STCRP产品简介
HPE
HPE(Heterogeneous Programming Engine)是面向硬件产品的异构编程引擎,包括驱动、运行时、监控调试工具等模块,在CPU+NPU的异构环境中提供了服务器识别NPU以及完成NPU基本操作的能力。
HPE支持通过C++语言扩展接口开发异构程序,如果您有使用Python语言扩展接口开发异构程序的需求,请独立安装HPE-Python。异构程序包括在CPU上运行的主机端程序和在NPU上运行的设备端程序,HPE为开发、编译、运行主机端程序和设备端程序提供了完整的工具链。
HPE的功能架构图如下所示:

其中:
-
Driver:包括了stc-dkms、stc-kernel-common等模块。
-
Runtime:包括了hpert、npurt等模块。
-
SDK和library通过接口、库文件等形式向上提供编程能力。
-
Tools:包括了stc-gdb、stc-prof、stc-vprof、stc-smi等监控工具。
MLTC
MLTC(Multi-Level Tensor Compiler)是基于MLIR研发的端到端深度学习编译器,可以将来自不同框架的AI模型编译为面向希姆计算硬件产品的可执行文件,同时加速AI模型的计算过程,提高系统的健壮性。
MLTC具有以下特性:
-
通过多层IR设计实现逐层下降 ,解决代码生成的复杂性。每次IR层级的转换只专注代码生成的一个局部方面,例如多核执行模型、bufferization、算子逻辑的指令组合等。
-
提供一套算子无关的tiling系统,把一些算子的公共逻辑提升到编译器框架中,减轻算子编程的开发负担,提高系统的健壮性。面向NeuralScale架构编写算子时,不管是手写算子还是compute/schedule的DSL描述,其中大部分代码逻辑是管理多层存储结构和其间的数据传输。
-
性能优化以独立的优化pass形式作用在特定层级的IR上,可以任意打开或关闭,不影响系统健壮性。
-
保持图优化之后的编译器主干流程与算子无关,不存在任何针对特定算子的定制化逻辑。
-
保持图层IR算子的原子性,不包含可以由简单算子组合而成的复杂算子,没有融合算子。
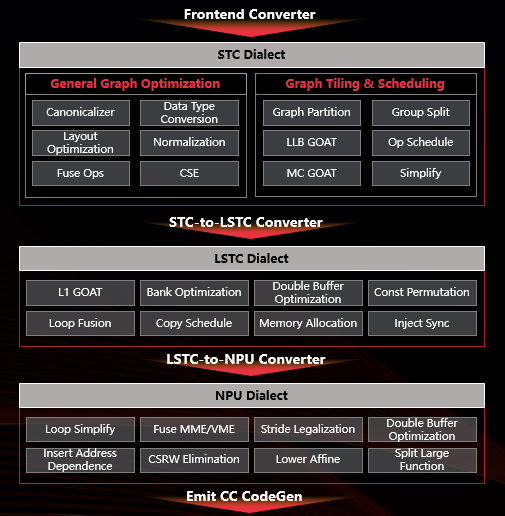
MLTC的系统架构如下图所示:

MLTC的典型编译流程如下图所示:
STC_LLM
主流的开源LLM往往基于HuggingFace的格式,权重保存为bin或者safetensors,为更高效地完成LLM推理任务,我们面向LLM自研了推理框架STC_LLM。STC_LLM在AI编译器、手写算子的基础上对LLM的推理过程进行了封装,您可以方便地导入、替换LLM并完成推理任务,简化了LLM的部署和使用过程。
STC_LLM面向LLM支持以下特性:
-
编译阶段:支持权重转换、量化预处理、Tensor并行处理超大规模的权重等。
-
服务阶段:支持动态batch管理优化端到端吞吐。
-
推理阶段:支持kernel级别的优化、KV Cache优化等。
STC_LLM的系统架构如下图所示:
