset_scale参数即可,手动指定input_scale和weight_scale。
| 名称 | 类型 | 说明 |
|---|---|---|
| preset_scale | list(list) | 手动预设量化层的scale。格式为{"layer_name":[input_scale, weight_scale]},其中layer_name为量化层名称,input_scale为输入数据的预设scale,weight_scale为权重数据的预设scale。 |
说明:详细的量化方式和流程介绍,请参见希姆计算量化说明。
调试模型
编译模型得到.stcobj文件后,您可以使用调试接口运行模型,评估运行效果。示例如下:
# stc run
graph_exec = tb.kernel.Executor.load_from_stcobj("resnet-50_v2.stcobj")
input_data_stc = {"input_1_0" : input_data["input_1_0"].astype("float16")}
np.save("input_1_0.npy", input_data["input_1_0"].astype("float16"))
graph_exec.set_input(input_data_stc)
stc_out = graph_exec()[0]
print("=============== stc out ====================")
print(stc_out)
说明:希姆计算提供了stc_op工具,用于将编译得到的.stcobj文件封装为算子并集成到后端(目前支持TensorFlow),使主流AI框架直接支持STCP920的推理。具体使用方法,请参见希姆计算stc_op使用说明。
图优化
我们提供了图优化功能提高计算图的局部性,更高效地利用高速缓存。简单来说,您可以通过图优化功能在整个网络上发掘算子间重用L1/LLB上数据的机会,实现在计算过程中数据常驻L1/LLB,从而提高计算效率,同时避免在L1/LLB和DDR之间频繁搬运数据,也降低了对LLB、DDR带宽的需求。
图优化在模型编译阶段进行,模型导入为图层后、图层Lower到算子层前会进行一系列优化动作,图优化则是其中一环。在调用compile时可以通过schedule参数指定图优化方案,我们提供了不同级别的自动图优化方案,您也可以指定自己设计的手动图调度方案。
自动图优化
自动图优化方案分为以下级别:
0:算子库加速。
1:尽量使数据常驻LLB。
2:尽量使数据常驻L1。
3:进行调整计算顺序、算子拆分、算子合并等操作,基于启发式算法尽量得到最优计算顺序并使数据常驻L1。
TensorTurbo支持自动图优化的模型列表如下,这些模型自动图优化的性能与手动图调度基本一致。
CV场景:resnet50、resnet34、resnet101、mobilenet、densenet、resnet50_v1.5。
NLP场景:bert-base 128、bert-base 256、bert-base 512、bert-large、XLNet、albert、video-bert。
推荐场景:wide and deep、deepfm、dlrm、dssm、mmoe、dlrm_1M。
说明:一般来说,在有较多自定义实现的模型上,自动图优化往往达不到NPU的最佳性能。如果您有进一步优化计算图提升性能的需求,可以自行设计手动图调度方案。
手动图调度
对比
以ResNet50为例,假设处理16张224 × 224图片,供参考的调度策略如下:
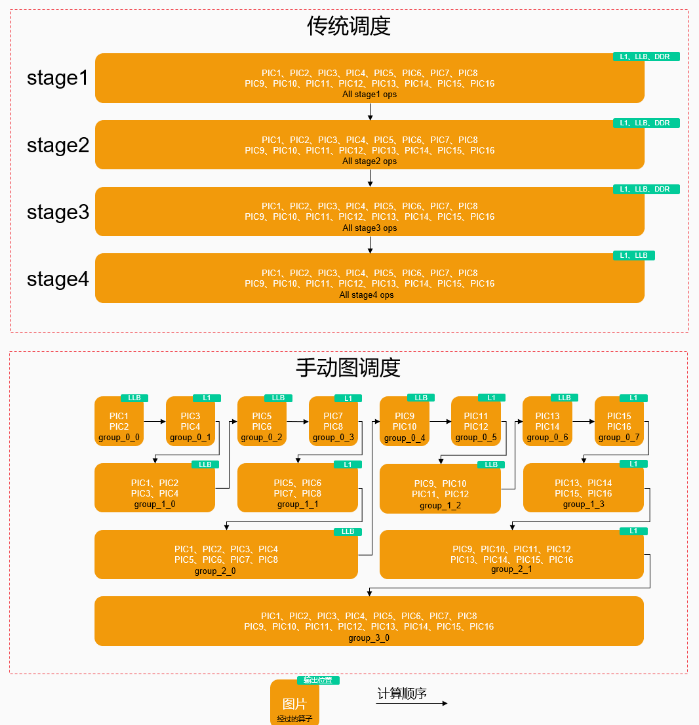
传统调度以算子为单位,需要每个算子都处理完所有16张图片后才能执行后续的计算。此时中间结果包含了16张图片的数据,超出L1/LLB的容量,只能溢出缓存到DDR上。
将input划分为多个batch分批计算,并结合各Group对应的内存占用情况推导计算顺序。按调整后的计算顺序,处理完部分input后即可走到下一个算子,避免了在output size较大的阶段包含所有16张图片的数据,从而常驻在L1/LLB。同时在output size变小且单核可以处理更多图片的阶段,及时汇总中间结果并行计算,缓解时间步骤增多带来的影响,直观感觉是batch数分别为8、4、2、1,在计算过程中不断减少。
调度流程
TensorTurbo提供手动图调度接口,供您自行实现手动图调度方案。一般来说调度流程如下:
索引:索引主函数中的NPU Kernel函数,并索引这些NPU Kernel函数中的算子。 a. NPU Kernel函数索引:索引主函数中的NPU Kernel函数,返回由NPU Kernel函数组成的list,顺序按主函数中DAG后序遍历。NPU Kernel函数用于表示在NPU上执行的计算子图,NPU Kernel函数之外的部分则在CPU上执行。
tb.relay.graph_schedule.GetNPUSubFunctions(function)
b. 算子索引:索引NPU Kernel函数中的算子,返回算子组成的dict,您可以从dict中找到输入function中的每个算子,其中key为算子名称,value为一类算子的list。dict中算子顺序按DAG上的深度优先后序遍历,而非实际的计算顺序。在Relay IR中,只存在DAG表示算子之间的数据依赖关系,并没有实际确定的计算顺序。
说明:IR变换Pass会导致之前索引到的算子失效,在经过优化等可能会改变Relay IR的操作后,需要重新获取新的算子索引。
tb.relay.graph_schedule.ListOps(function)
算子分组:TensorTurbo引入了Group的概念,Group是一个多输入、单输出的DAG,描述整网计算图中一个子图,用于将拆分逻辑、调度参数相同的算子归为一组。分组后各Group作为独立的调度单元,视为一个整体对其内部所有算子进行调度,简化后续的子图拆分等操作。
a. 将指定输入节点、输出节点中间的算子划分为一个Group。
tb.relay.graph_schedule.Group(output, list[input])
b. 对Group进行代码变换,将子图的信息保存到Relay IR上并封装成函数,后续以调用函数的形式执行子图中的计算。
tb.relay.graph_schedule.GroupOps(list[group])
子图拆分:通过合适的拆分维度和拆分因子将子图拆分为更小规模的计算,保证该子图的计算都可以在L1上完成,提高局部性,即输入输出和中间结果的大小都不超过L1的大小限制。子图拆分必须保证Group内所有算子均可以独立完成计算,各部分之间不会相互影响。拆分维度目前仅支持batch,即将输入拆分为几个batch完成计算。
说明:如果内存占用超过L1的容量,需要从Group粒度和拆分因子考虑调整。Group粒度越细,包含的算子越少,可能涉及的计算规模越小;拆分因子越大,每个子图需要计算的数据规模越小。
tb.relay.graph_schedule.SplitGroups(dict{group : split_factor})
算子调度:为计算图中的所有子图以及未分组算子(如有)指定计算顺序、输出数据存储位置、计算绑定核的属性。合理的算子调度可以减少时间步骤和核间数据传输,最大化利用硬件资源。
a. 创建调度规则。存在多个Group时,需要为每个Group指定一个ScheduleInfo结构,形成一个ScheduleInfo list,其中ScheduleInfo的顺序即计算顺序。
tb.relay.graph_schedule.ScheduleInfo(op_or_group, mem_scope, core_bind)
| 参数 | 类型 | 说明 |
|---|---|---|
| mem_scope | IntEnum | Group/算子输出数据的存储位置,可选值:NPUMemScope.DDR、NPUMemScope.LLB、NPUMemScope.L1。 您需要仔细考虑所有计算结果的存储位置,保证中间结果的不会超过L1、LLB的容量限制。如果指定的mem_scope不合理,可能会导致编译器后端存储分配失败。 |
| core_bind | NDArray | group/算子输出数据在L1上的核间分布。例如[[0, 1], [2, 3], [4, 5], [6, 7]],表示拆分为4份,分别输出在[0, 1]、[2, 3]、[4, 5]、[6, 7]核上,所有核的数据汇总起来才构成了完整的结果。 |
在汇总中间结果时可能有多种方案可选,主要的考量因素是尽量减少核间搬运,再进一步考虑到NOC网络的拓扑结构,可以找到一种对NOC网络带宽需求最小的最优分配方案。
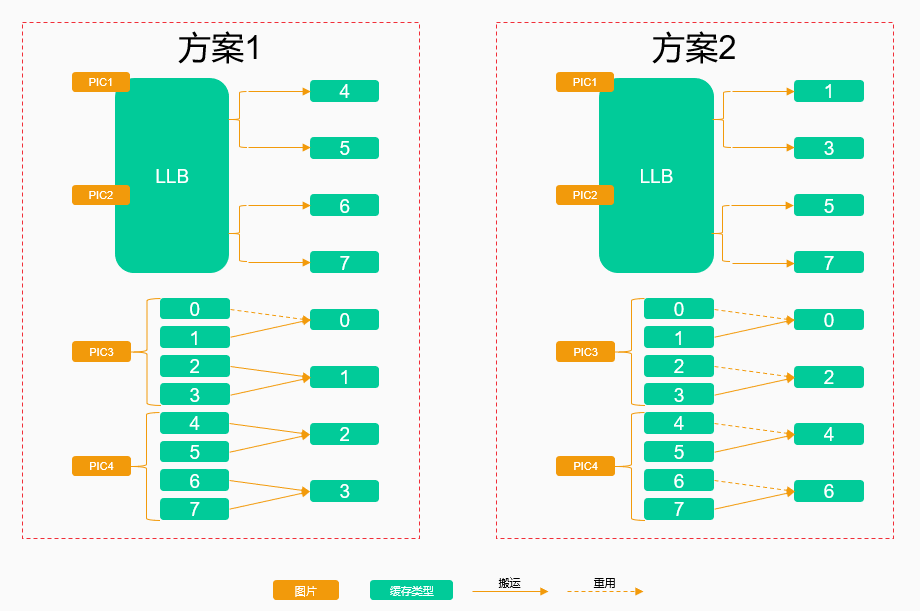
还是以ResNet50为例,假设PIC1、PIC2的中间结果缓存在LLB上,PIC3、PIC4的中间结果缓存在L1上,如果PIC3使用了0 ~ 3核,PIC4使用了4 ~ 7核,示例方案如下:
方案1:按核的index顺序搬移,需要进行7次核间搬运。
案2:重用了4个核上的数据,仅需要4次核间搬运,该方案明显更优。
b. 重新组织IR,将每个Group的ScheduleInfo保存在IR上,用于指导生成后端的算子代码。
tb.relay.graph_schedule.Schedule(list[ScheduleInfo])
调度示例
ResNet50手动图调度方案的完整代码示例如下:
from tvm.target import Target
from ..relay.graph_schedule import (
ScheduleInfo,
Group,
GetNPUSubFunctions,
ListOps,
SplitGroups,
NPUMemScope,
GroupOps,
Schedule,
)
def resnet50_schedule(mod, batch=16):
"""resnet50 schedule"""
# Graph scheduling primitives
func = GetNPUSubFunctions(mod["main"])[0]
ops = ListOps(func)
# Four-stage partition of resnet-50 graph
groups = [
Group([func.params[0]], ops["add"][15]),
Group([ops["add"][15]], ops["add"][31]),
Group([ops["add"][31]], ops["add"][55]),
Group([ops["add"][55]], ops["nn.softmax"][0]),
]
mod = GroupOps(groups)(mod)
# Group split
mod = SplitGroups(
{
groups[0]: batch // 2,
groups[1]: batch // 4,
groups[2]: batch // 8,
groups[3]: batch // 16,
}
)(mod)
# Schedule groups
# Topological order of subgroups
ops = ListOps(GetNPUSubFunctions(mod["main"])[0])
graph_schedule = [
ScheduleInfo(ops["split"][0], NPUMemScope.DDR, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][0], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][1], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][0], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][0], NPUMemScope.LLB, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[0][2], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][3], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][1], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][1], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(ops["concatenate"][2], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[2][0], NPUMemScope.LLB, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[0][4], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][5], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][3], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][2], NPUMemScope.LLB, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[0][6], NPUMemScope.LLB, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(groups[0][7], NPUMemScope.L1, [[0, 1, 2, 3], [4, 5, 6, 7]]),
ScheduleInfo(ops["concatenate"][4], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(groups[1][3], NPUMemScope.L1, [[1, 3], [5, 7], [0, 2], [4, 6]]),
ScheduleInfo(ops["concatenate"][5], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(groups[2][1], NPUMemScope.L1, [3, 7, 2, 6, 1, 5, 0, 4]),
ScheduleInfo(ops["concatenate"][6], NPUMemScope.L1, [7, 6, 5, 4, 3, 2, 1, 0]),
ScheduleInfo(groups[3][0], NPUMemScope.DDR, [7, 6, 5, 4, 3, 2, 1, 0]),
]
with Target("stc_tc"):
mod = Schedule(graph_schedule)(mod)
return mod